초보자를 위한 DataStage 튜토리얼: IBM ETL 도구
⚡ 스마트 요약
DataStage에서 IBM 인포스피어 전tracts는 대규모 엔터프라이즈 데이터를 변환하고 로드합니다. 이 페이지에서는 실제 DB2 소매업 예제를 사용하여 아키텍처, 구성 요소, 병렬 처리, SQL 복제 설정, 프로젝트 생성, 작업 컴파일 및 통합 테스트에 대해 설명합니다.

데이터스테이지란 무엇입니까?
데이터스테이지 ETL 도구는 추출에 사용됩니다.tracDataStage는 소스에서 대상으로 데이터를 변환하고 로드합니다. 이러한 데이터의 소스에는 순차 파일, 인덱스 파일, 관계형 데이터베이스, 외부 데이터 소스, 아카이브, 엔터프라이즈 애플리케이션 등이 포함될 수 있습니다. DataStage는 고품질 데이터를 제공하여 비즈니스 인텔리전스를 확보하는 데 도움을 줌으로써 비즈니스 분석을 용이하게 합니다.
DataStage ETL 도구는 대규모 조직에서 여러 시스템 간의 인터페이스 역할을 합니다. 이 도구는 다음과 같은 작업을 처리합니다.trac소스에서 대상으로 데이터의 전송, 변환 및 로딩을 담당합니다. 이 기능은 90년대 중반 VMark에서 처음 출시되었습니다. IBM 2005년 DataStage를 인수하여 사명을 변경했습니다. IBM WebSphere DataStage 및 이후 IBM 인포스피어.
현재까지 시중에 나와 있는 Datastage의 버전은 Enterprise Edition(PX), Server Edition, MVS Edition, DataStage for PeopleSoft 등이 있습니다. 최신판은 IBM 인포스피어 데이터스테이지.
IBM 정보 서버에는 다음 제품이 포함됩니다.
- IBM 인포스피어 데이터스테이지
- IBM InfoSphere QualityStage
- IBM InfoSphere 정보 서비스 이사
- IBM InfoSphere 정보 분석기
- IBM 정보 서버 빠른Track
- IBM InfoSphere 비즈니스 용어집
정의가 정립되었으니, 다음 섹션에서는 제품이 실제로 어떤 기능을 수행할 수 있는지 살펴보겠습니다. 데이터웨어 하우징 환경을 제공합니다.
데이터스테이지 개요
Datastage는 다음과 같은 기능을 갖추고 있습니다.
- 가장 광범위한 기업 및 외부 데이터 소스의 데이터를 통합할 수 있습니다.
- 데이터 유효성 검사 규칙을 구현합니다.
- 대량의 데이터를 처리하고 변환하는 데 유용합니다.
- 확장 가능한 병렬 처리 방식을 사용합니다.
- 복잡한 변환을 처리하고 여러 통합 프로세스를 관리할 수 있습니다.
- 엔터프라이즈 애플리케이션에 대한 직접 연결을 소스 또는 대상으로 활용
- 분석 및 유지 관리를 위해 메타데이터 활용
- Opera일괄, 실시간 또는 웹 서비스로 테스트
이 DataStage 튜토리얼의 다음 섹션에서는 다음 측면에 대해 간략하게 설명합니다. IBM InfoSphere 데이터스테이지:
- 데이터 변환
- 작업
- 병렬 처리
InfoSphere DataStage 및 QualityStage는 다음과 같은 엔터프라이즈 애플리케이션 및 데이터 소스의 데이터에 액세스할 수 있습니다.
- 관계형 데이터베이스
- 메인프레임 데이터베이스
- 비즈니스 및 분석 애플리케이션
- 전사적 자원 관리(ERP) 또는 고객 관계 관리(CRM) 데이터베이스
- 온라인 분석 처리(OLAP) 또는 성과 관리 데이터베이스
처리 단계 유형
IBM Infosphere 작업은 서로 연결된 개별 단계로 구성됩니다. 이는 데이터 소스에서 데이터 대상으로의 데이터 흐름을 설명합니다. 일반적으로 스테이지에는 최소 하나의 데이터 입력 및/또는 하나의 데이터 출력이 있습니다. 그러나 일부 단계에서는 둘 이상의 데이터 입력을 허용하고 둘 이상의 단계로 출력할 수 있습니다.
작업 디자인에서 사용할 수 있는 다양한 단계는 다음과 같습니다.
- 변환 단계
- 필터 단계
- 수집기 단계
- 중복 단계 제거
- 스테이지 참여
- 조회 단계
- 복사 단계
- 정렬 단계
- 용기
데이터 통합에 DataStage를 사용하는 이유는 무엇일까요?
기능 목록을 아는 것과 해당 도구가 라이선스 비용만큼의 가치를 발휘하는 시점을 아는 것은 별개의 문제입니다. DataStage는 대용량, 거버넌스 및 이기종 소스로 인해 수동 스크립트 관리가 불가능한 워크로드에 적합합니다.
가장 확실한 이유는 처리량입니다. 엔진이 데이터를 노드에 분산시키고 여러 단계 간에 레코드를 동시에 스트리밍하기 때문에 하드웨어를 추가하면 처리량이 거의 선형적으로 증가합니다. 2노드 개발 환경에서 설계된 작업은 8노드 프로덕션 클러스터에서도 변경 없이 실행됩니다.
나머지 이유는 기술적인 문제라기보다는 조직적인 문제입니다.
- 공유 메타데이터: 테이블 정의, 연결 및 비즈니스 용어는 저장소에 한 번만 저장되고 모든 작업에서 재사용되므로 각 개발자가 소스를 독립적으로 정의할 때 발생하는 불일치를 제거합니다.
- 내장된 데이터 품질 기능: QualityStage는 ETL 흐름과 함께 조사, 표준화, 매칭 및 생존성 검증을 수행하므로 정제를 위해 별도의 제품이 필요하지 않습니다.
- 광범위한 연결성: 네이티브 커넥터는 DB2에 연결됩니다. Oracle테라데이터, 메인프레임 VSAM, SAPSalesforce 및 클라우드 객체 스토리지를 사용자 지정 코드 없이 사용할 수 있습니다.
- Opera전략적 제어: Director는 실행 기록, 행 수, 경고 및 재시작 지점을 제공하며, 감사자는 이를 통제된 데이터 파이프라인의 증거로 인정합니다.
- 재사용 성: 공유 컨테이너와 파라미터 세트를 사용하면 테스트를 거친 하나의 변환을 여러 작업에 사용할 수 있으며, 각 작업에 변환을 복사할 필요가 없습니다.
이러한 이점은 제품 조립 방식에 직접적으로 달려 있으며, 다음 섹션에서 이에 대해 설명합니다.
DataStage 구성요소 및 Archi강의
DataStage에는 네 가지 주요 구성 요소가 있습니다.
- 관리자 : 관리 작업에 사용됩니다. 여기에는 DataStage 사용자 설정, 제거 기준 설정, 프로젝트 생성 및 이동이 포함됩니다.
- 매니저 : ETL DataStage 저장소의 기본 인터페이스입니다. 재사용 가능한 메타데이터의 저장 및 관리에 사용됩니다. DataStage 관리자를 통해 저장소의 내용을 보고 편집할 수 있습니다.
- 디자이너 : DataStage 애플리케이션 또는 작업을 생성하는 데 사용되는 디자인 인터페이스입니다. 데이터 원본, 필요한 변환 및 데이터 대상을 지정합니다. 작업은 디렉터가 예약하고 서버에서 실행하는 실행 파일을 생성하기 위해 컴파일됩니다.
- 감독 : DataStage 서버 작업 및 병렬 작업을 검증, 예약, 실행 및 모니터링하는 데 사용됩니다.

위의 이미지는 방법을 설명합니다. IBM Infosphere DataStage는 Infosphere DataStage의 다른 요소와 상호 작용합니다. IBM 정보 서버 플랫폼. DataStage는 두 섹션으로 구분됩니다. 공유 구성 요소 및 런타임 Archi강의아래 표는 두 섹션 각각이 어떤 역할을 하는지 자세히 보여줍니다.
|
공유 |
통합된 사용자 인터페이스 |
|
|
공통 서비스 |
|
|
|
공통 병렬 처리 |
|
|
|
런타임 Archi강의 |
OSH 스크립트 |
|
DataStage에서 병렬 처리가 작동하는 방식
위의 아키텍처 표에서는 공통 병렬 처리를 공유 서비스로 명시하고 있습니다. 이 섹션에서는 해당 서비스가 실제로 작업을 실행하는 방식을 설명합니다. 이는 개요에서 언급되었던 개념이며, 작업 완료 속도를 결정하는 요소이기 때문입니다.
병렬 작업은 두 가지 메커니즘을 동시에 사용하며, 두 메커니즘 모두 수동으로 코딩하는 것이 아니라 런타임에 자동으로 적용됩니다.
1. 파이프라인 병렬 처리. 작업의 각 단계는 이전 단계가 완료될 때까지 기다리지 않고 동시에 시작됩니다. 소스 단계는 행을 읽어 메모리 파이프라인으로 푸시합니다. 트랜스포머는 첫 번째 행이 도착하는 즉시 시작되어 출력을 두 번째 파이프라인으로 푸시합니다. 대상 커넥터는 그 직후 쓰기 작업을 시작합니다. 중간 랜딩 파일이 생성되지 않으므로 3단계 작업은 읽기, 변환 및 쓰기 단계를 순차적으로 실행하는 대신 중첩하여 실행합니다.
2. 분할 병렬성. 행들은 여러 개의 파티션으로 분할되고, 각 파티션의 노드에서 스테이지 로직 전체 복사본이 실행됩니다. 8개의 파티션은 8개의 Transformer 인스턴스가 동시에 실행됨을 의미합니다. 최종적으로 모든 파티션의 데이터는 대상으로 전달되기 위해 하나의 스트림으로 통합됩니다.
적절한 파티셔닝 방식을 선택하는 것은 개발자가 내리는 가장 중요한 튜닝 결정입니다.
- Auto (자동) : 기본 설정입니다. 엔진은 스테이지의 필요에 따라 메서드를 선택합니다.
- 해시시: 동일한 키 값을 가진 행들을 같은 노드로 보냅니다. 일치하는 키가 모이도록 Join, Aggregator 및 Remove Duplicates를 실행하기 전에 필수적으로 사용해야 합니다.
- 라운드 로빈: 행을 하나씩 균등하게 처리합니다. 키 그룹이 포함된 플랫 파일을 로드하는 데 가장 적합합니다.ping 문제가되지 않는다.
- 전체: 전체 데이터 세트를 모든 노드에 복사합니다. 조회 단계에서 작은 참조 테이블에 사용됩니다.
- 같은: 기존 파티셔닝을 그대로 유지하여 두 단계 간의 불필요한 재파티셔닝을 방지합니다.
- 범위 및 절댓값: 균등한 분포가 필요한 경우, 행을 값 범위 또는 숫자 키 나머지 값으로 분산합니다.
구성 파일(APT_CONFIG_FILE)에는 존재하는 노드의 수가 명시되어 있습니다. 노드 수는 작업 외부에 저장되므로, 컴파일된 동일한 작업은 설계 변경 없이 랩톱 환경에서 프로덕션 그리드 환경으로 확장할 수 있습니다.
이 모든 것을 시도하기 전에 먼저 환경이 조성되어야 합니다.
Datastage 도구의 전제 조건
DataStage의 경우 다음과 같은 설정이 필요합니다.
- 인포스피어
- DataStage 서버 9.1.2 이상
- Microsoft Visual Studio .NET 2010 익스프레스 에디션 C++
- Oracle 클라이언트(인스턴트 클라이언트가 아닌 전체 클라이언트)에 연결하는 경우 Oracle 데이터베이스
- DB2 데이터베이스에 연결하는 경우 DB2 클라이언트
이제 초보자를 위한 DataStage 튜토리얼 시리즈에서는 InfoSphere 정보 서버를 다운로드하고 설치하는 방법을 알아봅니다.
InfoSphere Information Server 다운로드 및 설치
DataStage에 액세스하려면 최신 버전을 다운로드하여 설치하십시오. IBM InfoSphere 서버. 서버는 AIX, Linux 및 Windows 운영 체제. 요구 사항에 따라 선택할 수 있습니다.
이전 버전의 Infosphere에서 새 버전으로 데이터를 마이그레이션하려면 자산 교환 도구를 사용하십시오.
설치 파일
Infosphere Datastage를 설치하고 구성하려면 설정에 다음 파일이 있어야 합니다.
럭셔리 Windows,
- EtlDeploymentPackage-windows-oracle.pkg
- EtlDeploymentPackage-windows-db2.pkg
리눅스의 경우,
- EtlDeploymentPackage-linux-db2.pkg
- EtlDeploymentPackage-linux-oracle.pkg
서버가 설치되면 이 페이지의 나머지 부분에 나오는 예제에서는 변경 데이터 캡처를 사용하므로 빌드하기 전에 변경 데이터가 어떻게 이동하는지 확인하는 것이 도움이 됩니다.
CDC 트랜잭션 단계 작업의 변경 데이터 처리 흐름

위의 그림 trac소스 데이터베이스에서 대상 데이터베이스로의 단일 변경 사항이며, 아래 나열된 순서대로 진행됩니다.
- 데이터베이스용 'InfoSphere CDC' 서비스는 소스 데이터베이스의 변경 사항을 모니터링하고 캡처합니다.
- 복제 정의에 따라 "InfoSphere CDC"는 변경 데이터를 "InfoSphere DataStage용 InfoSphere CDC"로 전송합니다.
- "InfoSphere DataStage용 InfoSphere CDC" 서버는 TCP/IP 세션을 통해 "CDC Transaction stage"로 데이터를 보냅니다. "InfoSphere DataStage용 InfoSphere CDC" 서버는 또한 북마크 정보와 함께 COMMIT 메시지를 보내 캡처된 로그에 트랜잭션 경계를 표시합니다.
- "InfoSphere DataStage용 InfoSphere CDC" 서버에서 보낸 각 COMMIT 메시지에 대해 "CDC 트랜잭션 단계"는 EOW(End-of-Wave) 마커를 생성합니다. 이러한 마커는 대상 데이터베이스 커넥터 단계에 대한 모든 출력 링크에서 전송됩니다.
- "대상 데이터베이스 커넥터 단계"는 모든 입력 링크에서 웨이브 종료 마커를 수신하면 북마크 정보를 북마크 테이블에 쓴 다음 트랜잭션을 대상 데이터베이스에 커밋합니다.
- "InfoSphere DataStage용 InfoSphere CDC" 서버는 "대상 데이터베이스"의 책갈피 테이블에서 책갈피 정보를 요청합니다.
- “InfoSphere DataStage용 InfoSphere CDC” 서버는 책갈피 정보를 수신합니다.
이 정보는 다음과 같은 용도로 사용됩니다.
- 복제가 시작될 때 변경 내용을 읽는 트랜잭션 로그의 시작 지점을 결정합니다.
- 기존 트랜잭션 로그를 정리할 수 있는지 확인하려면
SQL 복제 설정
Datastage를 시작하기 전에 데이터베이스 설정이 필요합니다. 두 개의 DB2 데이터베이스를 생성합니다.
- 하나는 복제 소스 역할을 하고
- 하나를 대상으로 합니다.
또한 두 개의 테이블(제품 및 재고)을 만들고 샘플 데이터로 채웁니다. 그런 다음 다음 간의 통합을 테스트할 수 있습니다. SQL 복제 및 데이터 스테이지.
앞으로는 다음을 생성하여 SQL 복제를 설정합니다. 제어 테이블, 구독 세트, 등록 및 구독 세트 구성원. 다음 섹션에서 이에 대해 더 자세히 알아보겠습니다.
여기서는 소매 판매 품목의 예를 데이터베이스로 사용하고 Inventory 및 Product라는 두 개의 테이블을 생성하겠습니다. 이러한 테이블은 이러한 세트를 통해 소스에서 대상으로 데이터를 로드합니다. (제어 테이블, 구독 세트, 등록 및 구독 세트 구성원.)
단계 1) 다음과 같은 소스 데이터베이스를 생성합니다. 매상. 이 데이터베이스 아래에 두 개의 테이블을 만듭니다. 제품 목록.
단계 2) 다음 명령을 실행하여 SALES 데이터베이스를 생성하세요.
db2 create database SALES
단계 3) SALES 데이터베이스에 대한 보관 로깅을 켭니다. 또한 다음 명령을 사용하여 데이터베이스를 백업합니다.
db2 update db cfg for SALES using LOGARCHMETH3 LOGRETAIN db2 backup db SALES
단계 4) 동일한 명령 프롬프트에서 이전에 실행했던 sqlrepl-datastage-tutorial 디렉터리 내의 setupDB 하위 디렉터리로 이동합니다.trac다운로드한 압축 파일에서 추출했습니다.

단계 5) 다음 명령을 사용하여 인벤토리 테이블을 만들고 다음 명령을 실행하여 테이블에 데이터를 가져옵니다.
db2 import from inventory.ixf of ixf create into inventory
단계 6) 대상 테이블을 생성합니다. 대상 데이터베이스의 이름을 다음과 같이 지정하십시오. STAGEDB.
이제 데이터베이스 소스와 대상을 모두 생성했으므로 이 DataStage 튜토리얼의 다음 단계에서는 이를 복제하는 방법을 살펴보겠습니다.
다음 정보는 도움이 될 수 있습니다. ODBC 데이터 소스 설정 인간을 IBM InfoSphere 정보 서버 설명서.
SQL 복제 객체 생성
아래 이미지는 변경 데이터가 소스 데이터베이스에서 대상 데이터베이스로 전달되는 방식을 보여줍니다. 소스-대상 맵을 생성합니다.ping 테이블 사이는 다음과 같이 알려져 있습니다. 구독 세트 구성원 그리고 멤버들을 하나의 그룹으로 묶습니다. 신청.

InfoSphere CDC(Change Data Capture) 내의 복제 단위를 구독이라고 합니다.
- 소스에서 수행된 변경 사항은 "캡처 제어 테이블"에 캡처되어 CD 테이블로 전송된 다음 대상 테이블로 전송됩니다. 적용 프로그램은 변경이 수행되어야 하는 행에 대한 세부 정보를 갖게 됩니다. 또한 구독 세트에서 CD 테이블을 조인합니다.
- 구독에는 지도가 포함되어 있습니다.ping 원본 데이터 저장소의 데이터가 대상 데이터 저장소에 적용되는 방식을 명시하는 세부 정보입니다. 참고로, CDC는 이제 다른 명칭으로 불립니다. Infosphere 데이터 복제.
- 구독이 실행되면 InfoSphere CDC는 소스 데이터베이스의 변경 사항을 캡처합니다. InfoSphere CDC는 변경 데이터를 대상에 전달하고 대상 데이터베이스의 북마크 테이블에 동기화 지점 정보를 저장합니다.
- InfoSphere CDC는 책갈피 정보를 사용하여 InfoSphere DataStage 작업의 진행 상황을 모니터링합니다.
- 실패 시 북마크 정보를 재시작 시점으로 활용합니다. 이 예에서는 ASN입니다.IBMSNAP_FEEDETL 테이블은 DataStage 관련 동기화 지점 정보를 저장합니다. track DataStage 진행 상황.
이 섹션에서 IBM DataStage 교육 튜토리얼을 사용하려면 다음 작업을 수행해야 합니다.
- 복제 옵션을 저장하기 위한 CAPTURE Control 테이블 및 APPLY CONTROL 테이블 생성
- PRODUCT, INVENTORY 테이블을 복제 소스로 등록
- 두 개의 구성원으로 구독 세트 작성
- 복사 작업 내역 세트 구성원 작성 및 대상 CCD 테이블
ASNCLP 명령줄 프로그램을 사용하여 SQL 복제 설정
단계 1) sqlrepl-datastage-tutorial/setupSQLRep 디렉터리에서 crtCtlTablesCaptureServer.asnclp 스크립트 파일을 찾으세요.
단계 2) 파일에서 교체 그리고 " ”를 SALES 데이터베이스에 연결하기 위한 사용자 ID와 비밀번호로 입력하세요.
단계 3) 디렉토리를 sqlrepl-datastage-tutorial/setupSQLRep 디렉토리로 변경하고 스크립트를 실행합니다. 다음 명령을 사용합니다. 이 명령은 SALES 데이터베이스에 연결하고 Capture 제어 테이블을 만드는 SQL 스크립트를 생성합니다.
asnclp –f crtCtlTablesCaptureServer.asnclp
단계 4) 동일한 디렉터리에서 crtCtlTablesApplyCtlServer.asnclp 스크립트 파일을 찾으세요. 이제 두 인스턴스를 교체하십시오. 그리고 " ”를 STAGEDB 데이터베이스에 연결하기 위한 사용자 ID와 비밀번호로 입력합니다.
단계 5) 이제 동일한 명령 프롬프트에서 다음 명령을 사용하여 적용 제어 테이블을 만듭니다.
asnclp –f crtCtlTablesApplyCtlServer.asnclp
단계 6) crtRegistration.asnclp 스크립트 파일을 찾아 다음의 모든 인스턴스를 바꿉니다. SALES 데이터베이스에 연결하기 위한 사용자 ID로 또한 "를 변경하십시오. "를 연결 비밀번호로 설정합니다.
단계 7) 소스 테이블을 등록하려면 다음 스크립트를 사용합니다. ASNCLP 프로그램은 등록을 만드는 과정의 일부로 두 개의 CD 테이블을 만듭니다. CDPRODUCT 및 CDINVENTORY.
asnclp –f crtRegistration.asnclp
CREATE REGISTRATION 명령은 다음 옵션을 사용합니다.
- 차등 새로 고침: 소스 테이블의 행이 변경되는 경우에만 대상 테이블을 업데이트하도록 Apply 프로그램에 프롬프트를 표시합니다.
- 이미지 둘 다: 변경 전의 소스 컬럼 값과 변경 후의 값을 등록할 때 사용하는 옵션이다.
단계 8) 대상 데이터베이스(STAGEDB)에 연결하려면 다음 단계를 따르세요.
- crtTableSpaceApply.bat 파일을 찾아 텍스트 편집기에서 엽니다.
- 바꾸다 그리고 사용자 ID와 비밀번호로
- DB2 명령 창에서 crtTableSpaceApply.bat를 입력하고 파일을 실행하십시오.
- 이 배치 파일은 대상 데이터베이스(STAGEDB)에 새 테이블스페이스를 생성합니다.
단계 9) crtSubscriptionSetAndAddMembers.asnclp 스크립트 파일을 찾아 다음 변경 작업을 수행합니다.
- 모든 인스턴스 교체 그리고 SALES 데이터베이스에 연결하기 위한 사용자 ID 및 비밀번호(소스)
- 모든 인스턴스 교체 그리고 STAGEDB 데이터베이스(대상)에 연결하기 위한 사용자 ID로
변경 후 스크립트를 실행하여 소스 및 대상 테이블을 그룹화하는 구독 세트(ST00)를 작성하십시오. 또한 스크립트는 수정된 데이터를 저장할 대상 데이터베이스에 두 개의 구독 세트 멤버와 CCD(일관된 변경 데이터)를 작성합니다. 이 데이터는 Infosphere DataStage에서 사용됩니다.
단계 10) 구독 세트, 구독 세트 구성원 및 CCD 테이블을 작성하려면 스크립트를 실행하십시오.
asnclp –f crtSubscriptionSetAndAddMembers.asnclp
구독 세트 및 두 구성원을 생성하는 데 사용되는 다양한 옵션은 다음과 같습니다.
- 응축된 상태에서 완료됨
- 외부
- 부하 유형 가져오기 내보내기
- 연속적인 타이밍
단계 11) 복제 관리 도구의 결함으로 인해. TARGET_CAPTURE_SCHEMA 열을 설정하려면 다른 배치 파일을 실행해야 합니다. IBMSNAP_SUBS_SET 제어 테이블을 null로 설정합니다.
- updateTgtCapSchema.bat 파일을 찾으십시오. 텍스트 편집기에서 엽니다. 바꾸다 그리고 STAGEDB 데이터베이스에 연결하기 위한 사용자 ID로
- DB2 명령 창에서 updateTgtCapSchema.bat 명령을 입력하고 파일을 실행합니다.
CCD 테이블을 DataStage에 매핑하기 위한 정의 파일 생성
다음 단계에서 복제를 수행하기 전에 CCD 테이블을 DataStage와 연결해야 합니다. 이번 섹션에서는 SQL을 DataStage와 연결하는 방법을 살펴보겠습니다.
CCD 테이블을 DataStage와 연결하려면 DataStage 정의(.dsx) 파일을 생성해야 합니다. .dsx 파일 형식은 DataStage에서 작업 정의를 가져오고 내보내는 데 사용됩니다. ASNCLP 스크립트를 사용하여 두 개의 .dsx 파일을 생성합니다. 예를 들어, 여기서는 두 개의 .dsx 파일을 생성했습니다.
- stagedb_AQ00_SET00_sJobs.dsx: XNUMX개의 병렬 작업의 워크플로를 지시하는 작업 시퀀스를 만듭니다.
- stagedb_AQ00_SET00_pJobs.dsx : XNUMX개의 병렬 작업을 생성합니다.
ASNCLP 프로그램은 CCD 열을 Datastage 열 형식에 자동으로 매핑합니다. ASNCLP가 실행되는 경우에만 지원됩니다. Windows, Linux 또는 Unix 절차.

Datastage 작업은 CCD 테이블에서 행을 가져옵니다.
- 한 작업은 DataStage가 ex에서 중단된 지점에 동기화 지점을 설정합니다.trac두 테이블에서 데이터를 가져옵니다. 이 작업은 ST00 구독 세트의 SYNCHPOINT 값을 선택하여 이 정보를 얻습니다. IBMSNAP_SUBS_SET 테이블을 만들고 이를 MAX_SYNCHPOINT 열에 삽입합니다. IBMSNAP_FEEDETL 테이블.
- 두 가지 직업tracPRODUCT_CCD 및 INVENTORY_CCD 테이블의 데이터를 사용합니다. 작업은 어떤 행부터 시작해야 하는지 알고 있습니다.tracMIN_SYNCHPOINT 및 MAX_SYNCHPOINT 값을 선택하여 설정합니다. IBM구독 세트에 대한 SNAP_FEEDETL 테이블입니다.
정의 매핑이 완료되었으므로 이제 복제를 시작하여 CCD 테이블이 채워지기 시작합니다.
복제 시작
복제를 시작하려면 아래 단계를 사용합니다. CCD 테이블이 데이터로 채워지면 복제 설정이 검증되었음을 나타냅니다. 대상 CCD 테이블의 복제된 데이터를 보려면 DB2 제어 센터 그래픽 사용자 인터페이스를 사용하십시오.
단계 1) 그렇지 않은 경우 DB2가 실행 중인지 확인한 다음 사용하십시오. DB2 시작 명령.
단계 2) 그런 다음 운영 체제 프롬프트에서 asncap 명령을 사용하여 프로그램 캡처를 시작합니다. 예를 들어.
asncap capture_server=SALES
위 명령은 SALES 데이터베이스를 Capture 서버로 지정합니다. 캡처가 실행되는 동안 명령 창을 열어 두십시오.
단계 3) 이제 새 명령 프롬프트를 엽니다. 그런 다음 적용 asnapply 명령을 사용하여 프로그램합니다.
asnapply control_server=STAGEDB apply_qual=AQ00

- 이 명령은 STAGEDB 데이터베이스를 Apply 제어 서버(Apply 제어 테이블을 포함하는 데이터베이스)로 지정합니다.
- Apply 규정자로서의 AQ00(이 제어 테이블 세트에 대한 식별자)
Apply가 실행 중인 상태에서 명령 창을 열어 둡니다.
단계 4) 이제 다른 명령 프롬프트를 열고 db2cc 명령을 실행하여 DB2 제어 센터를 시작하십시오. 기본 제어 센터를 수락합니다.
단계 5) 이제 왼쪽 탐색 트리에서 All Databases > STAGEDB를 연 다음 Tables를 클릭합니다. Double 테이블 이름(제품 CCD)을 클릭하여 테이블을 엽니다. 다음과 같이 보일 것입니다.

마찬가지로, INVENTORY에 대한 CCD 테이블을 열 수도 있습니다.

이제 복제 데이터가 CCD 테이블에 반영되므로 데이터베이스 측에서 DataStage 클라이언트로 관심이 옮겨갑니다.
Datastage 도구에서 프로젝트를 만드는 방법
먼저 DataStage에서 프로젝트를 생성합니다. 이를 위해서는 InfoSphere DataStage 관리자여야 합니다.
설치 및 복제가 완료되면 프로젝트를 생성해야 합니다. DataStage에서 프로젝트는 데이터를 구성하는 방법입니다. 여기에는 특정 프로젝트의 데이터 파일, 단계 및 빌드 작업 정의가 포함됩니다.
DataStage에서 프로젝트를 만들려면 다음 단계를 따르세요.
1단계) DataStage 소프트웨어 실행
DataStage 및 QualityStage 관리자를 시작합니다. 그런 다음 시작 > 모든 프로그램 >을 클릭합니다. IBM 정보 서버 > IBM WebSphere DataStage 및 QualityStage 관리자.
2단계) DataStage 서버와 클라이언트 연결
DataStage 클라이언트에서 DataStage 서버에 연결하려면 도메인 이름, 사용자 ID, 비밀번호, 서버 정보 등의 세부 정보를 입력하세요.
3단계) 새 프로젝트 추가
WebSphere DataStage 관리 창에서. 프로젝트 탭을 클릭한 다음 추가를 클릭합니다.
4단계) 프로젝트 세부 정보 입력
WebSphere DataStage 관리 창에서 다음과 같은 세부 정보를 입력합니다.
- 이름
- 파일 위치
- '확인'을 클릭하십시오

각 프로젝트에는 다음이 포함됩니다.
- DataStage 작업
- 내장 구성 요소. 이는 작업에 사용되는 사전 정의된 구성요소입니다.
- 사용자 정의 구성요소. 이는 DataStage Manager 또는 DataStage Designer를 사용하여 생성된 사용자 정의 구성 요소입니다.
Datastage Infosphere에서 복제 작업을 가져오는 방법을 살펴보겠습니다.
Datastage 및 QualityStage Designer에서 복제 작업을 가져오는 방법
다음 위치에서 작업을 가져옵니다. IBM InfoSphere DataStage 및 QualityStage Designer 클라이언트. 그리고 당신은 그것을 실행합니다. IBM InfoSphere DataStage 및 QualityStage Director 클라이언트.
디자이너이자 의뢰인인 사람은 마치 건축 작업을 위한 백지 캔버스와 같습니다.trac데이터를 변환, 로드 및 품질 검사하는 기능을 제공합니다. Job의 기본 구성 요소를 이루는 도구를 포함합니다.
- 인턴십: 데이터 소스에 연결하여 파일을 읽거나 쓰고, 데이터를 처리합니다.
- 링크: 데이터가 흐르는 단계를 연결합니다.
InfoSphere DataStage 및 QualityStage Designer 클라이언트의 스테이지는 Designer 도구 팔레트에 저장됩니다.
InfoSphere QualityStage에는 다음 단계가 포함됩니다.
- 조사단계
- 표준화 단계
- 일치 빈도 단계
- 원소스 매치 스테이지
- 투 소스 매치 스테이지
- 서바이벌 스테이지
- 표준화 품질 평가(SQA) 단계
DataStage Infosphere에서는 4가지 유형의 작업을 생성할 수 있습니다.
- 병렬 작업
- 시퀀스 작업
- 메인프레임 작업
- 서버 작업
복제 작업 파일을 가져오는 방법을 단계별로 살펴보겠습니다.
단계 1) DataStage 및 QualityStage 디자이너를 시작합니다. 시작 > 모든 프로그램 >을 클릭합니다. IBM 정보 서버 > IBM WebSphere DataStage 및 QualityStage 디자이너
단계 2) 프로젝트에 첨부 창에서 다음 세부 정보를 입력합니다.
- 도메인
- 사용자 이름
- 비밀번호
- 프로젝트 이름
- OK

단계 3) 이제 파일 메뉴에서 가져오기를 클릭하세요. -> DataStage 구성 요소.
새로운 DataStage 저장소 가져오기 창이 열립니다.
- 이 창에서 찾아보기 STAGEDB_AQ00_ST00_sJobs.dsx 이전에 만든 파일
- '모두 가져오기' 옵션을 선택하세요.
- "영향 분석 수행" 체크박스를 선택합니다.
- '확인'을 클릭합니다.

작업을 가져오면 DataStage는 STAGEDB_AQ00_ST00_sequence 작업을 생성합니다.
단계 4) 동일한 단계에 따라 STAGEDB_AQ00_ST00_pJobs.dsx 파일. 이 가져오기를 통해 XNUMX개의 병렬 작업이 생성됩니다.
단계 5) Designer Repository 창 아래 -> SQLREP 폴더를 엽니다. 폴더 안에는 Sequence Job과 XNUMX개의 병렬 작업이 표시됩니다.
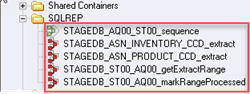
단계 6) 시퀀스 작업을 보려면 저장소 트리로 이동하여 STAGEDB_AQ00_ST00_sequence 작업을 마우스 오른쪽 버튼으로 클릭하고 편집을 클릭합니다. 작업 순서가 제어하는 XNUMX개 병렬 작업의 워크플로를 보여줍니다.

각 아이콘은 무대이며,
- getExtract범위 단계: 업데이트됩니다. IBMSNAP_FEEDETL 테이블입니다. 이 테이블은 데이터의 시작점을 설정합니다.tracDataStage가 마지막으로 실행된 시점까지trac행을 나열하고 구독 세트에 대해 처리된 마지막 거래를 종료 지점으로 설정합니다.
- getExtractRangeSuccess이 단계는 시작점을 ex에 제공합니다.tractFromINVENTORY_CCD 단계 및 extractFromPRODUCT_CCD 단계
- 알렉스tracts성공: 이 단계는 전과자 모두를 보장합니다.tractFromINVENTORY_CCD 및 extractFromPRODUCT_CCD 작업이 성공적으로 완료되었습니다. 그런 다음 가져온 마지막 행에 대한 동기화 지점을 setRangeProcessed 단계로 전달합니다.
- setRangeProcessed 단계: 업데이트됩니다 IBMSNAP_FEEDETL 테이블입니다. 따라서 DataStage는 다음 데이터 처리 단계를 어디서부터 시작해야 하는지 알 수 있습니다.trac기
단계 7) 병렬 작업을 보려면 STAGEDB_ASN_INVENTORY_CCD를 마우스 오른쪽 버튼으로 클릭하고 저장소 아래에서 편집을 선택합니다. 아래와 같이 창이 열립니다.

위 이미지에서는 Inventory CCD 테이블의 데이터와 SyncFEEDETL 테이블의 h 포인트 세부정보가 Lookup_6 단계로 렌더링됩니다.
가져온 작업들이 여전히 아무것도 가리키지 않으므로, 다음 단계로 데이터 연결 객체를 정의해야 합니다.
DataStage에서 STAGEDB 데이터베이스로의 데이터 연결 생성
이제 다음 단계는 InfoSphere DataStage와 SQL 복제 대상 데이터베이스 간의 데이터 연결을 구축하는 것입니다. 여기에는 CCD 테이블이 포함됩니다.
DataStage에서는 관련 커넥터 단계가 있는 데이터 연결 개체를 사용하여 작업 디자인의 데이터 소스에 대한 연결을 빠르게 정의합니다.
단계 1) STAGEDB에는 DataStage가 데이터를 동기화하는 데 사용하는 Apply 제어 테이블이 모두 포함되어 있습니다.trac데이터가 추출된 CCD 테이블과trac테드. 다음 명령어를 사용하세요.
db2 catalog tcpip node SQLREP remote ip_address server 50000 db2 catalog database STAGEDB as STAGEDB2 at node SQLREP
주의 사항: STAGEDB가 생성된 시스템의 IP 주소
단계 2) 파일 > 새로 만들기 > 기타 > 데이터 연결을 클릭합니다.
단계 3) 매개변수와 일반이라는 두 개의 탭이 있는 창이 나타납니다.

단계 4) 이 단계에서,
- 일반적으로 탭에서 데이터 연결 이름을 sqlreplConnect로 지정합니다.
- 아래와 같이 매개변수 탭에서
- '스테이지 유형을 사용하여 연결' 필드 옆에 있는 찾아보기 버튼을 클릭하고
- 열린 창에서 저장소 트리를 스테이지 유형 –> 병렬 – > 데이터베이스 —-> DB2 커넥터로 이동합니다.
- 열기를 클릭합니다.

단계 5) 연결 매개변수 표에서 다음과 같은 세부 정보를 입력합니다.
- 연결 고리: 스테이지DB2
- ID / Username: STAGEDB 데이터베이스에 접속하기 위한 사용자 ID
- 비밀번호: STAGEDB 데이터베이스에 연결하기 위한 비밀번호
- 예: STAGEDB 데이터베이스를 포함하는 DB2 인스턴스의 이름
단계 6) 다음 창에서 데이터 연결을 저장합니다. '저장' 버튼을 클릭하세요.
STAGEDB에서 DataStage로 테이블 정의 가져오기
이전 단계에서는 InfoSphere DataStage와 STAGEDB 데이터베이스가 연결되어 있음을 확인했습니다. 이제 PRODUCT_CCD 및 INVENTORY_CCD 테이블에 대한 열 정의와 기타 메타데이터를 Information Server 저장소로 가져옵니다.
디자이너 창에서 아래 단계를 따르세요.
단계 1) 가져오기 > 테이블 정의 > 커넥터 가져오기 마법사 시작을 선택합니다.
단계 2) 마법사의 커넥터 선택 페이지에서 DB2 커넥터를 선택하고 다음을 클릭하십시오.

단계 3) 연결 세부정보 페이지에서 로드를 클릭하세요. 그러면 이전 장에서 생성한 데이터 연결의 연결 정보로 마법사 필드가 채워집니다.

단계 4) 같은 페이지에서 연결 테스트를 클릭합니다. 그러면 DataStage가 STAGEDB 데이터베이스에 대한 연결을 시도하라는 메시지가 표시됩니다. "연결이 성공했습니다"라는 메시지를 볼 수 있습니다. 다음을 클릭하세요.

단계 5) 데이터 원본 위치 페이지에서 호스트 이름 및 데이터베이스 이름 필드가 올바르게 채워졌는지 확인하세요. 그런 다음 다음을 클릭하세요.
단계 6) 스키마 페이지에서. ASN(Apply 제어 테이블)의 스키마를 입력하거나 ASN 스키마가 스키마 필드에 미리 채워져 있는지 확인하십시오. 그런 다음 다음을 클릭하세요. 선택 페이지에는 ASN 스키마에 정의된 테이블 목록이 표시됩니다.

단계 7) 메타데이터를 가져와야 하는 첫 번째 테이블은 다음과 같습니다. IBMSNAP_FEEDETL은 적용 제어 테이블입니다. 이 테이블에는 DataStage가 동기화를 유지할 수 있도록 하는 동기화 지점에 대한 세부 정보가 포함되어 있습니다. traccCD 테이블에서 가져온 행의 k개를 선택합니다. IBMSNAP_FEEDETL을 입력하고 다음을 클릭하세요.
단계 8) 가져오기를 완료하려면 IBMSNAP_FEEDETL 테이블 정의. 가져오기를 클릭한 다음 열린 창에서 열기를 클릭합니다.
단계 9) 1-8단계를 두 번 더 반복하여 PRODUCT_CCD 테이블에 대한 정의를 가져온 다음 INVENTORY_CCD 테이블에 대한 정의를 가져옵니다.
주의사항: 재고 및 제품에 대한 정의를 가져오는 동안 스키마를 ASN에서 PRODUCT_CCD 및 INVENTORY_CCD가 생성된 스키마로 변경해야 합니다.
이제 DataStage는 SQL 복제 대상 데이터베이스에 연결하는 데 필요한 모든 세부 정보를 갖추었습니다.
DataStage 작업에 대한 속성 설정
우리가 보유하고 있는 XNUMX개의 DataStage 병렬 작업 각각에는 STAGEDB 데이터베이스와 연결되는 하나 이상의 단계가 포함되어 있습니다. 연결 정보를 추가하고 DataStage가 채우는 데이터 세트 파일에 연결하려면 스테이지를 수정해야 합니다.
스테이지에는 편집 가능한 사전 정의된 속성이 있습니다. 여기서는 STAGEDB_ASN_PRODUCT_CCD_ex의 이러한 속성 중 일부를 변경해 보겠습니다.tract 병렬 작업.
단계 1) Designer 리포지토리 트리를 탐색합니다. SQLREP 폴더 아래에서 STAGEDB_ASN_PRODUCT_CCD_ex를 선택합니다.trac병렬 작업입니다. 편집하려면 작업을 마우스 오른쪽 버튼으로 클릭합니다. 병렬 작업의 디자인 창이 디자이너 팔레트에 열립니다.
단계 2) 녹색 아이콘을 찾으세요. 이 아이콘은 DB2 커넥터 단계를 나타냅니다. 예를 들어 다음과 같은 용도로 사용됩니다.tracCCD 테이블에서 데이터를 가져옵니다. Double- 아이콘을 클릭하세요. 스테이지 편집기 창이 열립니다.


단계 3) 편집기에서 로드를 클릭하여 필드를 연결 정보로 채웁니다. 단계 편집기를 닫고 변경 사항을 저장하려면 확인을 클릭하세요.
단계 4) 이제 STAGEDB_ASN_PRODUCT_CCD_ex의 디자인 창으로 돌아가십시오.trac병렬 작업을 실행하세요. 가져오기 아이콘을 찾으세요.SynchPoints DB2 커넥터 단계. 그런 다음 아이콘을 두 번 클릭합니다.
단계 5) 이제 로드 버튼을 클릭하여 필드를 연결 정보로 채웁니다.
주의사항: Apply 제어 서버로 STAGEDB 이외의 데이터베이스를 사용하는 경우. 그런 다음 get에 대한 연결 정보를 로드하는 옵션을 선택합니다.SyncCCD 테이블이 아닌 제어 테이블과 상호 작용하는 hPoints 단계.
단계 6) 이 단계에서,
- InfoSphere DataStage가 실행되는 시스템에 빈 텍스트 파일을 만듭니다.
- 이 파일의 이름을 productdataset.ds로 지정하고 저장한 위치를 기록해 두세요.
- DataStage는 CCD 테이블에서 변경 사항을 가져온 후 이 파일에 변경 사항을 기록합니다.
- 연결된 작업 간에 데이터를 이동하는 데 사용되는 데이터 세트 또는 파일을 영구 데이터 세트라고 합니다. DataSet 스테이지로 표현됩니다.
단계 7) 이제 디자인 창에서 스테이지 편집기를 열고 insert_into_a_dataset 아이콘을 두 번 클릭합니다. 그러면 다른 창이 열립니다.

단계 8) 이 창에서

- 속성 탭에서 다음을 확인하세요. Target 폴더가 열려 있고 File = DATASETNAME 속성이 강조 표시되어 있습니다.
- 오른쪽에는 파일 필드가 있습니다.
- productdataset.ds 파일의 전체 경로를 입력하세요.
- '확인'을 클릭하십시오.
이제 제품 CCD 테이블에 필요한 모든 속성을 업데이트했습니다. 디자인 창을 닫고 모든 변경 사항을 저장합니다.
단계 9) 이제 STAGEDB_ASN_INVENTORY_CCD_ex 파일을 찾아 엽니다.trac디자이너의 저장소 창에서 병렬 작업을 선택하고 3~8단계를 반복합니다.
주의사항:
- 가져오기를 위해서는 제어 서버 데이터베이스에 대한 연결 정보를 스테이지 편집기에 로드해야 합니다.SynchPoints 단계. 제어 서버가 STAGEDB가 아닌 경우.
- STAGEDB_ST00_AQ00_getEx의 경우tractRange 및 STAGEDB_ST00_AQ00_markRangeProcessed 병렬 작업을 실행하고 모든 DB2 커넥터 단계를 엽니다. 그런 다음 로드 기능을 사용하여 STAGEDB 데이터베이스에 대한 연결 정보를 추가합니다.
이제 모든 속성이 설정되었으므로 작업을 컴파일하고 실행할 수 있습니다.
DataStage 작업 컴파일 및 실행
DataStage 작업이 컴파일될 준비가 되면 Designer는 입력, 변환, 표현식 및 기타 세부 정보를 검토하여 작업 디자인을 검증합니다.
작업 컴파일이 성공적으로 완료되면 실행할 준비가 된 것입니다. XNUMX개 작업을 모두 컴파일하지만 "작업 시퀀스"만 실행합니다. 이는 이 작업이 XNUMX개의 병렬 작업을 모두 제어하기 때문입니다.
단계 1) SQLREP 폴더 아래. (Cntrl+Shift). 그런 다음 마우스 오른쪽 버튼을 클릭하고 다중 작업 컴파일 옵션을 선택합니다.

단계 2) DataStage 컴파일 마법사에서 XNUMX개의 작업이 선택되어 있는 것을 볼 수 있습니다. 다음을 클릭하세요.

단계 3) 컴파일이 시작되고 완료되면 "성공적으로 컴파일되었습니다"라는 메시지가 표시됩니다.

단계 4) 이제 DataStage 및 QualityStage Director를 시작하십시오. 시작 > 모든 프로그램 >을 선택합니다. IBM 정보 서버 > IBM WebSphere DataStage 및 QualityStage 디렉터.
단계 5) 왼쪽의 프로젝트 탐색 창에서. SQLREP 폴더를 클릭합니다. 그러면 XNUMX개 작업이 모두 디렉터 상태 테이블에 표시됩니다.
단계 6) STAGEDB_AQ00_S00_sequence 작업을 선택합니다. 메뉴 표시줄에서 작업 > 지금 실행을 클릭합니다.

컴파일이 완료되면 완료된 상태를 볼 수 있습니다.

이제 PRODUCT_CCD 및 INVENTORY_CCD 테이블에 저장된 변경된 행이 제대로 반영되었는지 확인하십시오.tracDataStage에서 추출하여 두 개의 데이터 세트 파일에 삽입했습니다.
단계 7) 디자이너로 돌아가서 STAGEDB_ASN_PRODUCT_CCD_ex를 엽니다.tract 작업. 스테이지 에디터를 열려면 Double-insert_into_a_dataset 아이콘을 클릭합니다. 그런 다음 데이터 보기를 클릭하세요.
단계 8) 표시할 행 창에서 기본값을 수락합니다. 그런 다음 확인을 클릭합니다. 데이터 브라우저 창이 열려 데이터 세트 파일의 내용이 표시됩니다.

SQL 복제와 DataStage 간의 통합 테스트
이전 단계에서는 작업을 컴파일하고 실행했습니다. 이번 섹션에서는 SQL 복제와 DataStage의 통합을 확인해 보겠습니다. 이를 위해 소스 테이블을 변경하고 동일한 변경 사항이 DataStage에 업데이트되는지 확인합니다.
단계 1) 운영 체제에 맞는 sqlrepl-datastage-scripts 폴더로 이동합니다.
단계 2) 다음 단계에 따라 SQL 복제를 시작하세요.
- startSQLCapture.bat를 실행합니다(Windows) 파일을 사용하여 SALES 데이터베이스에서 Capture 프로그램을 시작하십시오.
- startSQLApply.bat를 실행합니다(Windows) 파일을 사용하여 STAGEDB 데이터베이스에서 Apply 프로그램을 시작합니다.
단계 3) 이제 updateSourceTables.sql 파일을 엽니다. SALES 데이터베이스에 연결하려면 그리고 사용자 ID와 비밀번호로.
단계 4) DB2 명령 창을 여십시오. 디렉터리를 sqlrepl-datastage-tutorial\scripts로 변경하고 지정된 명령으로 문제를 실행합니다.
db2 -tvf updateSourceTables.sql
SQL 스크립트는 Sales 데이터베이스의 두 테이블(PRODUCT, INVENTORY)에 대한 업데이트, 삽입, 삭제 등 다양한 작업을 수행합니다.
단계 5) DataStage가 실행 중인 시스템에서. DataStage Director를 열고 STAGEDB_AQ00_S00_sequence 작업을 실행합니다. 작업 > 지금 실행을 클릭합니다.

작업을 실행하면 다음 활동이 수행됩니다.
- Capture 프로그램은 SALES 데이터베이스 로그에서 XNUMX개 행 변경 사항을 읽고 이를 CD 테이블에 삽입합니다.
- Apply 프로그램은 SALES의 CD 테이블에서 변경 행을 페치하여 STAGEDB의 CCD 테이블에 삽입합니다.
- 두 개의 DataStage extract 작업은 CCD 테이블의 변경 사항을 가져와 productdataset.ds 및 inventory dataset.ds 파일에 기록합니다.
데이터 세트를 보면 위 단계가 수행되었음을 확인할 수 있습니다.
단계 6) 아래 단계를 따르십시오.
- 디자이너를 시작합니다. STAGEDB_ASN_PRODUCT_CCD_ex를 엽니다.tract 직업.
- 그때 Double-insert_into_a_dataset 아이콘을 클릭합니다. 무대 편집기에서. 데이터 보기를 클릭합니다.
- 표시할 행 창에서 기본값을 수락하고 확인을 클릭합니다.
데이터 세트에는 세 개의 새로운 행이 포함되어 있습니다. 변경 사항이 구현되었는지 확인하는 가장 쉬운 방법은 데이터 브라우저의 오른쪽 끝으로 스크롤하는 것입니다. 이제 마지막 세 행을 살펴보세요(아래 이미지 참조).

문자 I, U, D는 각각의 새 행을 생성하는 INSERT, UPDATE, DELETE 작업을 지정합니다.
Inventory 테이블에 대해서도 동일한 검사를 수행할 수 있습니다.
DataStage와 다른 인기 있는 ETL 도구 비교
엔드투엔드 워크플로우가 제대로 작동하면, 다음으로 흔히 나오는 질문은 DataStage가 팀에서 이미 보유하고 있는 다른 대안들과 비교했을 때 어떤 위치에 있는지입니다. 아래 표는 구매 결정에 가장 큰 영향을 미치는 기준들을 바탕으로 DataStage를 널리 사용되는 세 가지 플랫폼과 비교한 것입니다.
| 기준 | IBM 데이터스테이지 | 정보학 파워센터 | 탈 렌드 | SSIS |
|---|---|---|---|---|
| 처리 모델 | 파이프라인과 파티션 병렬 처리 | 메타데이터 기반 파티셔닝 | 생성 Java or Spark 암호 | 메모리 내 데이터 흐름 |
| 최고의 핏 | 대규모 엔터프라이즈 배치 및 CDC 워크로드 | 복잡한 레거시 아키텍처와 엄격한 관리 체계 | 클라우드 네이티브 및 비용에 민감한 팀 | Microsoft SQL Server 부동산 |
| Licensing | 상업용, 프리미엄 등급 | 상업 보험 | 오픈소스 에디션과 상용 버전 | SQL Server에 포함되어 있습니다. |
| 학습 곡선 | Steep ETL 전문가 모집 | 험한 | 난이도는 보통이며, 코딩 능력이 도움이 됩니다. | 보통 |
| 데이터 품질 | QualityStage가 제품군에 포함되어 있습니다. | 별도의 데이터 품질 제품 | Talend 데이터 품질이 포함되어 있습니다. | 추가 구성 요소 |
요약하자면, DataStage는 라이선스 비용보다 처리량, 메인프레임 접근성, 감사 준비가 완료된 데이터 계보가 더 중요한 경우에 선택됩니다. 주로 클라우드 환경에서 작업하는 팀에게 적합합니다. 데이터 레이크 아키텍처 또는 예를 비교하는 것trac먼저 순서를 정하면 장단점을 파악할 수 있습니다. ETL 대 ELT 더욱 관련성이 높고, 더 폭넓은 후보 목록이 요약본에 포함되어 있습니다. ETL 도구 데이터 통합 도구.