Slik laster du ned og installerer NLTK
⚡ Smart oppsummering
Last ned og installer NLTK på Windows, Mac eller Linux ved å installere Python først, deretter tilsettes Natural Language Toolkit gjennom pip eller Anaconda og nedlasting av korpusdatasettene.

Installerer NLTK i Windows
Lær hvordan du konfigurerer NLTK Windows fra ledeteksten. Instruksjonene nedenfor forutsetter Python er ikke installert ennå, så det første trinnet er å installere Python.
Installere Python in Windows
Trinn 1) Åpne lenken https://www.python.org/downloads/, og velg den nyeste Windows slipp.
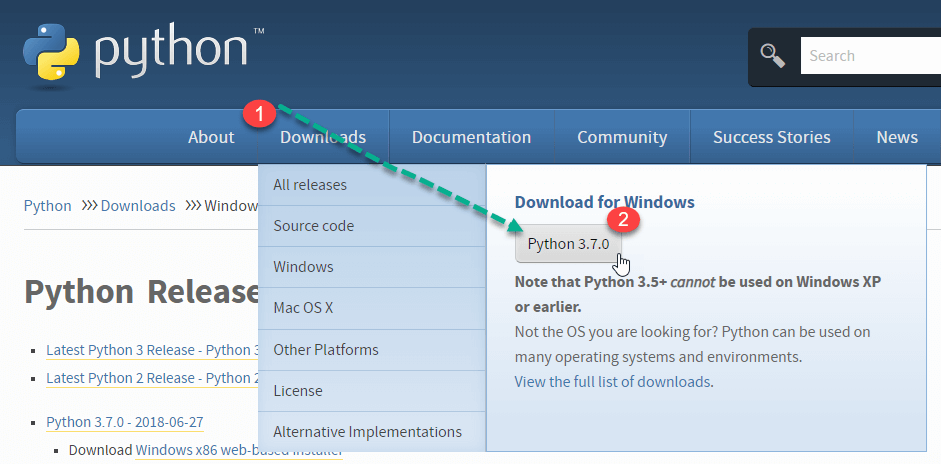
MerknaderFor en eldre versjon, gå til Nedlastinger-fanen for å se alle utgivelser.

Trinn 2) Klikk på den nedlastede installasjonsfilen.

Trinn 3) Velg Tilpass installasjon.
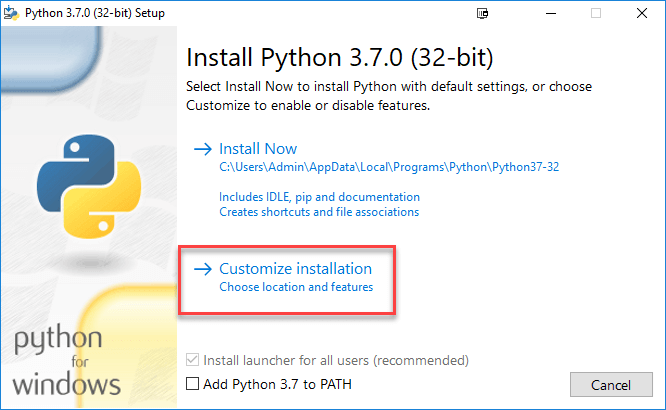
Trinn 4) Klikk på NESTE.

Trinn 5) På neste skjermbilde:
- Velg de avanserte alternativene.
- Oppgi en tilpasset installasjonsplassering. I dette eksemplet er en mappe på C-stasjonen valgt for enklere tilgang.
- Klikk Installer.

Trinn 6) Klikk på Lukk-knappen når installasjonen er fullført.

Trinn 7) Kopier banen til Scripts-mappen.

Trinn 8) på Windows ledetekst:
- Naviger til plasseringen av pip-mappen.
- Skriv inn kommandoen for å installere NLTK:
pip3 install nltk
- Installasjonen skal fullføres.

MERKNADER: For Python 2, bruk kommandoen pip2 install nltk.
Trinn 9) Fra Windows Start-menyen, søk etter og åpne Python Shell.

Trinn 10) Bekreft at installasjonen fungerer ved å kjøre kommandoen nedenfor:
import nltk

Hvis det ikke vises noen feil, er installasjonen fullført.
Installere NLTK i Mac/Linux
Installasjon av NLTK på Mac eller Linux krever Python pakkebehandler pip. Hvis pip ikke er installert, følg instruksjonene nedenfor for å fullføre prosessen.
Trinn 1) Oppdater pakkeindeksen etter typing kommandoen nedenfor:
sudo apt update
Trinn 2) Installer pip for Python 3:
sudo apt install python3-pip
Du kan også installere pip gjennom easy_install:
sudo apt-get install python-setuptools python-dev build-essential
Når easy_install er installert, kjør kommandoen nedenfor for å installere pip:
sudo easy_install pip
Trinn 3) Bruk følgende kommando for å installere NLTK:
sudo pip install -U nltk sudo pip3 install -U nltk
Installerer NLTK gjennom Anaconda
Trinn 1) Installer Anaconda ved å besøke https://www.anaconda.com/products/individual og velge Python versjonen du trenger.

Merk: Se denne opplæringen for detaljerte trinn til Installer Anaconda.
Trinn 2) I Anaconda-ledeteksten:
- Skriv inn kommandoen:
conda install -c anaconda nltk
- RevSe informasjonen for pakkeoppgradering, nedgradering og installasjon, og skriv deretter ja.
- NLTK er lastet ned og installert.

NLTK-datasett
NLTK-modulen leveres med mange datasett som du må laste ned før bruk. Teknisk sett kalles hvert datasett et corpusVanlige eksempler inkluderer stoppord, Gutenberg, framenet_v15, store_grammatikk, brunog ordnett.
Hvordan laste ned alle pakker med NLTK
Trinn 1) Kjør Python tolk in Windows eller Linux.
Trinn 2)
- Skriv inn kommandoene:
import nltk nltk.download ()
- NLTK Downloader-vinduet åpnes. Klikk på Last ned-knappen for å hente datasettet. Denne prosessen tar tid avhengig av internettforbindelsen din.

NOTAT: Du kan endre nedlastingsplasseringen ved å klikke på Fil > Endre nedlastingskatalog.

Trinn 3) For å teste de installerte dataene, bruk følgende kode:
>>> from nltk.corpus import brown >>>brown.words()
['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', …]

Kjøre NLP-skriptet
Denne delen forklarer hvordan et NLP-skript kjører på en lokal PC. Valget av riktig bibliotek avhenger av dine behov. Se den offisielle listen over NLP biblioteker for alternativer som spaCy, gensim og TextBlob.
Hvordan kjøre NLTK-skript
Trinn 1) I favorittkoderedigeringsprogrammet ditt, kopier koden og lagre filen som NLTKsample.py:
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
filterdText=tokenizer.tokenize('Hello Guru99, You have build a very good site and I love visiting your site.')
print(filterdText)

Code Forklaring:
- Målet med dette programmet er å fjerne alle typer tegnsetting fra en gitt tekst. Vi importerte «RegexpTokenizer», en modul av NLTK som fjerner ethvert uttrykk, symbol, tegn eller numerisk verdi du velger.
- Et regulært uttrykk sendes til modulen «RegexpTokenizer».
- Teksten tokeniseres ved hjelp av «tokenize»-metoden, og utdataene lagres i variabelen «filterdText».
- Resultatet skrives ut ved hjelp av «print()».
Trinn 2) I ledeteksten:
- Naviger til stedet der du lagret filen.
- Kjør kommandoen
python NLTKsample.py.

Utgangen er:
['Hallo', 'Guru99', 'Du', 'har', 'bygge', 'en', 'veldig', 'bra', 'sted', 'og', 'jeg', 'elsker', 'besøker', 'din', 'sted']