Bubble 정렬 알고리즘 Python 목록 예제 사용
⚡ 스마트 요약
BubbleSort는 인접한 값을 반복적으로 비교하고 교환하여 목록 항목을 오름차순으로 정렬합니다.ping 왼쪽 요소가 더 클 때 정렬합니다. 이 간단한 비교 정렬 방식은 작거나 거의 정렬된 데이터 세트에 적합하며 핵심 정렬 논리를 효과적으로 학습할 수 있도록 도와줍니다.

무엇이 Bubbl전자 정렬?
Bubble 정렬 오름차순 정렬은 인접한 두 값을 비교하여 리스트 항목을 정렬하는 알고리즘입니다. 첫 번째 값이 두 번째 값보다 크면 첫 번째 값이 두 번째 값의 위치를 차지하고, 두 번째 값이 첫 번째 값의 위치를 차지합니다. 첫 번째 값이 두 번째 값보다 작으면 위치 교환은 없습니다.ping 수행.
이 프로세스는 목록의 모든 값이 비교되고 필요한 경우 교체될 때까지 반복됩니다. 각 반복을 일반적으로 패스라고 합니다. 버블 정렬의 패스 수는 목록의 요소 수에서 XNUMX을 뺀 것과 같습니다.
이번에 Bubble 정렬 중 Python 지도 시간 이 글을 통해 여러분은 이 코드가 해결하는 문제, 최적화된 형태, 단계별 시각적 설명, 그리고 작동하는 예제를 배우게 될 것입니다. Python 프로그램과 그 성능 특성.
구현 Bubble 정렬 알고리즘
우리는 구현을 세 단계(3)로 나누어 진행할 것입니다. 즉, 문제, 해결책, 그리고 어떤 언어에 대해서든 코드를 작성하는 데 사용할 수 있는 알고리즘입니다.
문제
주어진 항목들을 무작위 순서로 배열하고 싶습니다.
다음 목록을 고려해 보세요.
[21, 6, 9, 33, 3]
해법
리스트를 순회하며 인접한 두 요소를 비교하고 서로 바꿉니다.ping 첫 번째 값이 두 번째 값보다 크면 그 값을 사용합니다.
결과는 다음과 같아야 합니다.
[3, 6, 9, 21, 33]
암호알고리즘
버블 정렬 알고리즘은 다음과 같이 작동합니다.
단계 1) 요소의 총 개수를 구하세요. 주어진 목록에 있는 항목의 총 개수를 구하세요.
단계 2) 수행해야 할 외부 패스의 횟수(n-1)를 결정합니다. 그 길이는 리스트에서 1을 뺀 값입니다.
단계 3) 외부 패스 1에 대해 내부 패스를 (n-1)번 수행합니다. 첫 번째 요소 값을 가져와 두 번째 값과 비교합니다. 두 번째 값이 첫 번째 값보다 작으면 위치를 바꿉니다.
단계 4) 3단계 과정을 반복하여 가장 바깥쪽 단계(n-1)에 도달합니다. 목록에서 다음 요소를 가져온 다음, 모든 값이 올바른 오름차순으로 정렬될 때까지 3단계에서 수행한 과정을 반복합니다.
단계 5) 모든 단계가 완료되면 결과를 반환합니다. 정렬된 목록의 결과를 반환합니다.
단계 6) 알고리즘 최적화.
목록이나 인접 값이 이미 정렬된 경우 불필요한 내부 전달을 피하세요. 예를 들어, 제공된 목록에 오름차순으로 정렬된 요소가 이미 포함되어 있는 경우 루프를 조기에 중단할 수 있습니다.
최적화 Bubble 정렬 알고리즘
기본적으로 버블 정렬 알고리즘은 Python 목록이 이미 정렬되었는지 여부와 관계없이 목록의 모든 항목을 비교합니다. 주어진 목록이 이미 정렬된 경우 모든 값을 비교하는 것은 시간과 리소스의 낭비입니다.
버블 정렬을 최적화하면 불필요한 반복을 방지하고 시간과 리소스를 절약하는 데 도움이 됩니다.
예를 들어 첫 번째 항목과 두 번째 항목이 이미 정렬되어 있으면 나머지 값을 반복할 필요가 없습니다. 아래 그림과 같이 반복이 종료되고 프로세스가 완료될 때까지 다음 반복이 시작됩니다. Bubble 정렬 예.
최적화는 다음 단계를 통해 수행됩니다.
단계 1) 스왑이 발생하는지 여부를 모니터링하는 플래그 변수를 생성합니다.ping 내부 루프에서 발생했습니다.
단계 2) 값들의 위치가 바뀌었다면 다음 반복으로 진행합니다.
단계 3) 값이 서로 위치를 바꾸지 않았다면 내부 루프를 종료하고 외부 루프를 계속 진행합니다.
최적화된 버블 정렬은 필요한 단계만 실행하고 필요하지 않은 단계는 건너뛰기 때문에 더 효율적입니다.
시각적 표현
다섯 개의 요소로 이루어진 리스트가 주어졌을 때, 다음 이미지는 버블 정렬이 정렬 과정에서 값들을 순회하는 방식을 보여줍니다.
다음 이미지는 정렬되지 않은 목록을 보여줍니다.

첫 번째 반복
단계 1)

값 21과 6을 비교하여 어느 것이 다른 것보다 큰지 확인합니다.

21은 6보다 크므로 21은 6이 차지했던 자리를 차지하고 6은 21이 차지했던 자리를 차지합니다.

수정된 목록은 이제 위와 같습니다.
단계 2)
값 21과 9가 비교됩니다.

21은 9보다 크므로 21과 9의 위치를 바꿉니다.

새로운 목록은 위와 같습니다.
단계 3)

21과 33의 값을 비교하여 더 큰 값을 찾습니다.

33이라는 값은 21보다 크므로 교환은 없습니다.ping 이루어집니다.
단계 4)

33과 3의 값을 비교하여 더 큰 값을 찾습니다.

값 33은 3보다 크므로 위치를 바꿉니다.

첫 번째 반복이 끝난 후 정렬된 목록은 위와 같습니다.
두 번째 반복
두 번째 반복 후의 새로운 목록은 다음과 같습니다.

세 번째 반복
세 번째 반복 후의 새로운 목록은 다음과 같습니다.

네 번째 반복
네 번째 반복 후의 새로운 목록은 다음과 같습니다.

Python 예
다음 코드는 구현 방법을 보여줍니다 Bubble 정렬 알고리즘 Python.
def bubbleSort(theSeq): n = len(theSeq) for i in range(n - 1): flag = 0 for j in range(n - 1): if theSeq[j] > theSeq[j + 1]: tmp = theSeq[j] theSeq[j] = theSeq[j + 1] theSeq[j + 1] = tmp flag = 1 if flag == 0: break return theSeq el = [21, 6, 9, 33, 3] result = bubbleSort(el) print(result)
위의 버블 정렬 프로그램을 실행하면 Python 다음과 같은 결과를 생성합니다.
[3, 6, 9, 21, 33]
Code 설명
에 대한 설명은 Python Bubbl정렬 프로그램 코드는 다음과 같습니다.
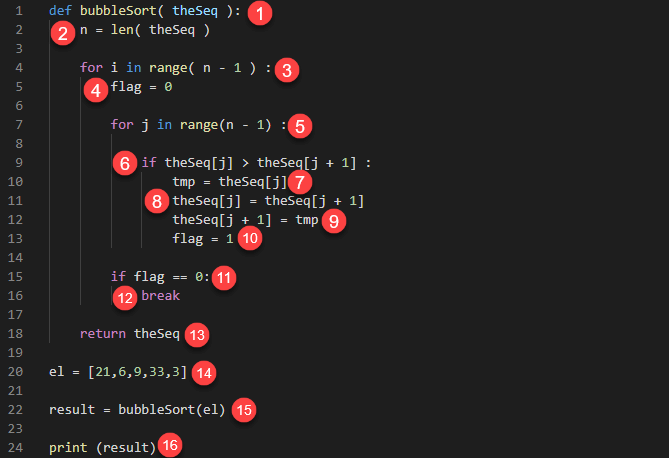
이리,
- 매개변수 theSeq를 허용하는 bubbleSort 함수를 정의합니다. 코드는 아무것도 출력하지 않습니다.
- 배열의 길이를 구해서 변수 n에 할당합니다. 코드는 아무것도 출력하지 않습니다.
- 버블 정렬 알고리즘을 (n-1)번 실행하는 for 루프를 시작합니다. 이것은 가장 바깥쪽 루프입니다. 이 코드는 아무것도 출력하지 않습니다.
- 스왑이 발생했는지 여부를 판단하는 데 사용될 플래그 변수를 정의합니다. 이는 최적화를 위한 것이며, 코드는 아무런 출력도 하지 않습니다.
- 목록의 모든 값을 첫 번째부터 마지막까지 비교하는 내부 루프를 시작합니다. 코드는 아무것도 출력하지 않습니다.
- if 문을 사용하여 왼쪽 값이 바로 오른쪽 값보다 큰지 확인합니다. 코드는 아무것도 출력하지 않습니다.
- 조건이 참으로 평가되면 theSeq[j]의 값을 임시 변수 tmp에 할당합니다. 이 코드는 아무것도 출력하지 않습니다.
- theSeq[j + 1]의 값이 theSeq[j]의 위치에 할당됩니다. 코드는 아무것도 출력하지 않습니다.
- 변수 tmp의 값이 theSeq[j + 1] 위치에 할당됩니다. 코드는 아무것도 출력하지 않습니다.
- 플래그 변수에는 교환이 발생했음을 나타내기 위해 값 1이 할당됩니다. 코드는 아무것도 출력하지 않습니다.
- if 문을 사용하여 변수 flag의 값이 0인지 확인합니다. 코드는 아무것도 출력하지 않습니다.
- 값이 0이면 내부 루프에서 벗어나는 break 문을 호출합니다.
- 정렬된 후 theSeq의 값을 반환합니다. 코드는 정렬된 목록을 출력합니다.
- 난수 목록을 포함하는 변수 el을 정의합니다. 코드는 아무것도 출력하지 않습니다.
- bubbleSort 함수의 값을 변수 결과에 할당합니다.
- 변수 결과의 값을 인쇄합니다.
Bubbl전자 정렬의 장점
버블 정렬 알고리즘의 장점은 다음과 같습니다.
- 이해하기 쉽습니다.
- 목록이 이미 정렬되어 있거나 거의 정렬되어 있을 때 성능이 매우 뛰어납니다.
- 광범위한 메모리가 필요하지 않습니다.
- 이 알고리즘의 코드를 작성하는 것은 쉽습니다.
- 다른 정렬 알고리즘에 비해 공간 요구 사항이 최소화됩니다.
Bubble 정렬 단점
버블 정렬 알고리즘의 몇 가지 단점은 다음과 같습니다.
- 큰 목록을 정렬할 때는 성능이 좋지 않습니다. 시간과 자원이 너무 많이 소요됩니다.
- 주로 학술적인 목적으로 사용되며 실제 현장 적용에는 사용되지 않습니다.
- 목록을 정렬하는 데 필요한 단계 수는 n차입니다.2.
복잡성 분석 Bubble 정렬
복잡성에는 세 가지 유형이 있습니다.
1) 복잡성 정렬
정렬 복잡도는 리스트를 정렬하는 데 필요한 실행 시간과 공간의 양을 나타내는 데 사용됩니다. 버블 정렬은 리스트의 전체 요소 수(n)를 기준으로 (n-1)번의 반복을 통해 리스트를 정렬합니다.
2) 시간 복잡도
버블 정렬의 시간 복잡도는 O(n2).
시간 복잡도는 다음과 같이 분류될 수 있습니다.
- 최악의 경우 – 제공된 목록이 내림차순으로 표시됩니다. 알고리즘은 [Big-O] O(n)으로 표현되는 최대 실행 횟수를 수행합니다.2).
- 최고의 사례 – 이는 제공된 리스트가 이미 정렬되어 있을 때 발생합니다. 알고리즘은 [Big-Omega] Ω(n)으로 표현되는 최소 실행 횟수를 수행합니다.
- 평균 사례 – 이는 리스트가 무작위 순서로 정렬되어 있을 때 발생합니다. 평균 복잡도는 [Big-theta] ⊝(n)으로 표현됩니다.2).
3) 공간 복잡도
공간 복잡도는 리스트를 정렬하는 데 필요한 추가 공간의 양을 측정합니다. 버블 정렬은 스왑에 사용되는 시간 변수를 위해 단 하나의 추가 공간만 필요로 합니다.ping 값입니다. 따라서 공간 복잡도는 O(1)입니다.