SQLite 쿼리: 선택, 위치, LIMIT, OFFSET, 개수, 그룹화 기준
⚡ 스마트 요약
SQLite 쿼리는 SELECT, FROM, WHERE, GROUP BY, ORDER BY 및 LIMIT 절을 사용하여 데이터를 검색하고 필터링합니다. 이러한 절을 연산자, 집계 함수, 하위 쿼리 및 집합 연산과 결합하면 모든 데이터베이스에서 레코드를 읽고, 형식을 지정하고, 요약할 수 있습니다. SQLite 데이터 베이스.

아래 섹션에서는 SELECT 및 FROM 절을 사용한 데이터 읽기, WHERE 절 및 관련 연산자를 사용한 행 필터링, 결과 정렬 및 제한, 집계 함수, GROUP BY 및 HAVING 절, 서브쿼리, 집합 연산, NULL 처리, CASE 표현식 및 공통 테이블 표현식에 대해 자세히 설명합니다.
쓰기 SQL 쿼리 을 확인하십시오. SQLite 데이터베이스를 사용하려면 SELECT, FROM, WHERE, GROUP BY, ORDER BY 및 LIMIT 절의 작동 방식과 사용 방법을 알아야 합니다.
이 튜토리얼에서는 이러한 절을 사용하는 방법과 작성 방법을 배우게 됩니다. SQLite 조항.
Select를 사용하여 데이터 읽기
SELECT 절은 쿼리에 사용하는 기본 문입니다. SQLite 데이터 베이스. SELECT 절에서는 선택할 항목을 명시합니다. 하지만 select 절 이전에 FROM 절을 사용하여 데이터를 선택할 수 있는 위치를 살펴보겠습니다.
FROM 절은 데이터를 어디에서 선택할지 지정하는 데 사용됩니다. from 절에서 데이터를 선택할 하나 이상의 테이블이나 하위 쿼리를 지정할 수 있습니다. 이는 튜토리얼에서 나중에 살펴보겠습니다.
다음 모든 예제에서 sqlite3.exe를 실행하고 샘플 데이터베이스에 대한 연결을 다음과 같이 열어야 합니다.
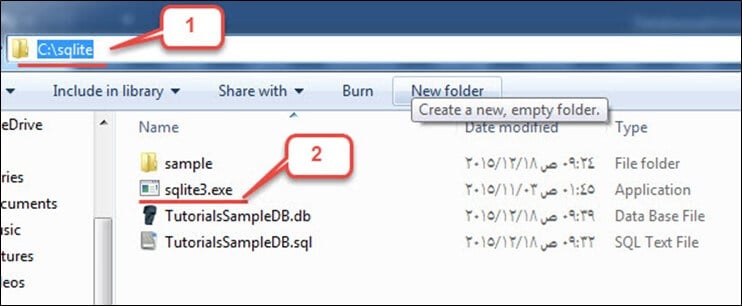
단계 1) 이 단계에서,
내 컴퓨터를 열고 "C:\sqlite" 디렉토리로 이동한 다음 "sqlite3.exe"를 실행하세요.
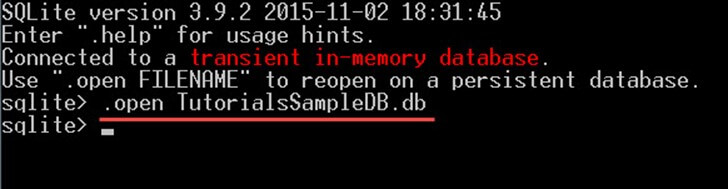
단계 2) 다음 명령어를 사용하여 "TutorialsSampleDB.db" 데이터베이스를 엽니다.
이제 데이터베이스에서 모든 유형의 쿼리를 실행할 준비가 되었습니다.
SELECT 절에서 열 이름만 선택할 수 있는 것이 아니라 선택할 내용을 지정하는 다른 많은 옵션이 있습니다. 다음과 같습니다.
고르다 *
이 명령은 FROM 절에서 참조되는 모든 테이블(또는 하위 쿼리)의 모든 열을 선택합니다. 예를 들어:
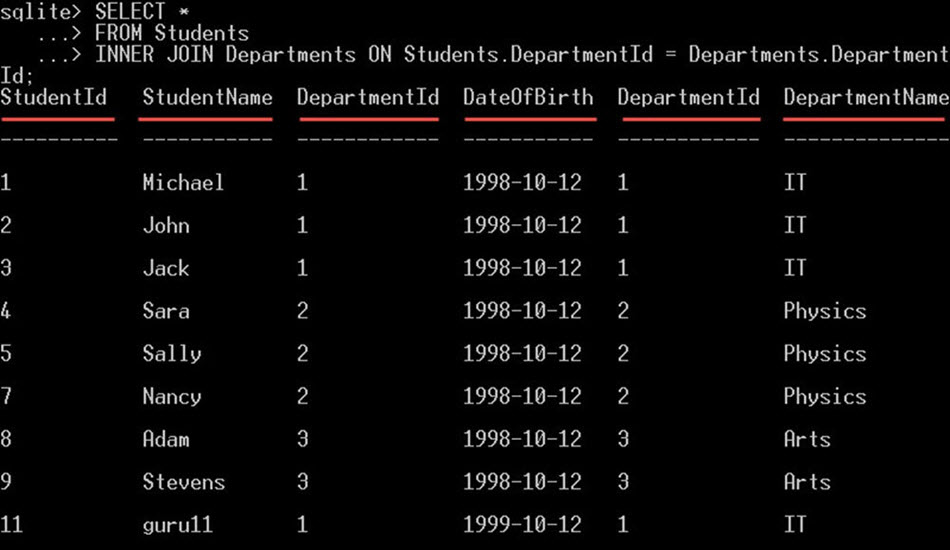
SELECT * FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
그러면 학생 테이블과 부서 테이블 모두에서 모든 열이 선택됩니다.
테이블 이름을 선택하세요.*
그러면 "tablename" 테이블에서만 모든 열이 선택됩니다. 예를 들어:
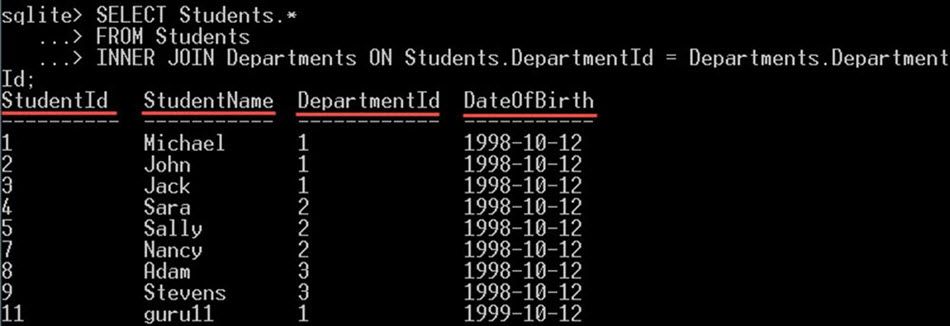
SELECT Students.* FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
그러면 학생 테이블에서만 모든 열이 선택됩니다.
리터럴 값
리터럴 값은 select 문에서 지정할 수 있는 상수 값입니다. 일반적으로 SELECT 절에서 열 이름을 사용하는 것과 같은 방식으로 리터럴 값을 사용할 수 있습니다. 이러한 리터럴 값은 SQL 쿼리에서 반환된 행의 각 행에 대해 표시됩니다.
다음은 선택할 수 있는 다양한 리터럴 값의 몇 가지 예입니다.
- 숫자 리터럴 - 1, 2.55, ... 등과 같은 모든 형식의 숫자
- 문자열 리터럴 – 'USA', '이것은 샘플 텍스트입니다' 등의 문자열입니다.
- NULL – NULL 값.
- Current_TIME – 현재 시간을 알려줍니다.
- CURRENT_DATE – 현재 날짜를 알려줍니다.
이는 반환된 모든 행에 대해 상수 값을 선택해야 하는 일부 상황에서 유용할 수 있습니다. 예를 들어, 값 "USA"가 포함된 국가라는 새 열을 사용하여 Students 테이블에서 모든 학생을 선택하려면 다음을 수행할 수 있습니다.
SELECT *, 'USA' AS Country FROM Students;
이렇게 하면 모든 학생 열과 다음과 같은 새 열 "국가"가 제공됩니다.
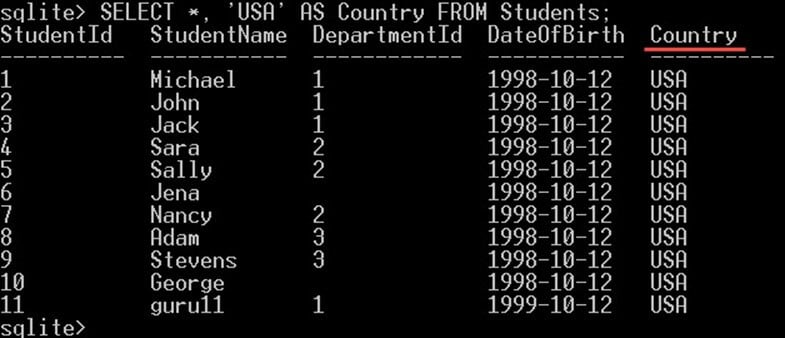
이 새 열 국가는 실제로 테이블에 추가된 새 열이 아닙니다. 결과를 표시하기 위해 쿼리에서 생성된 가상 열이며 테이블에는 생성되지 않습니다.
이름과 별칭
별칭은 새 이름으로 열을 선택할 수 있는 열의 새 이름입니다. 열 별칭은 "AS" 키워드를 사용하여 지정됩니다.
예를 들어, "StudentName" 대신 "학생 이름"으로 반환되도록 StudentName 열을 선택하려면 다음과 같이 별칭을 지정할 수 있습니다.
SELECT StudentName AS 'Student Name' FROM Students;
이렇게 하면 다음과 같이 "StudentName" 대신 "Student Name"이라는 이름으로 학생의 이름이 제공됩니다.

참고로, 열 이름은 여전히 "StudentName"입니다. StudentName 열 자체는 별칭으로 바뀌어도 변하지 않습니다.
별칭은 열 이름을 변경하지 않습니다. SELECT 절의 표시 이름만 변경됩니다.
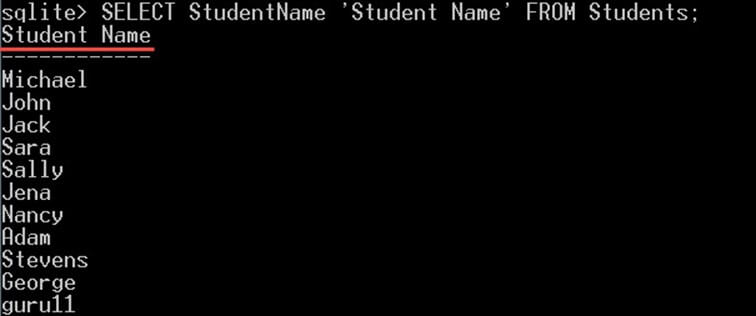
또한 키워드 "AS"는 선택 사항이므로 다음과 같이 별칭 이름을 키워드 없이 입력할 수 있습니다.
SELECT StudentName 'Student Name' FROM Students;
그러면 이전 쿼리와 정확히 동일한 출력이 제공됩니다.
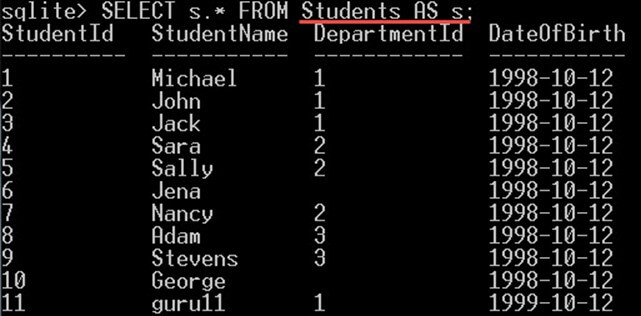
열뿐만 아니라 테이블 별칭도 지정할 수 있습니다. 동일한 키워드 "AS"를 사용합니다. 예를 들어 다음과 같이 할 수 있습니다.
SELECT s.* FROM Students AS s;
그러면 Students 테이블의 모든 열이 제공됩니다.
여러 테이블을 조인하는 경우 매우 유용할 수 있습니다. 쿼리에서 전체 테이블 이름을 반복하는 대신 각 테이블에 짧은 별칭 이름을 지정할 수 있습니다. 예를 들어, 다음 쿼리에서:
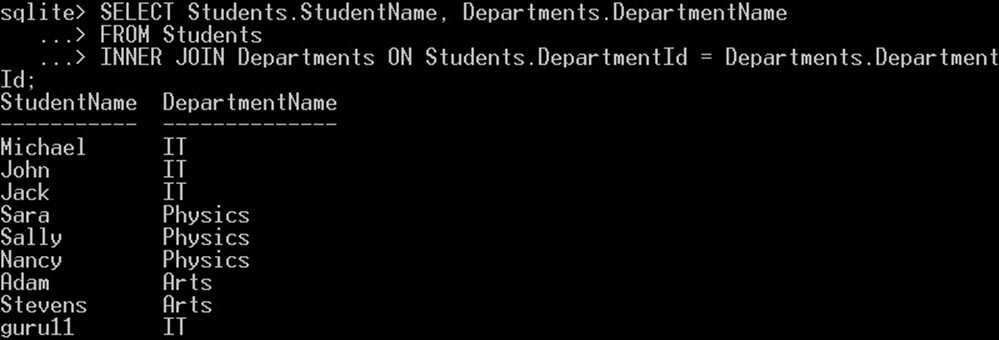
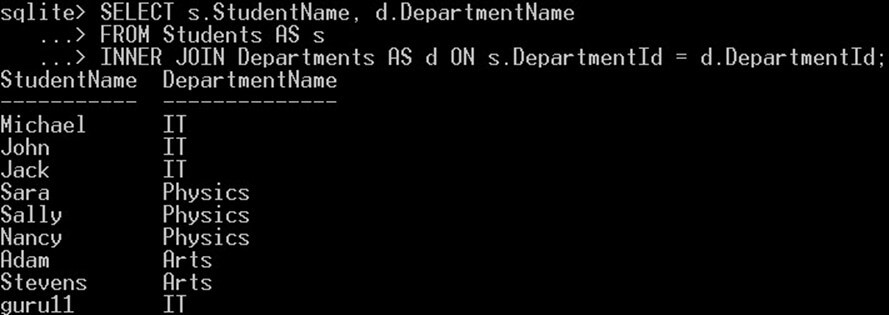
SELECT Students.StudentName, Departments.DepartmentName FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
이 쿼리는 "Departments" 테이블의 부서 이름과 함께 "Students" 테이블의 각 학생 이름을 선택합니다.
그러나 동일한 쿼리를 다음과 같이 작성할 수 있습니다.
SELECT s.StudentName, d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
학생 테이블에는 "s"라는 별칭을, 부서 테이블에는 "d"라는 별칭을 지정했습니다. 그런 다음 테이블의 전체 이름을 사용하는 대신 별칭을 사용하여 테이블을 참조했습니다. INNER JOIN은 조건을 사용하여 두 개 이상의 테이블을 결합합니다. 이 예에서는 DepartmentId 열을 기준으로 학생 테이블과 부서 테이블을 결합했습니다. INNER JOIN에 대한 자세한 설명은 " 에서 확인할 수 있습니다.SQLite 조인”튜토리얼.
그러면 이전 쿼리와 동일한 출력이 제공됩니다.
Neocity
이전 섹션에서 본 것처럼 FROM 절과 함께 SELECT 절만 사용하여 SQL 쿼리를 작성하면 테이블의 모든 행이 제공됩니다. 그러나 반환된 데이터를 필터링하려면 "WHERE" 절을 추가해야 합니다.
WHERE 절은 SQL 쿼리에서 반환되는 결과 집합을 필터링하는 데 사용됩니다. WHERE 절의 작동 방식은 다음과 같습니다.
- WHERE 절에서 "표현식"을 지정할 수 있습니다.
- 해당 표현식은 FROM 절에 지정된 테이블에서 반환된 각 행에 대해 평가됩니다.
- 표현식은 부울 표현식으로 평가되며 결과는 true, false 또는 null입니다.
- 그런 다음 표현식이 true 값으로 평가된 행만 반환되고, false 또는 null 결과가 있는 행은 무시되고 결과 집합에 포함되지 않습니다.
WHERE 절을 사용하여 결과 집합을 필터링하려면 표현식과 연산자를 사용해야 합니다.
운영자 목록 SQLite 및 사용 방법
다음 섹션에서는 표현식과 연산자를 사용하여 필터링하는 방법을 설명합니다.
표현식은 연산자를 사용하여 결합된 하나 이상의 리터럴 값 또는 열입니다.
SELECT 절과 WHERE 절 모두에서 표현식을 사용할 수 있습니다.
다음 예제에서는 select 절과 WHERE 절 모두에서 표현식과 연산자를 시도해 보겠습니다. 어떻게 수행되는지 보여드리기 위해서요.
다음과 같이 지정할 수 있는 다양한 유형의 표현식과 연산자가 있습니다.
SQLite 연결 연산자 “||”
이 연산자는 하나 이상의 리터럴 값 또는 열을 서로 연결하는 데 사용됩니다. 연결된 모든 리터럴 값 또는 열에서 결과 문자열 하나를 생성합니다. 예를 들어:
SELECT 'Id with Name: '|| StudentId || StudentName AS StudentIdWithName FROM Students;
이렇게 하면 "StudentIdWithName"이라는 새로운 별칭이 생성됩니다.
- 문자 그대로의 문자열 값 "이름이 있는 ID: "
- “StudentId” 열의 값을 사용하여
- "StudentName" 열의 값으로

SQLite CAST 운영자:
CAST 연산자는 값을 다른 값으로 변환하는 데 사용됩니다. 데이터 형식 다른 데이터 유형으로 변환합니다.
예를 들어, "12.5"와 같이 문자열 값으로 저장된 숫자 값을 정수 값으로 변환하려면 CAST 연산자를 사용하여 "CAST('12.5' AS REAL)"과 같이 변환할 수 있습니다. 또는 12.5와 같은 소수 값에서 정수 부분만 추출하려면 "CAST(12.5 AS INTEGER)"와 같이 정수로 변환할 수 있습니다.
예시
다음 명령에서는 다양한 값을 다른 데이터 유형으로 변환해 보겠습니다.
SELECT CAST('12.5' AS REAL) ToReal, CAST(12.5 AS INTEGER) AS ToInteger;
이것은 당신에게 줄 것입니다 :

결과는 다음과 같습니다.
- CAST('12.5' AS REAL) – '12.5' 값은 문자열 값이므로 REAL 값으로 변환됩니다.
- CAST(12.5 AS INTEGER) – 값 12.5는 12진수 값이며 정수 값으로 변환됩니다. 소수 부분이 잘려 XNUMX가 됩니다.
SQLite 산수 Opera토르:
두 개 이상의 숫자 리터럴 값 또는 숫자 열을 가져와 하나의 숫자 값을 반환합니다. 다음에서 지원되는 산술 연산자 SQLite 위치 :
- 덧셈 "+"는 두 피연산자의 합을 나타냅니다.
- 서브traction “–” – 하위trac두 피연산자와 그 차이값을 구합니다.
- 곱셈 "*" - 두 피연산자의 곱.
- 나머지 연산자(모듈로 연산자) "%"는 한 피연산자를 다른 피연산자로 나눈 나머지를 나타냅니다.
- 나눗셈 연산자 "/"는 왼쪽 피연산자를 오른쪽 피연산자로 나눈 몫을 반환합니다.
예:
다음 예제에서는 동일한 SELECT 절에서 리터럴 숫자 값에 대해 다섯 가지 산술 연산자를 모두 사용해 보겠습니다.
SELECT 25+6, 25-6, 25*6, 25%6, 25/6;
이것은 당신에게 줄 것입니다 :

여기서 FROM 절 없이 SELECT 문을 어떻게 사용했는지 주목하세요. 그리고 이것은 허용됩니다 SQLite 리터럴 값을 선택하는 한.
SQLite 비교 연산자
두 피연산자를 서로 비교하여 다음과 같이 참 또는 거짓을 반환합니다.
- "<" - 왼쪽 피연산자가 오른쪽 피연산자보다 작으면 true를 반환합니다.
- “<=" 연산자는 왼쪽 피연산자가 오른쪽 피연산자보다 작거나 같으면 true를 반환합니다.
- ">" - 왼쪽 피연산자가 오른쪽 피연산자보다 크면 true를 반환합니다.
- “>=" 연산자는 왼쪽 피연산자가 오른쪽 피연산자보다 크거나 같으면 true를 반환합니다.
- "="와 "==" 연산자는 두 피연산자가 같으면 true를 반환합니다. 두 연산자는 동일하며, 아무런 차이가 없습니다.
- "!="와 "<>"는 두 피연산자가 같지 않으면 true를 반환합니다. 두 연산자는 동일하며, 차이점이 없습니다.
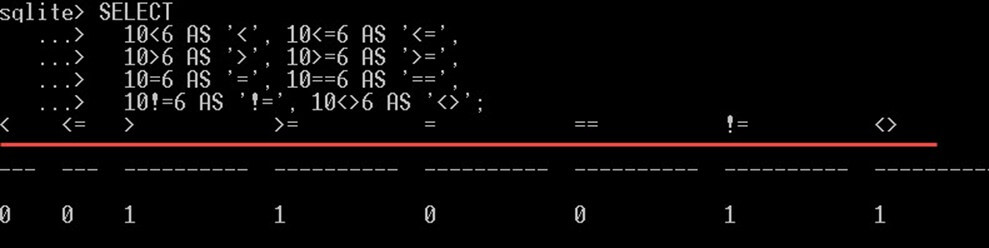
참고로 SQLite 참값을 1로, 거짓값을 0으로 표현합니다.
예:
SELECT 10<6 AS '<', 10<=6 AS '<=', 10>6 AS '>', 10>=6 AS '>=', 10=6 AS '=', 10==6 AS '==', 10!=6 AS '!=', 10<>6 AS '<>';
그러면 다음과 같은 내용이 제공됩니다.
SQLite 패턴 매칭 연산자
"LIKE"는 패턴 일치에 사용됩니다. "LIKE"를 사용하면 와일드카드를 사용하여 지정한 패턴과 일치하는 값을 검색할 수 있습니다.
왼쪽의 피연산자는 문자열 리터럴 값 또는 문자열 열이 될 수 있습니다. 패턴은 다음과 같이 지정할 수 있습니다.
- 특정 패턴을 포함합니다. 예를 들어, StudentName LIKE '%a%'는 StudentName 열에서 이름 어디에든 "a"라는 문자가 포함된 학생을 검색합니다.
- 먼저 패턴을 지정하세요. 예를 들어, "StudentName LIKE 'a%'"는 "a"로 시작하는 학생 이름을 검색하는 것입니다.
- 패턴으로 끝납니다. 예를 들어, "StudentName LIKE '%a'"는 이름이 "a"로 끝나는 학생을 검색합니다.
- 밑줄 문자 "_"를 사용하여 문자열에서 임의의 단일 문자와 일치하는 학생 이름을 찾습니다. 예를 들어, "StudentName LIKE 'J___'"는 길이가 4자인 학생 이름을 검색합니다. 이름은 반드시 "J"로 시작해야 하며, "J" 뒤에는 임의의 세 문자가 올 수 있습니다.
패턴 일치 예:
'j' 문자로 시작하는 학생 이름을 가져옵니다.
SELECT StudentName FROM Students WHERE StudentName LIKE 'j%';
결과 :

'y' 문자로 끝나는 학생 이름을 가져옵니다.
SELECT StudentName FROM Students WHERE StudentName LIKE '%y';
결과 :

'n' 문자가 포함된 학생 이름을 가져옵니다.
SELECT StudentName FROM Students WHERE StudentName LIKE '%n%';
결과 :

"GLOB"은 LIKE 연산자와 동일하지만, LIKE 연산자와 달리 대소문자를 구분합니다. 예를 들어, 다음 두 명령은 서로 다른 결과를 반환합니다.
SELECT 'Jack' GLOB 'j%'; SELECT 'Jack' LIKE 'j%';
이것은 당신에게 줄 것입니다 :

첫 번째 문장은 GLOB 연산자가 대소문자를 구분하므로 'j'는 'J'와 같지 않기 때문에 0(false)을 반환합니다. 그러나 두 번째 문장은 LIKE 연산자가 대소문자를 구분하지 않으므로 'j'는 'J'와 같기 때문에 1(true)을 반환합니다.
다른 운영자:
SQLite 및
하나 이상의 표현식을 결합하는 논리 연산자입니다. 모든 표현식이 "참" 값을 산출하는 경우에만 참을 반환합니다. 그러나 모든 표현식이 "거짓" 값을 산출하는 경우에만 거짓을 반환합니다.
예:
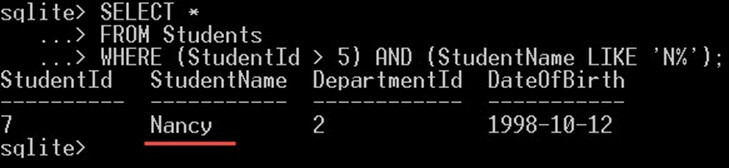
다음 쿼리는 StudentId > 5이고 StudentName이 N으로 시작하는 학생을 검색합니다. 반환된 학생은 두 가지 조건을 충족해야 합니다.
SELECT * FROM Students WHERE (StudentId > 5) AND (StudentName LIKE 'N%');
출력으로 위 스크린샷에서는 "Nancy"만 제공됩니다. 낸시는 두 가지 조건을 모두 충족하는 유일한 학생입니다.
SQLite OR
하나 이상의 표현식을 결합하는 논리 연산자로, 결합된 연산자 중 하나가 참을 산출하면 참을 반환합니다. 그러나 모든 표현식이 거짓을 산출하면 거짓을 반환합니다.
예:
다음 쿼리는 StudentId > 5인 학생을 검색하거나 StudentName이 N으로 시작하는 학생을 검색합니다. 반환된 학생은 다음 조건 중 하나 이상을 충족해야 합니다.
SELECT * FROM Students WHERE (StudentId > 5) OR (StudentName LIKE 'N%');
이것은 당신에게 줄 것입니다 :
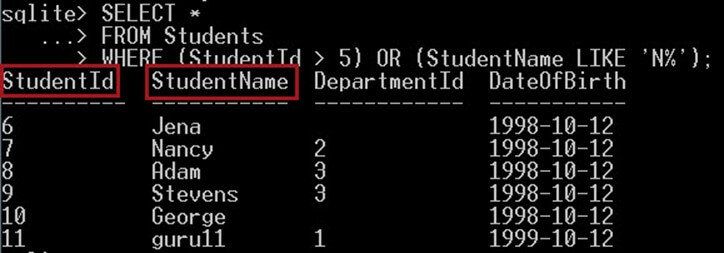
출력으로 위 스크린샷에서는 이름에 문자 "n"이 포함된 학생의 이름과 값이 5보다 큰 학생 ID가 표시됩니다.
보시다시피 결과는 AND 연산자를 사용한 쿼리와 다릅니다.
SQLite 중에서
BETWEEN은 두 값의 범위 내에 있는 값을 선택하는 데 사용됩니다. 예를 들어, "X BETWEEN Y AND Z"는 값 X가 두 값 Y와 Z 사이에 있으면 true(1)를 반환합니다. 그렇지 않으면 false(0)를 반환합니다. "X BETWEEN Y AND Z"는 "X >= Y AND X <= Z"와 동일하며, X는 Y보다 크거나 같고 X는 Z보다 작거나 같아야 합니다.
예:
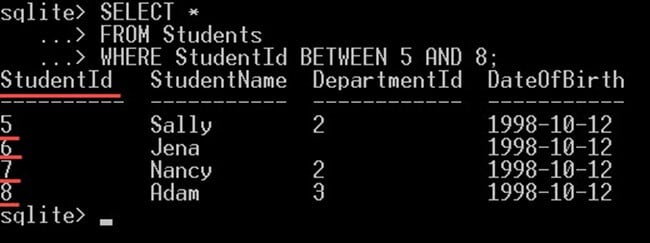
다음 예제 쿼리에서는 ID 값이 5~8 사이인 학생을 가져오는 쿼리를 작성합니다.
SELECT * FROM Students WHERE StudentId BETWEEN 5 AND 8;
그러면 ID가 5, 6, 7, 8인 학생에게만 제공됩니다.
SQLite IN
피연산자 하나와 피연산자 목록을 사용합니다. 첫 번째 피연산자 값이 목록의 피연산자 값 중 하나와 같으면 true를 반환합니다. IN 연산자는 피연산자 목록에 값 내에 첫 번째 피연산자 값이 포함되어 있으면 true(1)를 반환합니다. 그렇지 않으면 false(0)를 반환합니다.
예를 들어, “col IN(x, y, z)”와 같습니다. 이는 ” (col=x) 또는 (col=y) 또는 (col=z) ”와 동일합니다.
예:
다음 쿼리는 ID가 2, 4, 6, 8인 학생만 선택합니다.
SELECT * FROM Students WHERE StudentId IN(2, 4, 6, 8);
이 같은 :

이전 쿼리는 다음 쿼리와 정확히 같은 결과를 제공합니다. 왜냐하면 두 쿼리는 동등하기 때문입니다.
SELECT * FROM Students WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);
두 쿼리 모두 정확한 출력을 제공합니다. 그러나 두 쿼리의 차이점은 첫 번째 쿼리에서 "IN" 연산자를 사용했다는 것입니다. 두 번째 쿼리에서는 여러 개의 "OR" 연산자를 사용했습니다.
IN 연산자는 여러 개의 OR 연산자를 사용하는 것과 같습니다. "WHERE StudentId IN(2, 4, 6, 8)"은 "WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);"과 같습니다.
이 같은 :

SQLite 안
"NOT IN" 연산자는 "IN" 연산자의 반대입니다. 구문은 동일하며, 하나의 피연산자와 여러 피연산자의 리스트를 인수로 받습니다. 첫 번째 피연산자의 값이 리스트에 있는 피연산자 값 중 하나와 같지 않으면 true(0)를 반환합니다. 즉, 리스트에 첫 번째 피연산자가 없으면 true(0)를 반환합니다. 예를 들어, "col NOT IN(x, y, z)"는 "(col<>x) AND (col<>y) AND (col<>z)"와 같습니다.
예:
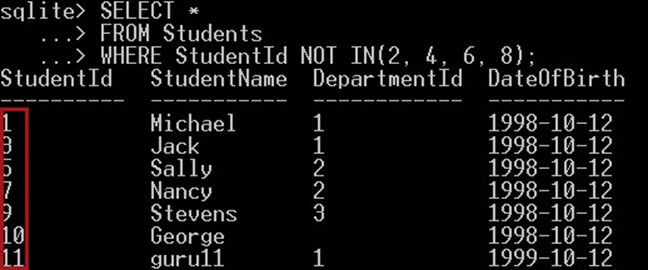
다음 쿼리는 ID 2, 4, 6, 8 중 어느 것과도 같지 않은 학생을 선택합니다.
SELECT * FROM Students WHERE StudentId NOT IN(2, 4, 6, 8);
이렇게
이전 쿼리는 다음 쿼리와 동등하기 때문에 정확한 결과를 제공합니다.
SELECT * FROM Students WHERE (StudentId <> 2) AND (StudentId <> 4) AND (StudentId <> 6) AND (StudentId <> 8);
이 같은 :
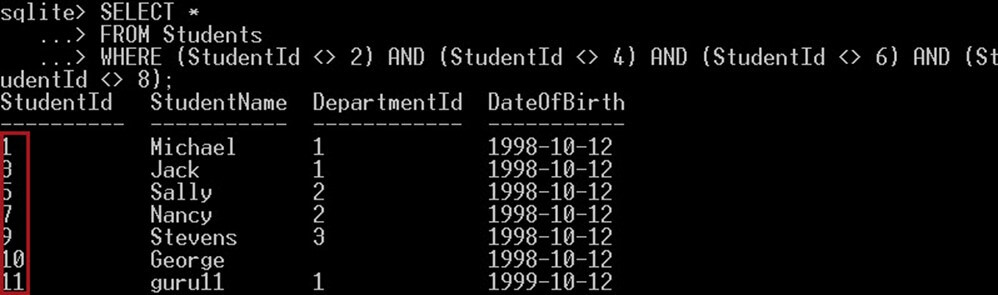
위 스크린샷에서,
우리는 다음 ID 2, 4, 6, 8 중 어느 것과도 같지 않은 학생 목록을 얻기 위해 여러 개의 같지 않음 연산자 “<>”를 사용했습니다. 이 쿼리는 이러한 ID 목록 외의 다른 모든 학생을 반환합니다.
SQLite 존재
EXISTS 연산자는 피연산자를 취하지 않습니다. 뒤에 SELECT 절만 취합니다. EXISTS 연산자는 SELECT 절에서 반환된 행이 있으면 true(1)를 반환하고, SELECT 절에서 반환된 행이 전혀 없으면 false(0)를 반환합니다.
예:
다음 예에서는 학생 테이블에 학과 ID가 있는 경우 학과 이름을 선택합니다.
SELECT DepartmentName FROM Departments AS d WHERE EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
이것은 당신에게 줄 것입니다 :

"IT, 물리학, 예술" 세 학과만 반환됩니다. "수학" 학과는 해당 학과에 학생이 없으므로 학과 ID가 학생 테이블에 존재하지 않아 반환되지 않습니다. 따라서 EXISTS 연산자는 "수학" 학과를 무시합니다.
SQLite 않습니다.
Reverses는 바로 뒤에 오는 연산자의 결과입니다. 예를 들면 다음과 같습니다.
- NOT BETWEEN - BETWEEN이 false를 반환하면 true를 반환하고 그 반대의 경우도 마찬가지입니다.
- NOT LIKE – LIKE가 false를 반환하면 true를 반환하고 그 반대의 경우도 마찬가지입니다.
- NOT GLOB – GLOB가 false를 반환하면 true를 반환하고 그 반대의 경우도 마찬가지입니다.
- NOT EXISTS – EXISTS가 false를 반환하면 true를 반환하고 그 반대의 경우도 마찬가지입니다.
예:
다음 예제에서는 EXISTS 연산자와 함께 NOT 연산자를 사용하여 Students 테이블에 없는 학과 이름을 가져옵니다. 이는 EXISTS 연산자의 역 결과입니다. 따라서 department 테이블에 없는 DepartmentId를 통해 검색이 수행됩니다.
SELECT DepartmentName FROM Departments AS d WHERE NOT EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
출력:

"수학" 학과만 반환됩니다. 왜냐하면 "수학" 학과는 학생 명단에 존재하지 않는 유일한 학과이기 때문입니다.
제한 및 주문
SQLite 주문번호
SQLite 순서는 하나 이상의 표현식을 기준으로 결과를 정렬하는 것입니다. 결과 집합을 정렬하려면 다음과 같이 ORDER BY 절을 사용해야 합니다.
- 먼저 ORDER BY 절을 지정해야 합니다.
- ORDER BY 절은 쿼리 끝에 지정되어야 합니다. 그 뒤에는 LIMIT 절만 지정할 수 있습니다.
- 데이터를 정렬할 표현식을 지정합니다. 이 표현식은 열 이름 또는 표현식일 수 있습니다.
- 표현식 뒤에 선택적 정렬 방향을 지정할 수 있습니다. 데이터를 내림차순으로 정렬하려면 DESC를 사용하고, 데이터를 오름차순으로 정렬하려면 ASC를 사용합니다. 아무것도 지정하지 않으면 데이터가 오름차순으로 정렬됩니다.
- 서로 사이에 ","를 사용하여 더 많은 표현식을 지정할 수 있습니다.
예시
다음 예에서는 이름 순으로 정렬된 모든 학생을 내림차순으로 선택한 다음, 학과 이름 순으로 오름차순으로 선택합니다.
SELECT s.StudentName, d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId ORDER BY d.DepartmentName ASC , s.StudentName DESC;
이것은 당신에게 줄 것입니다 :
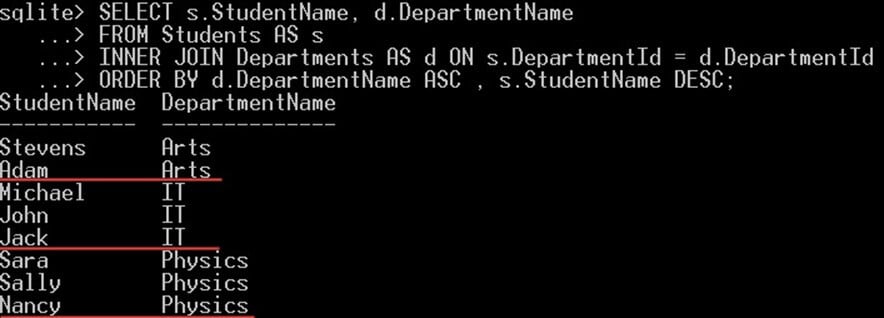
- SQLite 먼저 모든 학생의 학과 이름을 기준으로 오름차순으로 정렬합니다.
- 그런 다음 각 학과 이름에 대해 해당 학과 이름에 속하는 모든 학생이 이름 순으로 내림차순으로 표시됩니다.
SQLite 한도:
LIMIT 절을 사용하여 SQL 쿼리에서 반환되는 행 수를 제한할 수 있습니다. 예를 들어 LIMIT 10은 10개의 행만 제공하고 다른 모든 행은 무시합니다.
LIMIT 절에서 OFFSET 절을 사용하면 특정 위치에서 시작하는 특정 개수의 행을 선택할 수 있습니다. 예를 들어, "LIMIT 4 OFFSET 4"는 처음 4개 행을 무시하고 5번째 행부터 시작하는 4개 행(5, 6, 7, 8번째 행)을 반환합니다.
참고로 OFFSET 절은 선택 사항이며, "LIMIT 4, 4"와 같이 작성해도 정확한 결과를 얻을 수 있습니다.
예:
다음 예에서는 쿼리를 사용하여 학생 ID 3에서 시작하여 5명의 학생만 반환합니다.
SELECT * FROM Students LIMIT 4,3;
그러면 행 5부터 시작하여 5명의 학생만 제공됩니다. 따라서 StudentId가 6, 7, XNUMX인 행이 제공됩니다.

중복 제거
SQL 쿼리가 중복 값을 반환하는 경우 "DISTINCT" 키워드를 사용하여 중복을 제거하고 고유한 값만 반환할 수 있습니다. DISTINCT 키워드 뒤에 둘 이상의 열을 지정할 수도 있습니다.
예:
다음 쿼리는 중복된 "부서 이름 값"을 반환합니다. 여기에는 IT, Physics 및 Arts라는 이름의 중복된 값이 있습니다.
SELECT d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
이렇게 하면 부서 이름에 중복된 값이 제공됩니다.
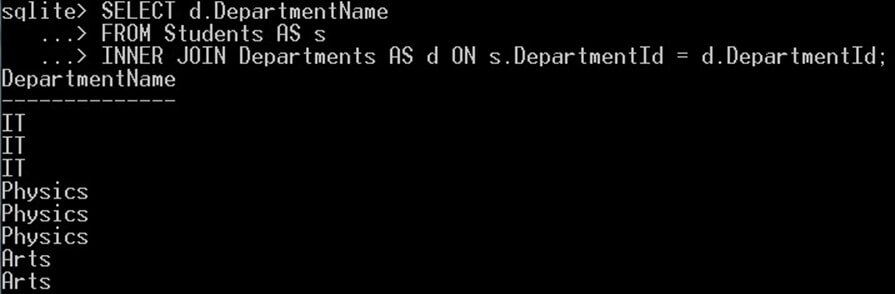
부서 이름에 중복된 값이 있는지 확인하세요. 이제 동일한 쿼리에 DISTINCT 키워드를 사용하여 중복 항목을 제거하고 고유한 값만 가져옵니다. 이와 같이:
SELECT DISTINCT d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
이렇게 하면 부서 이름 열에 대해 세 가지 고유 값만 제공됩니다.
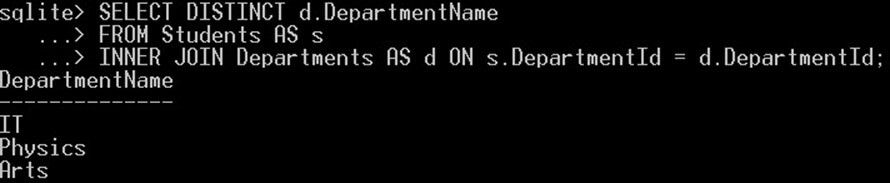
골재
SQLite 집계는 다음에 정의된 내장 함수입니다. SQLite 여러 행의 여러 값을 하나의 값으로 그룹화합니다.
다음은 에서 지원하는 집계입니다. SQLite:
SQLite AVG()
모든 x 값의 평균을 반환했습니다.
예:
다음 예시에서는 모든 시험에서 학생들이 받은 평균 점수를 알아볼 것입니다.
SELECT AVG(Mark) FROM Marks;
그러면 "18.375" 값이 제공됩니다.

이러한 결과는 모든 마크 값의 합계를 해당 개수로 나눈 결과입니다.
COUNT() – COUNT(X) 또는 COUNT(*)
x 값이 나타난 횟수의 총 개수를 반환합니다. COUNT와 함께 사용할 수 있는 몇 가지 옵션은 다음과 같습니다.
- COUNT(x): x 값만 계산합니다. 여기서 x는 열 이름입니다. NULL 값은 무시됩니다.
- COUNT(*): 모든 열의 모든 행을 계산합니다.
- COUNT (DISTINCT x): x의 고유 값 개수를 가져오는 x 앞에 DISTINCT 키워드를 지정할 수 있습니다.
예시
다음 예에서는 COUNT(DepartmentId), COUNT(*), COUNT(DISTINCT DepartmentId)를 사용하여 부서의 총 개수를 구하고 이들이 어떻게 다른지 알아봅니다.
SELECT COUNT(DepartmentId), COUNT(DISTINCT DepartmentId), COUNT(*) FROM Students;
이것은 당신에게 줄 것입니다 :

다음과 같습니다:
- COUNT(DepartmentId)는 모든 부서 ID의 개수를 제공하며 null 값은 무시됩니다.
- COUNT(DISTINCT DepartmentId)는 부서 이름의 세 가지 다른 값인 DepartmentId의 고유한 값을 3개만 제공합니다. 학생 이름에는 학과 이름 값이 8개 있습니다. 하지만 수학, IT, 물리학이라는 세 가지 가치만 다릅니다.
- COUNT(*)는 학생 테이블에서 10명의 학생에 대해 10개의 행이 있는 행 수를 계산합니다.
GROUP_CONCAT() – GROUP_CONCAT(X) 또는 GROUP_CONCAT(X,Y)
GROUP_CONCAT 집계 함수는 여러 값을 쉼표로 구분하여 하나의 값으로 연결합니다. 다음과 같은 옵션이 있습니다.
- GROUP_CONCAT(X): 이는 값 사이의 구분 기호로 사용되는 쉼표 ","를 사용하여 x의 모든 값을 하나의 문자열로 연결합니다. NULL 값은 무시됩니다.
- GROUP_CONCAT(X, Y): x 값을 하나의 문자열로 연결합니다. y 값은 기본 구분 기호 ',' 대신 각 값 사이의 구분 기호로 사용됩니다. NULL 값도 무시됩니다.
- GROUP_CONCAT(DISTINCT X): 이는 값 사이의 구분 기호로 사용되는 쉼표 ","를 사용하여 x의 모든 개별 값을 하나의 문자열로 연결합니다. NULL 값은 무시됩니다.
GROUP_CONCAT(부서명) 예
다음 쿼리는 students와 departments 테이블의 모든 부서 이름 값을 쉼표로 구분된 하나의 문자열로 연결합니다. 따라서 값 목록을 반환하는 대신 각 행에 하나의 값을 반환합니다. 모든 값을 쉼표로 구분하여 한 행에 하나의 값만 반환합니다.
SELECT GROUP_CONCAT(d.DepartmentName) FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
이것은 당신에게 줄 것입니다 :

그러면 쉼표로 구분된 하나의 문자열로 연결된 8개 부서의 이름 값 목록이 제공됩니다.
GROUP_CONCAT(DISTINCT 부서명) 예
다음 쿼리는 students 및 departments 테이블의 학과 이름의 고유한 값을 쉼표로 구분하여 하나의 문자열로 연결합니다.
SELECT GROUP_CONCAT(DISTINCT d.DepartmentName) FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
이것은 당신에게 줄 것입니다 :

결과가 이전 결과와 어떻게 다른지 확인하세요. 고유한 부서 이름인 XNUMX개의 값만 반환되었으며 중복된 값은 제거되었습니다.
GROUP_CONCAT(부서명 ,'&') 예
다음 쿼리는 students 및 departments 테이블의 department name 열의 모든 값을 하나의 문자열로 연결하지만, 쉼표 대신 '&' 문자를 구분자로 사용합니다.
SELECT GROUP_CONCAT(d.DepartmentName, '&') FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
이것은 당신에게 줄 것입니다 :

값을 구분하기 위해 기본 문자 "," 대신 "&" 문자가 어떻게 사용되는지 확인하세요.
SQLite 최대() 및 최소()
MAX(X)는 X 값 중 가장 높은 값을 반환합니다. MAX는 x의 모든 값이 null인 경우 NULL 값을 반환합니다. MIN(X)는 X 값에서 가장 작은 값을 반환합니다. MIN은 X의 모든 값이 null인 경우 NULL 값을 반환합니다.
예시
다음 쿼리에서는 MIN 및 MAX 함수를 사용하여 "Marks" 테이블에서 가장 높은 점수와 가장 낮은 점수를 가져옵니다.
SELECT MAX(Mark), MIN(Mark) FROM Marks;
이것은 당신에게 줄 것입니다 :

SQLite 합계(x), 합계(x)
둘 다 모든 x 값의 합을 반환합니다. 하지만 다음에서 다릅니다.
- SUM은 모든 값이 Null인 경우 Null을 반환하지만 Total은 0을 반환합니다.
- TOTAL은 항상 부동 소수점 값을 반환합니다. SUM은 모든 x 값이 정수인 경우 정수 값을 반환합니다. 그러나 값이 정수가 아닌 경우 부동 소수점 값을 반환합니다.
예시
다음 쿼리에서는 SUM과 total 함수를 사용하여 "Marks" 테이블에 있는 모든 점수의 합계를 구합니다.
SELECT SUM(Mark), TOTAL(Mark) FROM Marks;
이것은 당신에게 줄 것입니다 :

보시다시피 TOTAL은 항상 부동 소수점을 반환합니다. 그러나 "표시" 열의 값이 정수일 수 있으므로 SUM은 정수 값을 반환합니다.
SUM과 TOTAL의 차이점 예:
다음 쿼리에서는 NULL 값의 SUM을 구할 때 SUM과 TOTAL의 차이를 보여줍니다.
SELECT SUM(Mark), TOTAL(Mark) FROM Marks WHERE TestId = 4;
이것은 당신에게 줄 것입니다 :

TestId = 4에 대한 표시가 없으므로 해당 테스트에는 null 값이 있습니다. SUM은 null 값을 공백으로 반환하는 반면 TOTAL은 0을 반환합니다.
그룹별로
GROUP BY 절은 행을 그룹으로 그룹화하는 데 사용할 하나 이상의 열을 지정하는 데 사용됩니다. 동일한 값을 가진 행은 그룹으로 함께 모아(정렬)됩니다.
그룹 기준 열에 포함되지 않은 다른 열의 경우 집계 함수를 사용할 수 있습니다.
예:
다음 쿼리는 각 학과에 재학 중인 학생의 총 수를 알려줍니다.
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId GROUP BY d. DepartmentName;
이것은 당신에게 줄 것입니다 :
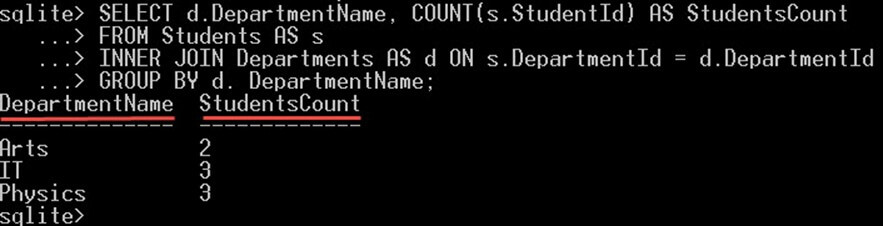
GROUPBY DepartmentName 절은 모든 학생을 각 학과 이름에 대한 그룹으로 그룹화합니다. 각 "학과" 그룹에 대해 학생 수를 계산합니다.
HAVING 절
GROUP BY 절에서 반환된 그룹을 필터링하려면 GROUP BY 뒤에 표현식이 포함된 "HAVING" 절을 지정할 수 있습니다. 표현식은 이러한 그룹을 필터링하는 데 사용됩니다.
예시
다음 쿼리에서는 학생이 두 명만 있는 학과를 선택합니다.
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId GROUP BY d. DepartmentName HAVING COUNT(s.StudentId) = 2;
이것은 당신에게 줄 것입니다 :
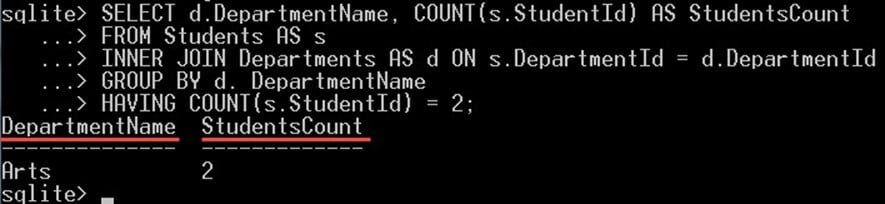
HAVING COUNT(S.StudentId) = 2 절은 반환된 그룹을 필터링하고 정확히 두 명의 학생이 포함된 그룹만 반환합니다. 우리의 경우 예술과에는 학생이 2명이므로 출력에 표시됩니다.
SQLite 쿼리 및 하위 쿼리
쿼리 내에서는 SELECT, INSERT, DELETE, UPDATE 또는 다른 하위 쿼리 내에서 다른 쿼리를 사용할 수 있습니다.
이 중첩 쿼리를 하위 쿼리라고 합니다. 이제 SELECT 절에서 하위 쿼리를 사용하는 몇 가지 예를 살펴보겠습니다. 그러나 데이터 수정 튜토리얼에서는 INSERT, DELETE 및 UPDATE 문과 함께 하위 쿼리를 사용하는 방법을 살펴보겠습니다.
FROM 절 예제에서 하위 쿼리 사용
다음 쿼리에서는 FROM 절 내부에 하위 쿼리를 포함합니다.
SELECT s.StudentName, t.Mark FROM Students AS s INNER JOIN ( SELECT StudentId, Mark FROM Tests AS t INNER JOIN Marks AS m ON t.TestId = m.TestId ) ON s.StudentId = t.StudentId;
쿼리:
SELECT StudentId, Mark FROM Tests AS t INNER JOIN Marks AS m ON t.TestId = m.TestId
위 쿼리는 FROM 절 내에 중첩되어 있으므로 여기서는 하위 쿼리라고 합니다. 쿼리에서 반환된 열을 참조할 수 있도록 별칭 이름 "t"를 지정했습니다.
이 쿼리는 다음을 제공합니다.
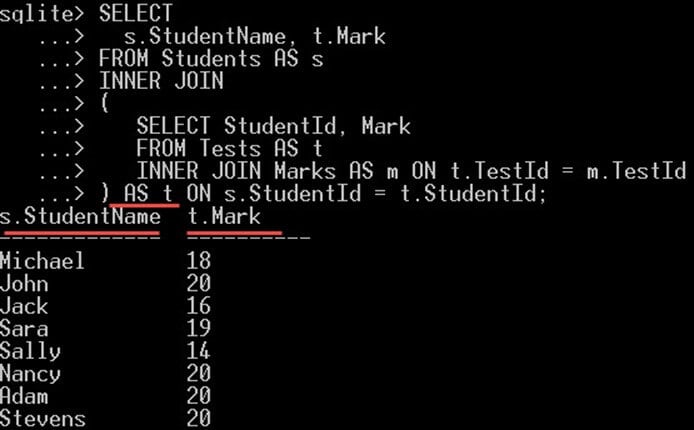
그래서 우리의 경우에는
- s.StudentName은 학생의 이름을 제공하는 기본 쿼리에서 선택됩니다.
- t.Mark가 하위 쿼리에서 선택되었습니다. 각 학생들이 얻은 점수를 주는 것입니다.
WHERE 절 예제에서 하위 쿼리 사용
다음 쿼리에서는 WHERE 절에 하위 쿼리를 포함합니다.
SELECT DepartmentName FROM Departments AS d WHERE NOT EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
쿼리:
SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId
위의 쿼리는 WHERE 절에 중첩되어 있기 때문에 여기서는 하위 쿼리라고 합니다. 하위 쿼리는 NOT EXISTS 연산자에서 사용할 DepartmentId 값을 반환합니다.
이 쿼리는 다음을 제공합니다.
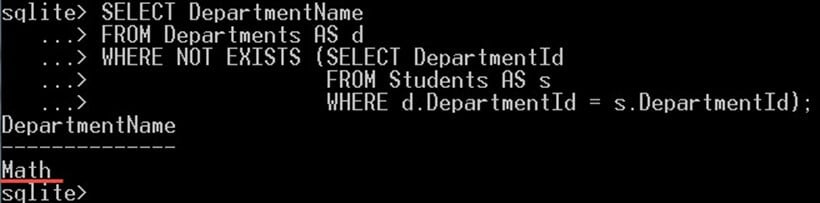
위 쿼리에서는 재학생이 없는 학과를 선택했습니다. 여기는 "수학" 부서입니다.
세트 Operations – UNION,Intersect
SQLite 다음 SET 작업을 지원합니다:
유니온 & 유니온 올
여러 SELECT 문에서 반환된 하나 이상의 결과 집합(행 그룹)을 하나의 결과 집합으로 결합합니다.
UNION은 고유한 값을 반환합니다. 그러나 UNION ALL은 중복 항목을 포함하지 않으며 포함할 것입니다.
열 이름은 첫 번째 SELECT 문에 지정된 열 이름이 됩니다.
UNION 예
다음 예제에서는 students 테이블에서 DepartmentId 목록을 가져오고 departments 테이블에서 DepartmentId 목록을 같은 열에서 가져옵니다.
SELECT DepartmentId AS DepartmentIdUnioned FROM Students UNION SELECT DepartmentId FROM Departments;
이것은 당신에게 줄 것입니다 :
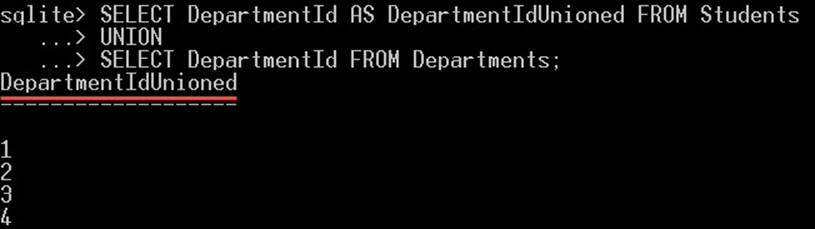
쿼리는 고유한 부서 ID 값인 5개의 행만 반환합니다. null 값인 첫 번째 값을 확인하세요.
SQLite UNION ALL 예
다음 예제에서는 students 테이블에서 DepartmentId 목록을 가져오고 departments 테이블에서 DepartmentId 목록을 같은 열에서 가져옵니다.
SELECT DepartmentId AS DepartmentIdUnioned FROM Students UNION ALL SELECT DepartmentId FROM Departments;
이것은 당신에게 줄 것입니다 :
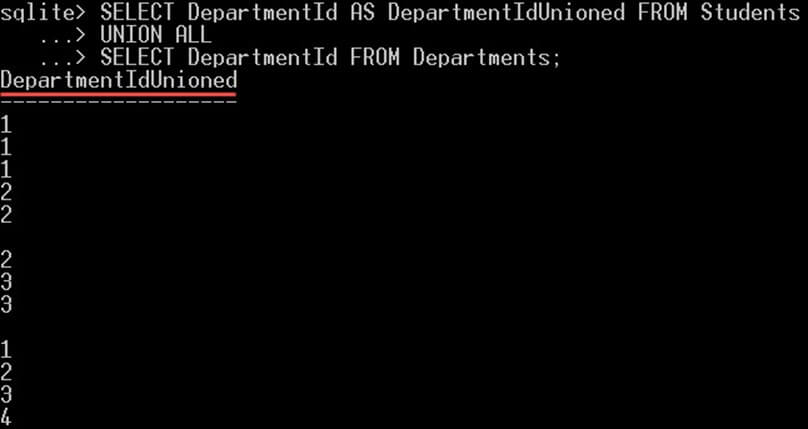
쿼리는 14개 행, 즉 Students 테이블에서 10개 행, Departments 테이블에서 4개 행을 반환합니다. 반환된 값에 중복된 값이 있습니다. 또한 열 이름은 첫 번째 SELECT 문에 지정된 이름이었습니다.
이제 UNION ALL을 UNION으로 바꾸면 UNION all이 어떻게 다른 결과를 내는지 살펴보겠습니다.
SQLite 교차
결합된 결과 집합 모두에 존재하는 값을 반환합니다. 결합된 결과 집합 중 하나에 존재하는 값은 무시됩니다.
예시
다음 쿼리에서는 DepartmentId 열에 있는 Students 테이블과 Departments 테이블에 모두 존재하는 DepartmentId 값을 선택합니다.
SELECT DepartmentId FROM Students Intersect SELECT DepartmentId FROM Departments;
이것은 당신에게 줄 것입니다 :
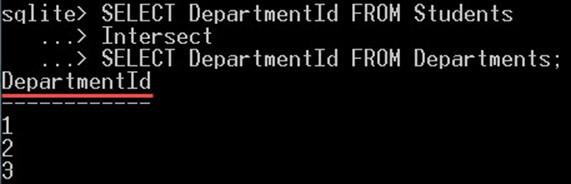
쿼리는 두 테이블 모두에 존재하는 값인 1, 2, 3의 세 가지 값만 반환합니다.
그러나 null 값은 Students 테이블에만 존재하고 Departments 테이블에는 존재하지 않으므로 null 값과 4는 포함되지 않았습니다. 그리고 값 4는 Students 테이블이 아닌 Departments 테이블에 존재합니다.
이것이 NULL 값과 4 값이 모두 무시되고 반환된 값에 포함되지 않는 이유입니다.
외
두 개의 행 목록, list1과 list2가 있고 list1에 없는 list2의 행만 원하는 경우, "EXCEPT" 절을 사용할 수 있습니다. EXCEPT 절은 두 목록을 비교하여 list1에 있고 list2에는 없는 행을 반환합니다.
예시
다음 쿼리에서는 departments 테이블에 존재하고 students 테이블에 존재하지 않는 DepartmentId 값을 선택합니다.
SELECT DepartmentId FROM Departments EXCEPT SELECT DepartmentId FROM Students;
이것은 당신에게 줄 것입니다 :

쿼리는 값 4만 반환합니다. 이는 Departments 테이블에 존재하는 유일한 값이고 학생 테이블에는 존재하지 않습니다.
NULL 처리
"NULL" 값은 특별한 값입니다. SQLitenull 값은 알 수 없거나 누락된 값을 나타내는 데 사용됩니다. null 값은 "0"이나 공백 "" 값과는 완전히 다릅니다. "0"과 공백 값은 알려진 값인 반면, null 값은 알 수 없는 값입니다.
NULL 값에는 특별한 처리가 필요합니다. SQLite, 이제 NULL 값을 처리하는 방법을 살펴보겠습니다.
NULL 값 검색
일반 등식 연산자(=)를 사용하여 null 값을 검색할 수 없습니다. 예를 들어, 다음 쿼리는 DepartmentId 값이 null인 학생을 검색합니다.
SELECT * FROM Students WHERE DepartmentId = NULL;
이 쿼리는 결과를 제공하지 않습니다.
![]()
NULL 값은 Null 값 자체가 포함된 다른 값과 동일하지 않기 때문에 결과가 반환되지 않습니다.
하지만 쿼리가 제대로 작동하려면 다음과 같이 "IS NULL" 연산자를 사용하여 null 값을 검색해야 합니다.
SELECT * FROM Students WHERE DepartmentId IS NULL;
이것은 당신에게 줄 것입니다 :

쿼리는 null DepartmentId 값이 있는 학생을 반환합니다.
null이 아닌 값을 얻으려면 다음과 같이 "IS NOT NULL" 연산자를 사용해야 합니다.
SELECT * FROM Students WHERE DepartmentId IS NOT NULL;
이것은 당신에게 줄 것입니다 :
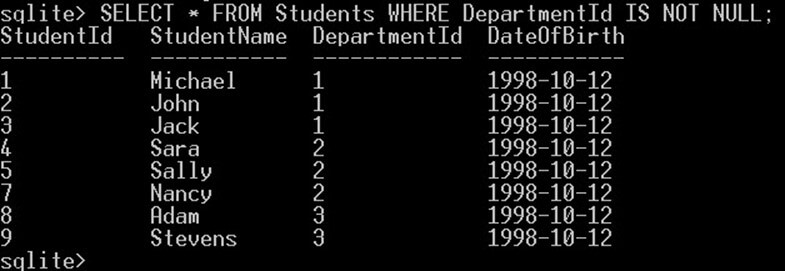
쿼리는 NULL DepartmentId 값이 없는 학생을 반환합니다.
조건부 결과
값 목록이 있고 일부 조건에 따라 그 중 하나를 선택하려는 경우. 이를 위해서는 특정 값에 대한 조건이 true여야 선택됩니다.
CASE 표현식은 모든 값에 대해 이러한 조건 목록을 평가합니다. 조건이 true이면 해당 값을 반환합니다.
예를 들어, "등급" 열이 있고 다음과 같이 등급 값을 기준으로 텍스트 값을 선택하려는 경우:
– 성적이 85점 이상인 경우 “우수”
– 성적이 70~85점 사이인 경우 “매우 좋음”입니다.
– 성적이 60~70점 사이이면 “좋음”입니다.
그런 다음 CASE 표현식을 사용하여 이를 수행할 수 있습니다.
이는 예를 들어 if 문과 같은 특정 조건에 따라 특정 결과를 선택할 수 있도록 SELECT 절에서 일부 논리를 정의하는 데 사용할 수 있습니다.
CASE 연산자는 다음과 같이 다양한 구문으로 정의할 수 있습니다.
다양한 조건을 사용할 수 있습니다.
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 WHEN condition3 THEN result3 … ELSE resultn END
또는 하나의 표현식만 사용하고 선택할 수 있는 다양한 값을 입력할 수 있습니다.
CASE expression WHEN value1 THEN result1 WHEN value2 THEN result2 WHEN value3 THEN result3 … ELSE restuln END
ELSE 절은 선택 사항입니다.
예시
다음 예에서는 Students 테이블의 department Id 열에 NULL 값이 있는 경우 CASE 표현식을 사용하여 '학과 없음'이라는 텍스트를 다음과 같이 표시합니다.
SELECT StudentName, CASE WHEN DepartmentId IS NULL THEN 'No Department' ELSE DepartmentId END AS DepartmentId FROM Students;
- CASE 연산자는 DepartmentId의 값이 null인지 여부를 확인합니다.
- NULL 값인 경우 DepartmentId 값 대신 리터럴 값 'No Department'가 선택됩니다.
- null 값이 아닌 경우 DepartmentId 열의 값이 선택됩니다.
그러면 아래와 같은 출력이 제공됩니다.
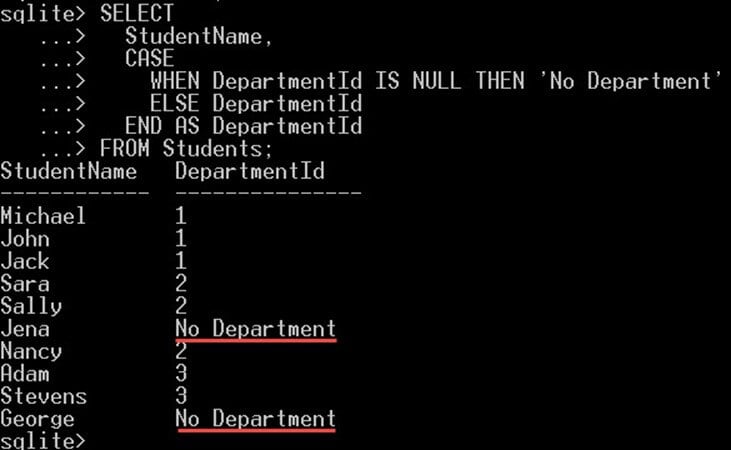
공통 테이블 표현식
CTE(공통 테이블 표현식)는 지정된 이름을 사용하여 SQL 문 내부에 정의되는 하위 쿼리입니다.
이는 SQL 문에서 정의되고 쿼리를 더 쉽게 읽고, 유지 관리하고, 이해할 수 있게 해주기 때문에 하위 쿼리에 비해 이점이 있습니다.
공통 테이블 표현식은 다음과 같이 SELECT 명령문 앞에 WITH 절을 넣어 정의할 수 있습니다.
WITH CTEname AS ( SELECT statement ) SELECT, UPDATE, INSERT, or update statement here FROM CTE
"CTEname"은 CTE에 지정할 수 있는 임의의 이름이며, 나중에 참조할 때 사용할 수 있습니다. 참고로, CTE에는 SELECT, UPDATE, INSERT 또는 DELETE 문을 정의할 수 있습니다.
이제 SELECT 절에서 CTE를 사용하는 방법의 예를 살펴보겠습니다.
예시
다음 예에서는 SELECT 문에서 CTE를 정의한 다음 나중에 다른 쿼리에서 이를 사용합니다.
WITH AllDepartments AS ( SELECT DepartmentId, DepartmentName FROM Departments ) SELECT s.StudentId, s.StudentName, a.DepartmentName FROM Students AS s INNER JOIN AllDepartments AS a ON s.DepartmentId = a.DepartmentId;
이 쿼리에서는 CTE를 정의하고 "AllDepartments"라는 이름을 지정했습니다. 이 CTE는 SELECT 쿼리에서 정의되었습니다.
SELECT DepartmentId, DepartmentName FROM Departments
그런 다음 CTE를 정의한 후 그 뒤에 오는 SELECT 쿼리에서 이를 사용했습니다.
공통 테이블 표현식은 쿼리 출력에 영향을 주지 않습니다. 동일한 쿼리에서 재사용하기 위해 논리적 뷰나 하위 쿼리를 정의하는 방법입니다. 공통 테이블 표현식은 선언하는 변수와 유사하며 이를 하위 쿼리로 재사용합니다. SELECT 문만 쿼리 출력에 영향을 미칩니다.
이 쿼리는 다음을 제공합니다.

고급 쿼리
고급 쿼리는 복잡한 조인, 하위 쿼리 및 일부 집계를 포함하는 쿼리입니다. 다음 섹션에서는 고급 쿼리의 예를 살펴보겠습니다.
우리가 얻는 곳은,
- 각 학과의 전체 학생이 포함된 학과 이름
- 학생 이름은 쉼표로 구분하고
- 해당 학과에 최소 3명의 학생이 있음을 보여줌
SELECT d.DepartmentName, COUNT(s.StudentId) StudentsCount, GROUP_CONCAT(StudentName) AS Students FROM Departments AS d INNER JOIN Students AS s ON s.DepartmentId = d.DepartmentId GROUP BY d.DepartmentName HAVING COUNT(s.StudentId) >= 3;
우리는 Departments 테이블에서 DepartmentName을 가져오기 위해 JOIN 절을 추가했습니다. 그 후 두 개의 집계 함수를 포함하는 GROUP BY 절을 추가했습니다.
- “COUNT”는 각 학과 그룹의 학생 수를 계산합니다.
- GROUP_CONCAT는 각 그룹의 학생을 하나의 문자열로 구분된 쉼표로 연결합니다.
GROUP BY 이후에는 HAVING 절을 사용하여 학과를 필터링하고 학생이 3명 이상인 학과만 선택했습니다.
결과는 다음과 같습니다.
