PyTorch Handleiding
⚡ Slimme samenvatting
PyTorch is het open-source deep learning-framework van Meta, dat naar verwachting in 2026 85 procent van alle AI-onderzoekspapers zal aandrijven. LessDe cursussen behandelen installatie, basisprincipes van het framework, eenvoudige regressietests, beeldclassificatie en de implementatie van AWS SageMaker.

Wat is PyTorch?
PyTorch is een open-source Torch-gebaseerde machine learning-bibliotheek voor natuurlijke taalverwerking met behulp van PythonHet is vergelijkbaar met NumPy, maar met krachtige GPU-ondersteuning. Het biedt dynamische computationele grafieken die je met behulp van autograd.py direct kunt aanpassen.Torch is ook sneller dan sommige andere frameworks. Het werd in 2016 ontwikkeld door de AI Research Group van Facebook.
Weten wat PyTorch biedt een evenwichtig beeld van de sterke en zwakke punten.
PyTorVoordelen en nadelen
Hieronder volgen de voor- en nadelen van Py.Torch:
Voordelen van PyTorch
- Eenvoudige bibliotheek
PyTorDe code van ch is eenvoudig. Het is gemakkelijk te begrijpen en je kunt de bibliotheek direct gebruiken. Kijk bijvoorbeeld eens naar het onderstaande codefragment:
class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.layer = torch.nn.Linear(1, 1) def forward(self, x): x = self.layer(x) return x
Zoals hierboven vermeld, kunt u het netwerkmodel eenvoudig definiëren en kunt u de code snel begrijpen zonder veel training.
- Dynamische computationele grafiek

Afbeeldingbron: Deep Learning verkennen met PyTorch
PyTorch biedt dynamische computationele grafieken (DAG's) aan. Computationele grafieken zijn een manier om wiskundige uitdrukkingen weer te geven in grafiekmodellen of -theorieën, zoals knooppunten en randen. Het knooppunt voert de wiskundige bewerking uit en de rand is een tensor die aan het knooppunt wordt doorgegeven en de uitvoer van het knooppunt in een tensor bevat.
DAG is een grafiek die een willekeurige vorm heeft en bewerkingen kan uitvoeren tussen verschillende invoergrafieken. Elke iteratie wordt een nieuwe grafiek gemaakt. Het is dus mogelijk om dezelfde grafiekstructuur te hebben of een nieuwe grafiek te maken met een andere bewerking, of we kunnen het een dynamische grafiek noemen.
- Betere prestaties
Gemeenschappen en onderzoekers benchmarken en vergelijken raamwerken om te zien welke sneller is. Een GitHub-opslagplaats Benchmark voor Deep Learning Frameworks en GPU's meldde dat PyTorch is sneller dan het andere framework wat betreft het aantal afbeeldingen dat per seconde wordt verwerkt.
Zoals je hieronder kunt zien, de vergelijkingsgrafieken met vgg16 en resnet152


- Native Python
PyTorch is meer op Python gebaseerd. Als je bijvoorbeeld een model wilt trainen, kun je gebruikmaken van native controlestructuren zoals loo.ping En recursieve functies kunnen worden uitgevoerd zonder dat er extra speciale variabelen of sessies nodig zijn. Dit is erg handig voor het trainingsproces.
PyTorch implementeert ook imperatieve programmering en is daardoor aanzienlijk flexibeler. Het is bijvoorbeeld mogelijk om de tensorwaarde midden in een berekeningsproces af te drukken.
Nadelen van PyTorch
PyTorch vereist applicaties van derden voor visualisatie. Het heeft ook een API-server nodig voor productie.
Volgende in deze PyTorIn deze tutorial leren we over het verschil tussen PyTorch en TensorFlow.
PyTorch versus TensorFlow
| Parameter | PyTorch | TensorFlow |
|---|---|---|
| Model definitie | Het model is gedefinieerd in een subklasse en biedt een eenvoudig te gebruiken pakket | Het model is met velen gedefinieerd en u moet de syntaxis begrijpen |
| GPU-ondersteuning | Ja | Ja |
| Grafiektype | Dynamisch | Statisch |
| Tools | Geen visualisatietool | U kunt de visualisatietool Tensorboard gebruiken |
| Gemeenschap | De gemeenschap groeit nog steeds | Grote actieve gemeenschappen |
Met die vergelijking in gedachten is de volgende stap het verkrijgen van Py.Torch draait lokaal of in de cloud.
Py installerenTorch
Linux
Het is eenvoudig te installeren onder Linux. U kunt ervoor kiezen om een virtuele omgeving te gebruiken of deze rechtstreeks met root-toegang te installeren. Typ deze opdracht in de terminal
pip3 install --upgrade torch torchvision
AWS Saliemaker
Sagemaker is een van de platforms in Amazon Webservice dat een krachtige Machine Learning-engine biedt met vooraf geïnstalleerde deep learning-configuraties waarmee datawetenschappers of ontwikkelaars modellen op elke schaal kunnen bouwen, trainen en implementeren.
Open eerst het Amazon Saliemaker console en klik op Notitieboekinstantie maken en vul alle gegevens voor uw notitieboekje in.

Volgende stap, klik op Openen om uw notebookinstantie te starten.

Tenslotte, In JupyterKlik op Nieuw en kies conda_pytorch_p36. Je bent nu klaar om je notebook-instantie met Py te gebruiken.Torch geïnstalleerd.
Volgende in deze PyTorIn deze tutorial leren we over Python.TorBasisprincipes van het CH-framework.
Na de installatie is de API zelf de volgende stap.
PyTorch Framework Basisprincipes
Laten we de basisconcepten van Py leren.Torch voordat we dieper ingaan. PyTorch gebruikt Tensors voor elke variabele, vergelijkbaar met NumPy's ndarray, maar met ondersteuning voor GPU-berekeningen. Hier zullen we het netwerkmodel, de verliesfunctie, Backprop en Optimizer toelichten.
Netwerkmodel
Het netwerk kan worden opgebouwd door de torch.nn in een subklasse te plaatsen. Er zijn 2 hoofdonderdelen,
- Het eerste deel is het definiëren van de parameters en lagen die u gaat gebruiken
- Het tweede deel is de hoofdtaak, het voorwaartse proces genaamd, dat input zal nemen en de output zal voorspellen.
Import torch import torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.conv1 = nn.Conv2d(3, 20, 5) self.conv2 = nn.Conv2d(20, 40, 5) self.fc1 = nn.Linear(320, 10) def forward(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = x.view(-1, 320) x = F.relu(self.fc1(x)) return F.log_softmax(x) net = Model()
Zoals je hierboven kunt zien, maak je een klasse van nn.Module met de naam Model. Het bevat 2 Conv2d-lagen en een lineaire laag. De eerste conv2d-laag heeft een invoer van 3 en de uitvoervorm van 20. De tweede laag heeft een invoer van 20 en produceert een uitvoervorm van 40. De laatste laag is een volledig verbonden laag in de vorm van 320 en produceert een opbrengst van 10.
Het voorwaartse proces zal een invoer van X nemen en deze naar de conv1-laag sturen en de ReLU-functie uitvoeren,
Op dezelfde manier zal het ook de conv2-laag voeden. Daarna wordt de x omgevormd tot (-1, 320) en ingevoerd in de uiteindelijke FC-laag. Voordat u de uitvoer verzendt, gebruikt u de softmax-activeringsfunctie.
Het achterwaartse proces wordt automatisch gedefinieerd door autograd, u hoeft dus alleen het voorwaartse proces te definiëren.
Verliesfunctie
De verliesfunctie wordt gebruikt om te meten hoe goed het voorspellingsmodel de verwachte resultaten kan voorspellen.TorDe torch.nn-module bevat al veel standaard verliesfuncties. Je kunt bijvoorbeeld de Cross-Entropy Loss gebruiken om een multi-class Py-probleem op te lossen.Torch classificatieprobleem. Het is eenvoudig om de verliesfunctie te definiëren en de verliezen te berekenen:
loss_fn = nn.CrossEntropyLoss() #training process loss = loss_fn(out, target)
Met Python is het eenvoudig om je eigen verliesfunctie te berekenen.Torch.
Achtersteun
Om de backpropagatie uit te voeren, roept u eenvoudigweg los.backward() aan. De fout wordt berekend, maar vergeet niet de bestaande gradiënt te wissen met zero_grad()
net.zero_grad() # to clear the existing gradient loss.backward() # to perform backpropragation
Optimizer
De torch.optim biedt algemene optimalisatiealgoritmen. U kunt een optimizer definiëren met een eenvoudige stap:
optimizer = torch.optim.SGD(net.parameters(), lr = 0.01, momentum=0.9)
U moet de netwerkmodelparameters en de leersnelheid doorgeven, zodat bij elke iteratie de parameters na het backprop-proces worden bijgewerkt.
De meest overzichtelijke manier om de API te leren kennen, is aan de hand van een klein, compleet voorbeeld.
Eenvoudige regressie met PyTorch
Laten we eenvoudige regressie met Python leren.Torch voorbeelden:
Stap 1) Ons netwerkmodel creëren
Ons netwerkmodel is een eenvoudige lineaire laag met een invoer- en uitvoervorm van 1.
from __future__ import print_function import torch import torch.nn as nn import torch.nn.functional as F from torch.autograd import Variable class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.layer = torch.nn.Linear(1, 1) def forward(self, x): x = self.layer(x) return x net = Net() print(net)
En de netwerkuitvoer zou er zo uit moeten zien
Net( (hidden): Linear(in_features=1, out_features=1, bias=True) )
Stap 2) Testgegevens
Voordat u aan het trainingsproces begint, moet u onze gegevens kennen. Je maakt een willekeurige functie om ons model te testen. Y = x3 zonde(x)+ 3x+0.8 rand(100)
# Visualize our data import matplotlib.pyplot as plt import numpy as np x = np.random.rand(100) y = np.sin(x) * np.power(x,3) + 3*x + np.random.rand(100)*0.8 plt.scatter(x, y) plt.show()
Hier is het spreidingsdiagram van onze functie:

Voordat je met het trainingsproces begint, moet je de NumPy-array converteren naar variabelen die door NumPy worden ondersteund. Torch en autograd zoals weergegeven in de onderstaande PyTorch regressievoorbeeld.
# convert numpy array to tensor in shape of input size x = torch.from_numpy(x.reshape(-1,1)).float() y = torch.from_numpy(y.reshape(-1,1)).float() print(x, y)
Stap 3) Optimizer en verlies
Vervolgens moet u de Optimizer en de Loss Function voor ons trainingsproces definiëren.
# Define Optimizer and Loss Function optimizer = torch.optim.SGD(net.parameters(), lr=0.2) loss_func = torch.nn.MSELoss()
Stap 4) Trainen
Laten we nu beginnen met ons trainingsproces. Met een tijdperk van 250 itereert u onze gegevens om de beste waarde voor onze hyperparameters te vinden.
inputs = Variable(x) outputs = Variable(y) for i in range(250): prediction = net(inputs) loss = loss_func(prediction, outputs) optimizer.zero_grad() loss.backward() optimizer.step() if i % 10 == 0: # plot and show learning process plt.cla() plt.scatter(x.data.numpy(), y.data.numpy()) plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2) plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 10, 'color': 'red'}) plt.pause(0.1) plt.show()
Stap 5) Resultaat
Zoals je hieronder kunt zien, heb je Py succesvol uitgevoerd.Torch regressie met een neuraal netwerk. Bij elke iteratie wordt de rode lijn in de grafiek bijgewerkt en verandert de positie ervan om de data beter te volgen. Maar in deze afbeelding wordt alleen het eindresultaat weergegeven, zoals in de onderstaande Py-code.Torch voorbeeld:

Regressie is een opwarmertje; beeldclassificatie traint de deep-learning-capaciteiten van Py.Torch.
Voorbeeld van beeldclassificatie met PyTorch
Een van de populaire methoden om de basisprincipes van te leren diepgaand leren is met de MNIST-dataset. Het is de "Hello World" in deep learning. De dataset bevat handgeschreven getallen van 0 - 9 met in totaal 60,000 trainingssamples en 10,000 test samples die al zijn gelabeld met de grootte van 28×28 pixels.

Stap 1) Verwerk de gegevens voor
In de eerste stap van deze PyTorIn dit voorbeeld van een classificatie laadt u de dataset met behulp van de torchvision-module.
Voordat je met het trainingsproces begint, moet je de gegevens begrijpen. Torchvision laadt de dataset en transformeert de afbeeldingen volgens de vereisten van het netwerk, zoals de vorm en normalisatie.
import torch import torchvision import numpy as np from torchvision import datasets, models, transforms # This is used to transform the images to Tensor and normalize it transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) training = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(training, batch_size=4, shuffle=True, num_workers=2) testing = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform) test_loader = torch.utils.data.DataLoader(testing, batch_size=4, shuffle=False, num_workers=2) classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9') import matplotlib.pyplot as plt import numpy as np #create an iterator for train_loader # get random training images data_iterator = iter(train_loader) images, labels = data_iterator.next() #plot 4 images to visualize the data rows = 2 columns = 2 fig=plt.figure() for i in range(4): fig.add_subplot(rows, columns, i+1) plt.title(classes[labels[i]]) img = images[i] / 2 + 0.5 # this is for unnormalize the image img = torchvision.transforms.ToPILImage()(img) plt.imshow(img) plt.show()
De transformatiefunctie converteert de afbeeldingen naar tensor en normaliseert de waarde. De functie torchvision.transforms.MNIST downloadt de dataset (als deze niet beschikbaar is) in de directory, stelt de dataset indien nodig in voor training en voert het transformatieproces uit.
Om de dataset te visualiseren, gebruikt u de data_iterator om de volgende batch afbeeldingen en labels op te halen. U gebruikt matplot om deze afbeeldingen en het bijbehorende label te plotten. Zoals je hieronder kunt zien zijn onze afbeeldingen en hun labels.
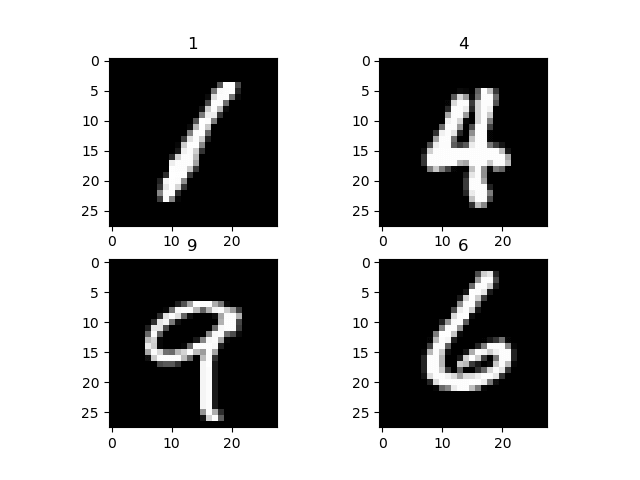
Stap 2) Netwerkmodelconfiguratie
Nu in deze PyTorIn dit voorbeeld ga je een eenvoudig neuraal netwerk maken voor Python.Torch beeldclassificatie.
Hier introduceren we een andere manier om een netwerkmodel in Python te maken.TorHoofdstuk. We zullen nn.Sequential gebruiken om een sequentiemodel te maken in plaats van een subklasse van nn.Module te maken.
import torch.nn as nn # flatten the tensor into class Flatten(nn.Module): def forward(self, input): return input.view(input.size(0), -1) #sequential based model seq_model = nn.Sequential( nn.Conv2d(1, 10, kernel_size=5), nn.MaxPool2d(2), nn.ReLU(), nn.Dropout2d(), nn.Conv2d(10, 20, kernel_size=5), nn.MaxPool2d(2), nn.ReLU(), Flatten(), nn.Linear(320, 50), nn.ReLU(), nn.Linear(50, 10), nn.Softmax(), ) net = seq_model print(net)
Hier is de output van ons netwerkmodel
Sequential( (0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (2): ReLU() (3): Dropout2d(p=0.5) (4): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1)) (5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (6): ReLU() (7): Flatten() (8): Linear(in_features=320, out_features=50, bias=True) (9): ReLU() (10): Linear(in_features=50, out_features=10, bias=True) (11): Softmax() )
Netwerk uitleg
- De volgorde is dat de eerste laag een Conv2D-laag is met een invoervorm van 1 en een uitvoervorm van 10 met een kernelgrootte van 5
- Vervolgens heb je een MaxPool2D-laag
- Een ReLU-activeringsfunctie
- een Dropout-laag om waarden met een lage waarschijnlijkheid te verwijderen.
- Dan een tweede Conv2d met de invoervorm van 10 uit de laatste laag en de uitvoervorm van 20 met een kernelgrootte van 5
- Vervolgens een MaxPool2d-laag
- ReLU-activeringsfunctie.
- Daarna maakt u de tensor plat voordat u deze in de lineaire laag invoert
- Lineaire laag brengt onze uitvoer in kaart op de tweede lineaire laag met softmax-activeringsfunctie
Stap 3) Train het model
Voordat u met het trainingsproces begint, is het vereist om de criterium- en optimalisatiefunctie in te stellen.
Voor het criterium gebruikt u de CrossEntropyLoss. Voor de optimizer gebruikt u de SGD met een leerfrequentie van 0.001 en een momentum van 0.9, zoals weergegeven in de onderstaande Py-code.Torch voorbeeld.
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Het voorwaartse proces neemt de invoervorm aan en geeft deze door aan de eerste conv2d-laag. Vervolgens wordt het in de maxpool2d ingevoerd en uiteindelijk in de ReLU-activeringsfunctie geplaatst. Hetzelfde proces zal plaatsvinden in de tweede conv2d-laag. Daarna wordt de invoer omgevormd tot (-1,320) en ingevoerd in de fc-laag om de uitvoer te voorspellen.
Nu begint u met het trainingsproces. U doorloopt onze dataset 2 keer of met een tijdperk van 2 en drukt het huidige verlies af bij elke batch van 2000.
for epoch in range(2): #set the running loss at each epoch to zero running_loss = 0.0 # we will enumerate the train loader with starting index of 0 # for each iteration (i) and the data (tuple of input and labels) for i, data in enumerate(train_loader, 0): inputs, labels = data # clear the gradient optimizer.zero_grad() #feed the input and acquire the output from network outputs = net(inputs) #calculating the predicted and the expected loss loss = criterion(outputs, labels) #compute the gradient loss.backward() #update the parameters optimizer.step() # print statistics running_loss += loss.item() if i % 1000 == 0: print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 1000)) running_loss = 0.0
Bij elk tijdperk krijgt de enumerator het volgende tupel invoer en bijbehorende labels. Voordat we de invoer aan ons netwerkmodel toevoegen, moeten we de vorige gradiënt wissen. Dit is nodig omdat na het achterwaartse proces (backpropagatieproces) de gradiënt zal worden geaccumuleerd in plaats van vervangen. Vervolgens berekenen we de verliezen op basis van de voorspelde output op basis van de verwachte output. Daarna zullen we een backpropagatie uitvoeren om de gradiënt te berekenen, en ten slotte zullen we de parameters bijwerken.
Hier is de output van het trainingsproces
[1, 1] loss: 0.002 [1, 1001] loss: 2.302 [1, 2001] loss: 2.295 [1, 3001] loss: 2.204 [1, 4001] loss: 1.930 [1, 5001] loss: 1.791 [1, 6001] loss: 1.756 [1, 7001] loss: 1.744 [1, 8001] loss: 1.696 [1, 9001] loss: 1.650 [1, 10001] loss: 1.640 [1, 11001] loss: 1.631 [1, 12001] loss: 1.631 [1, 13001] loss: 1.624 [1, 14001] loss: 1.616 [2, 1] loss: 0.001 [2, 1001] loss: 1.604 [2, 2001] loss: 1.607 [2, 3001] loss: 1.602 [2, 4001] loss: 1.596 [2, 5001] loss: 1.608 [2, 6001] loss: 1.589 [2, 7001] loss: 1.610 [2, 8001] loss: 1.596 [2, 9001] loss: 1.598 [2, 10001] loss: 1.603 [2, 11001] loss: 1.596 [2, 12001] loss: 1.587 [2, 13001] loss: 1.596 [2, 14001] loss: 1.603
Stap 4) Test het model
Nadat u ons model heeft getraind, moet u het testen of evalueren met andere sets afbeeldingen.
We gebruiken een iterator voor de test_loader en deze genereert een batch afbeeldingen en labels die worden doorgegeven aan het getrainde model. De voorspelde uitvoer wordt weergegeven en vergeleken met de verwachte uitvoer.
#make an iterator from test_loader #Get a batch of training images test_iterator = iter(test_loader) images, labels = test_iterator.next() results = net(images) _, predicted = torch.max(results, 1) print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) fig2 = plt.figure() for i in range(4): fig2.add_subplot(rows, columns, i+1) plt.title('truth ' + classes[labels[i]] + ': predict ' + classes[predicted[i]]) img = images[i] / 2 + 0.5 # this is to unnormalize the image img = torchvision.transforms.ToPILImage()(img) plt.imshow(img) plt.show()
