DBMS-normalisatie: 1NF, 2NF, 3NF databasevoorbeeld

Normalisatie in een notendop
Normalisatie is het proces waarbij een database wordt gestructureerd om redundantie te verminderen en de consistentie te verbeteren. Simpel gezegd splitst het grote, rommelige tabellen op in kleinere, overzichtelijke tabellen. Dit zorgt ervoor dat gegevens logisch worden opgeslagen, waardoor databases efficiënt, gemakkelijk te onderhouden en vrij van duplicatie of fouten zijn.
Wat is databasenormalisatie?
Database normalisatie is een databaseontwerptechniek die gegevensredundantie vermindert en ongewenste kenmerken zoals anomalieën bij het invoegen, bijwerken en verwijderen elimineert. Normalisatieregels verdelen grotere tabellen in kleinere tabellen en koppelen deze met behulp van relaties. Het doel van Normalisatie in SQL is om overtollige (repetitieve) gegevens te elimineren en ervoor te zorgen dat gegevens logisch worden opgeslagen.
De uitvinder van de relationeel model Edgar Codd stelde de theorie van normalisatie van gegevens voor met de introductie van de Eerste Normaalvorm, en hij bleef de theorie uitbreiden met de Tweede en Derde Normaalvorm. Later hij sloot zich aan bij Raymond F. Boyce om de theorie van de Boyce-Codd-normaalvorm te ontwikkelen.
Waarom hebben we normalisatie nodig?
Zonder normalisatie worden databases snel inconsistent en redundant. Problemen zoals invoegingsanomalieën (onvolledige gegevens kunnen niet worden toegevoegd), update anomalieën (veranderingen op één plek worden niet overal weerspiegeld), en verwijderingsanomalieën (het verwijderen van gegevens wist per ongeluk waardevolle informatie) komen vaak voor. Normalisatie elimineert deze problemen, waarborgt de data-integriteit, vermindert duplicatie en vereenvoudigt databasebeheer.
Welke typen normaalvormen zijn er in DBMS?
Hier is een lijst met normale formulieren in SQL:
- 1NF (Eerste normale vorm): Zorgt ervoor dat de databasetabel zo is georganiseerd dat elke kolom atomaire (ondeelbare) waarden bevat en elk record uniek is. Dit elimineert herhalende groepen en structureert zo gegevens in tabellen en kolommen.
- 2NF (tweede normaalvorm): Bouwt voort op 1NF door We moeten overtollige gegevens verwijderen uit een tabel die op meerdere rijen wordt toegepast. en plaats ze in aparte tabellen. Het vereist dat alle niet-sleutelattributen volledig functioneel zijn op de primaire sleutel.
- 3NF (derde normale vorm): Breidt 2NF uit door ervoor te zorgen dat alle niet-sleutelattributen niet alleen volledig functioneel zijn op de primaire sleutel, maar ook onafhankelijk van elkaar. Dit elimineert transitieve afhankelijkheid.
- BCNF (Boyce-Codd normale vorm): Een verfijning van 3NF die afwijkingen aanpakt die niet door 3NF worden afgehandeld. Het vereist dat elke determinant een kandidaat-sleutel is, waardoor een nog striktere naleving van de normalisatieregels wordt gegarandeerd.
- 4NF (vierde normaalvorm): Adressen afhankelijkheden met meerdere waarden. Het zorgt ervoor dat er geen meerdere onafhankelijke feiten met meerdere waarden over een entiteit in een record voorkomen.
- 5NF (vijfde normaalvorm): Ook bekend als "Projection-Join Normal Form" (PJNF). Het heeft betrekking op de reconstructie van informatie uit kleinere, anders gerangschikte gegevensstukken.
- 6NF (zesde normaalvorm): Theoretisch en niet op grote schaal geïmplementeerd. Het behandelt temporele gegevens (het omgaan met veranderingen in de loop van de tijd) door tabellen verder te ontbinden om alle niet-tijdelijke redundantie te elimineren.
De theorie van datanormalisatie in MySQL server wordt nog verder ontwikkeld. Er zijn bijvoorbeeld zelfs discussies over 6th Normale vorm. In de meeste praktische toepassingen bereikt normalisatie echter het beste in 3rd Normale vorm. De evolutie van normalisatie in SQL-theorieën wordt hieronder geïllustreerd:
.png)
Databasenormalisatie met voorbeelden
Database Normalisatie voorbeeld kan gemakkelijk worden begrepen met behulp van een case study. Stel dat een videotheek een database bijhoudt van verhuurde films. Zonder enige normalisatie in de database wordt alle informatie in één tabel opgeslagen, zoals hieronder weergegeven. Laten we de normalisatiedatabase begrijpen met een normalisatievoorbeeld met oplossing:

Hier zie je De kolom Films gehuurd heeft meerdere waarden. Laten we nu naar de eerste normaalvormen gaan:
Eerste normale vorm (1NF)
- Elke tabelcel moet één enkele waarde bevatten.
- Elk record moet uniek zijn.
De bovenstaande tabel in 1NF-
1NF-voorbeeld

Laten we, voordat we verder gaan, een paar dingen begrijpen:
Wat is een SLEUTEL in SQL
A SLEUTEL in SQL is een waarde die wordt gebruikt om records in een tabel uniek te identificeren. Een SQL-sleutel is een enkele kolom of combinatie van meerdere kolommen die wordt gebruikt om rijen of tupels in de tabel uniek te identificeren. SQL Key wordt gebruikt om dubbele informatie te identificeren en helpt ook een relatie tot stand te brengen tussen meerdere tabellen in de database.
Opmerking: Kolommen in een tabel die NIET worden gebruikt om een record uniek te identificeren, worden niet-sleutelkolommen genoemd.
Wat is een primaire sleutel?

Een primaire waarde is een waarde uit één kolom die wordt gebruikt om een databaserecord op unieke wijze te identificeren.
Het heeft de volgende kenmerken
- A hoofdsleutel Kan niet nul zijn
- Een primaire sleutelwaarde moet uniek zijn
- De primaire sleutelwaarden mogen zelden worden gewijzigd
- Bij het invoegen van een nieuw record moet de primaire sleutel een waarde krijgen.
Wat is samengestelde sleutel?
Een samengestelde sleutel is een primaire sleutel die bestaat uit meerdere kolommen en wordt gebruikt om een record uniek te identificeren
In onze database hebben we twee mensen met dezelfde naam Robert Phil, maar ze wonen op verschillende plaatsen.

Daarom hebben we zowel de volledige naam als het adres nodig om een record uniek te identificeren. Dat is een samengestelde sleutel.
Laten we naar de tweede normaalvorm 2NF gaan
Tweede normale vorm (2NF)
- Regel 1 - Wees in 1NF
- Regel 2 - Primaire sleutel met één kolom die functioneel niet afhankelijk is van een subset van de kandidaat-sleutelrelatie
Het is duidelijk dat we niet verder kunnen gaan met het maken van onze eenvoudige database in 2nd Normalisatieformulier, tenzij we de bovenstaande tabel verdelen.


We hebben onze 1NF-tabel in twee tabellen verdeeld, namelijk Tabel 1 en Tabel 2. Tabel 1 bevat ledeninformatie. Tabel 2 bevat informatie over gehuurde films.
We hebben een nieuwe kolom geïntroduceerd met de naam Membership_id, die de primaire sleutel is voor tabel 1. Records kunnen uniek worden geïdentificeerd in Tabel 1 met behulp van lidmaatschaps-ID
Database – Vreemde sleutel
In Tabel 2 is Membership_ID de externe sleutel


Foreign Key verwijst naar de primaire sleutel van een andere tabel! Het helpt uw tabellen met elkaar te verbinden
- Een externe sleutel kan een andere naam hebben dan de primaire sleutel
- Het zorgt ervoor dat rijen in de ene tabel overeenkomstige rijen in een andere tabel hebben
- In tegenstelling tot de primaire sleutel hoeven ze niet uniek te zijn. Meestal zijn ze dat niet
- Externe sleutels kunnen nul zijn, ook al zijn primaire sleutels dat niet

Waarom heb je een externe sleutel nodig?
Stel dat een beginneling een record in tabel B invoegt, zoals

U kunt alleen waarden in uw refererende sleutel invoegen die bestaan in de unieke sleutel in de bovenliggende tabel. Dit helpt bij referentiële integriteit.
Het bovenstaande probleem kan worden opgelost door het lidmaatschaps-ID uit Tabel2 te declareren als de externe sleutel van het lidmaatschaps-ID uit Tabel1
Als iemand nu een waarde in het lidmaatschaps-ID-veld probeert in te voegen die niet bestaat in de bovenliggende tabel, wordt er een foutmelding weergegeven!
Wat zijn transitieve functionele afhankelijkheden?
Een transitief functionele afhankelijkheid is bij het wijzigen van een niet-sleutelkolom, kan ertoe leiden dat een van de andere niet-sleutelkolommen verandert
Bekijk tabel 1. Als u de niet-sleutelkolom Volledige naam wijzigt, kan de aanhef veranderen.

Laten we naar 3NF gaan
Derde normale vorm (3NF)
- Regel 1 - Wees in 2NF
- Regel 2- Heeft geen transitieve functionele afhankelijkheden
Om onze 2NF-tabel naar 3NF te verplaatsen, moeten we onze tabel opnieuw verdelen.
3NF-voorbeeld
Hieronder ziet u een 3NF-voorbeeld in de SQL-database:


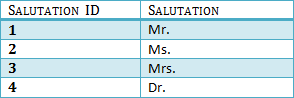
We hebben onze tafels opnieuw verdeeld en een nieuwe tafel gemaakt met daarop de Aanhef.
Er zijn geen transitieve functionele afhankelijkheden en daarom is onze tabel in 3NF
In Tabel 3 is de Aanhef-ID de primaire sleutel, en in Tabel 1 is de Aanhef-ID vreemd aan de primaire sleutel in Tabel 3
Nu is ons kleine voorbeeld op een niveau dat niet verder kan worden ontbonden om hogere normale vormtypen van normalisatie in DBMS te bereiken. In feite is het al in hogere normalisatievormen. Afzonderlijke inspanningen om naar volgende niveaus van normalisatie van gegevens te gaan, zijn normaal gesproken nodig in complexe databases. We zullen echter in het kort de volgende niveaus van normalisatie in DBMS bespreken in het volgende.
Boyce-Codd normale vorm (BCNF)
Zelfs als een database in 3rd Normale vorm, toch zouden er afwijkingen optreden als er meer dan één is Kandidaat Key.
Soms wordt BCNF ook wel genoemd 3.5 Normale vorm.
Vierde normale vorm (4NF)
Als geen enkele databasetabelinstantie twee of meer onafhankelijke en meerwaardige gegevens bevat die de relevante entiteit beschrijven, dan is deze in 4th Normale vorm.
Vijfde normale vorm (5NF)
Er staat een tafel in 5th Normale vorm alleen als deze zich in 4NF bevindt en deze niet kan worden ontleed in een aantal kleinere tabellen zonder gegevensverlies.
Zesde normale vorm (6NF) voorgesteld
6th De normale vorm is niet gestandaardiseerd, maar wordt al enige tijd besproken door database-experts. Hopelijk hebben we een duidelijke en gestandaardiseerde definitie voor 6th Normale vorm in de nabije toekomst…
Wat zijn de voordelen van normalisatie?
- Verbeter de consistentie van gegevens: Normalisatie zorgt ervoor dat elk stukje gegevens op slechts één plek wordt opgeslagen, waardoor de kans op inconsistente gegevens wordt verkleind. Wanneer gegevens worden bijgewerkt, hoeven deze slechts op één plaats te worden bijgewerkt, waardoor consistentie wordt gegarandeerd.
- Verminder gegevensredundantie: Normalisatie helpt dubbele gegevens te elimineren door deze in meerdere, gerelateerde tabellen te verdelen. Dit kan opslagruimte besparen en de database ook efficiënter maken.
- Verbeter de queryprestaties: Genormaliseerde databases zijn vaak gemakkelijker te doorzoeken. Omdat gegevens logisch zijn georganiseerd, kunnen query's worden geoptimaliseerd om sneller te worden uitgevoerd.
- Maak gegevens betekenisvoller: Normalisatie omvat groeperingping Gegevens op een logische en intuïtieve manier presenteren. Dit maakt de database gemakkelijker te begrijpen en te gebruiken, vooral voor mensen die de database niet hebben ontworpen.
- Verklein de kans op afwijkingen: Afwijkingen zijn problemen die kunnen optreden bij het toevoegen, bijwerken of verwijderen van gegevens. Normalisatie kan de kans op deze afwijkingen verkleinen door ervoor te zorgen dat gegevens logisch zijn georganiseerd.
Wat zijn de nadelen van normalisatie?
- Verhoogde complexiteit: Normalisatie kan leiden tot complexe relaties. Een groot aantal tabellen met vreemde sleutels kan moeilijk te beheren zijn, wat leidt tot verwarring.
- Verminderde flexibiliteit: Vanwege de strikte regels voor normalisatie is er mogelijk minder flexibiliteit bij het opslaan van gegevens die niet aan deze regels voldoen.
- Verhoogde opslagvereisten: Hoewel normalisatie de redundantie vermindert, kan het nodig zijn om meer opslagruimte toe te wijzen om plaats te bieden aan de extra tabellen en indices.
- Prestaties overheadkosten: Het samenvoegen van meerdere tabellen kan kostbaar zijn in termen van prestaties. Hoe meer genormaliseerd de gegevens, hoe meer joins er nodig zijn, wat de ophaaltijden van gegevens kan vertragen.
- Verlies van gegevenscontext: Normalisatie splitst gegevens op in afzonderlijke tabellen, wat kan leiden tot verlies van bedrijfscontext. Het onderzoeken van gerelateerde tabellen is noodzakelijk om de context van een gegeven te begrijpen.
- Behoefte aan deskundige kennis: Het implementeren van een genormaliseerde database vereist een diepgaand begrip van de gegevens, de relaties tussen gegevens en de normalisatieregels. Dit vereist specialistische kennis en kan tijdrovend zijn.
Dat is alles voor SQL-normalisatie!!!
Veelgestelde vragen
Samenvatting
- Ontwerpen van databases is van cruciaal belang voor de succesvolle implementatie van een databasebeheersysteem dat voldoet aan de gegevensvereisten van een bedrijfssysteem.
- Normalisatie in DBMS is een proces dat helpt databasesystemen te produceren die kosteneffectief zijn en betere beveiligingsmodellen hebben.
- Functionele afhankelijkheden zijn een zeer belangrijk onderdeel van het normalisatieproces van gegevens
- De meeste databasesystemen zijn genormaliseerde databases tot aan de derde normaalvorm in DBMS.
- Een primaire sleutel identificeert op unieke wijze een record in een tabel en kan niet nul zijn
- Een externe sleutel helpt bij het verbinden van de tabel en verwijst naar een primaire sleutel