데이터 구조에서의 B 트리: 검색, 삽입, 삭제
⚡ 스마트 요약
데이터 구조에서 B 트리는 디스크에서 빠른 검색, 삽입 및 삭제 작업을 위해 데이터를 정렬된 상태로 유지하는 자체 균형 트리입니다. 이 문서에서는 B 트리의 규칙, 역사, 검색, 삽입 및 삭제 알고리즘을 예제와 함께 설명합니다.

B 트리란 무엇입니까?
B 트리 B 트리는 특정 규칙 집합을 기반으로 데이터를 검색, 삽입 및 삭제하는 데 있어 더 빠르고 메모리 효율적인 자체 균형 데이터 구조입니다. 이를 위해 다음과 같은 규칙을 따라 B 트리를 생성합니다.
B-트리는 데이터 구조에서 특별한 종류의 트리입니다. 이 방법은 1972년 McCreight와 Bayer에 의해 처음 소개되었으며, 그들은 이를 높이 균형 m방향 탐색 트리(Height Balanced m-way Search Tree)라고 명명했습니다. B-트리는 데이터를 정렬된 상태로 유지하고 삽입, 검색, 삭제와 같은 다양한 연산을 더 빠른 시간 내에 수행할 수 있도록 도와줍니다.
B-트리에 대한 규칙
B-트리를 생성할 때 중요한 규칙은 다음과 같습니다.
- 모든 리프는 동일한 레벨에서 생성됩니다.
- B-트리는 차수(또는 "순서")의 개수로 결정되며, 이는 프로그래머와 같은 외부 주체가 지정합니다.
m앞으로. 의 가치m데이터가 주로 저장된 디스크의 블록 크기에 따라 달라집니다. - 노드의 왼쪽 하위 트리는 하위 트리의 오른쪽보다 작은 값을 갖습니다. 즉, 노드도 왼쪽에서 오른쪽으로 오름차순으로 정렬됩니다.
- 루트 노드와 그 자식 노드가 가질 수 있는 최대 키 개수는 다음 공식으로 계산됩니다.
m − 1. 예를 들면 :m = 4 max keys: 4 − 1 = 3

- 루트를 제외한 모든 노드는 최소한의 키를 포함해야 합니다.
[m/2] − 1. 예를 들면 :m = 4 min keys: 4/2 − 1 = 1
- 노드가 가질 수 있는 최대 자식 노드 수는 해당 차수와 같습니다.
m. - 노드가 가질 수 있는 최소 자식 수는 차수의 절반, 즉 m/2입니다(상한 값이 사용됨).
- 노드의 모든 키는 오름차순으로 정렬됩니다.
B-Tree를 사용하는 이유
B-Tree를 사용하는 이유는 다음과 같습니다.
- 디스크 읽기 횟수를 줄입니다.
- B-트리는 디스크 크기에 따라 크기(즉, 자식 노드 수)를 조정하도록 쉽게 최적화할 수 있습니다.
- 대용량 데이터를 처리하기 위해 특별히 고안된 기술입니다.
- 데이터베이스와 파일 시스템에 유용한 알고리즘입니다.
- 대용량 데이터를 읽고 쓸 때 선택하기에 좋은 옵션입니다.
B트리의 역사
- 데이터는 디스크에 블록 단위로 저장됩니다. 이렇게 저장된 데이터는 메인 메모리(또는 RAM)로 불러와질 때 데이터 구조라고 불립니다.
- 대용량 데이터의 경우, 디스크에서 하나의 레코드를 검색하려면 디스크 전체를 읽어야 합니다. 이는 디스크 접근 빈도와 데이터 크기가 높아져 시간과 메인 메모리 사용량을 증가시킵니다.
- 이를 극복하기 위해 레코드가 위치한 블록을 기반으로 레코드 참조를 저장하는 인덱스 테이블을 생성합니다.これにより 시간과 메모리 사용량이 크게 줄어듭니다.
- 방대한 데이터를 보유하고 있으므로 다단계 인덱스 테이블을 생성할 수 있습니다.
- 키에 대한 B 트리를 사용하여 다단계 인덱스를 설계할 수 있습니다.ping 데이터는 자체 균형 방식으로 정렬됩니다.
검색 Opera기
탐색 연산은 B 트리에서 가장 간단한 연산입니다. 다음 알고리즘이 적용됩니다.
- 검색할 키(값)를 "k"라고 하겠습니다.
- 루트부터 검색을 시작하여 재귀적으로 아래로 탐색합니다.
- k가 루트 값보다 작으면 왼쪽 서브트리를 검색하고, k가 루트 값보다 크면 오른쪽 서브트리를 검색합니다.
- 노드에 k가 발견되면 간단히 노드를 반환합니다.
- k가 노드에서 발견되지 않으면 더 큰 키를 가진 하위 항목으로 이동합니다.
- k가 트리에서 발견되지 않으면 NULL을 반환합니다.
끼워 넣다 Opera기
B 트리는 자체 균형 트리이므로 임의의 노드에 키를 강제로 삽입할 수 없습니다. 다음 알고리즘이 적용됩니다.
- 검색 작업을 실행하여 적절한 삽입 위치를 찾으세요.
- 적절한 위치에 새 키를 삽입합니다. 단, 노드에 이미 최대 키 수가 있는 경우 다음을 수행하세요.
- 노드는 새로 삽입된 키와 함께 중간 요소에서 분할됩니다.
- 중간 요소는 다른 두 하위 노드의 상위 요소가 됩니다.
- 노드는 키를 오름차순으로 다시 정렬해야 합니다.
💡 팁: 다음은 지원 삽입 알고리즘에 대한 설명 중 "노드가 가득 찼으므로 분할된 후 새 값이 삽입됩니다."라는 부분은 맞습니다. 키가 먼저 삽입되고, 최대 키 개수를 초과하는 경우에만 노드가 분할됩니다.

위의 예에서:
- 노드에서 해당 위치에 있는 키를 검색합니다.
- 대상 노드에 키를 삽입하고 규칙을 확인합니다.
- 삽입 후 노드에 최소 키 개수(1개) 이상이 있는지 확인하세요. 이 경우, 그렇습니다. 다음 규칙을 확인하세요.
- 삽입 후 해당 노드의 키 개수가 최대 개수인 3개를 초과하는지 확인해 보세요. 이 경우 초과하지 않습니다. 따라서 B 트리는 어떤 규칙도 위반하지 않았으며, 삽입이 완료되었습니다.

위의 예에서:
- 해당 노드가 최대 키 개수에 도달했습니다.
- 노드가 분할되고, 가운데 키가 나머지 두 노드의 루트 노드가 됩니다.
- 키의 개수가 짝수인 경우, 왼쪽 편향 또는 오른쪽 편향에 따라 가운데 노드가 선택됩니다.

위의 예에서:
- 해당 노드는 최대 키 개수보다 적은 키를 가지고 있습니다.
- 1이 3 옆에 삽입되었지만, 오름차순 정렬 규칙이 위반되었습니다.
- 이 문제를 해결하기 위해 키를 정렬합니다.
마찬가지로 13과 2는 노드에 대한 "최대 키 수 미만" 규칙을 충족하므로 노드에 쉽게 삽입할 수 있습니다.

위의 예에서:
- 노드에는 최대 키와 동일한 키가 있습니다.
- 키가 대상 노드에 삽입되었지만 최대 키 개수 제한 규칙을 위반했습니다.
- 대상 노드가 분할되고 왼쪽 바이어스에 의한 가운데 키가 이제 새 하위 노드의 상위가 됩니다.
- 새 노드는 오름차순으로 정렬됩니다.
마찬가지로 위의 규칙과 사례를 바탕으로 나머지 값도 B Tree에 쉽게 삽입할 수 있습니다.

. Opera기
삭제 작업에는 삽입 및 검색 작업보다 더 많은 규칙이 적용됩니다. 다음 알고리즘이 적용됩니다.
- 검색 작업을 실행하고 노드에서 대상 키를 찾습니다.
- 다음 섹션에서 설명하는 바와 같이 대상 키의 위치에 따라 세 가지 조건이 적용됩니다.
대상 키가 리프 노드에 있는 경우
- Target 리프 노드에 최소 키 개수보다 많은 키가 있습니다. 이를 삭제해도 B 트리의 속성은 위반되지 않습니다.
- Target 리프 노드에 있으며 최소 키 노드를 가지고 있습니다. 이를 삭제하면 B 트리의 속성을 위반하게 됩니다.
- 대상 노드는 바로 왼쪽 노드 또는 바로 오른쪽 노드(형제 노드)로부터 키를 빌릴 수 있습니다.
- 동생이 말하겠지 예 키 개수가 최소 개수보다 많으면 안 됩니다.
- 키는 부모 노드에서 빌려오고, 최댓값은 부모 노드로 전송되며, 부모 노드의 최댓값은 대상 노드로 전송되고, 대상 값은 제거됩니다.
- Target 리프 노드에 있지만 형제 노드 중 키 개수가 최소값보다 큰 노드가 없는 경우, 해당 키를 검색하고 형제 노드 및 부모 노드 중 최소값과 병합합니다. 그러면 총 키 개수가 최소값보다 많아지고 대상 키는 부모 노드 중 최소값으로 대체됩니다.
대상 키가 내부 노드에 있는 경우
- 순서상 선행 항목을 선택하거나 순서상 후행 항목을 선택하십시오.
- 상위 항목이 순서대로 정렬된 경우, 해당 항목의 왼쪽 하위 트리에서 가장 큰 키가 선택됩니다.
- 순서가 일치하는 후속 노드의 경우, 오른쪽 서브트리에서 최소 키가 선택됩니다.
- 대상 키의 순차적 선행 키에 최소 키 개수보다 많은 키가 있는 경우에만 대상 키를 순차적 선행 키 중 최대 키로 대체할 수 있습니다.
- 대상 키의 순차적 선행 키에 최소 키 개수보다 많은 키가 없는 경우, 순차적 후행 키의 최소 키를 찾습니다.
- 대상 키의 순서대로 선행 키와 후속 키가 모두 최소 키보다 작은 경우 선행 키와 후속 키를 병합합니다.
대상 키가 루트 노드에 있는 경우
- 중위 순회 선행자 서브트리의 최댓값 요소로 대체하십시오.
- 삭제 후 대상 노드에 최소 키 개수보다 적은 키가 남아 있는 경우, 대상 노드는 형제 노드의 부모를 통해 형제 노드로부터 최대값을 빌려옵니다.
- 대상 노드는 부모 노드의 최댓값을 가지지만, 형제 노드 중 최댓값을 가진 노드들도 함께 고려합니다.
이제 예를 들어 삭제 작업을 알아보겠습니다.

위 그림은 B-트리에서 삭제 연산의 다양한 경우를 보여줍니다. 이 B-트리는 5차 트리로, 어떤 노드든 자식 노드를 최소 3개, 최대 5개까지 가질 수 있습니다. 또한, 어떤 노드든 키(key)를 최소 2개, 최대 4개까지 가질 수 있습니다.

위의 예에서:
- 대상 노드는 삭제할 대상 키를 가지고 있습니다.
- 대상 노드에 최소 키 개수보다 많은 키가 있습니다.
- 키를 삭제하기만 하면 됩니다.

위의 예에서:
- 대상 노드는 최소 키 개수와 동일한 키를 가지고 있으므로, 조건을 위반하게 되어 직접 삭제할 수 없습니다.
다음 다이어그램은 이 키를 삭제하는 방법을 설명합니다.

- 대상 노드는 바로 위 형제 노드, 즉 이 경우 순회상 선행 노드(왼쪽 형제 노드)로부터 키를 빌립니다. 왜냐하면 대상 노드에는 순회상 후행 노드(오른쪽 형제 노드)가 없기 때문입니다.
- 순서대로 정렬된 선행 노드의 최댓값이 부모 노드로 전달되고, 부모 노드는 최댓값을 대상 노드로 전달합니다(아래 그림 참조).
다음 예제는 값이 필요한 키를 순서대로 나열된 후속 키에서 삭제하는 방법을 보여줍니다.

- 대상 노드는 바로 위 형제 노드, 즉 이 경우 순차적 선행 노드(왼쪽 형제 노드)가 최소 키와 동일한 키를 가지고 있으므로 순차적 후속 노드(오른쪽 형제 노드)로부터 키를 빌립니다.
- 순서대로 계승되는 노드의 최소값은 상위 노드로 전달되고, 상위 노드는 최대값을 대상 노드로 전달합니다.
아래 예시에서 대상 노드는 대상 노드에 키를 제공할 수 있는 형제 노드가 없습니다. 따라서 병합이 필요합니다. 이러한 키를 삭제하는 절차는 다음을 참조하십시오.
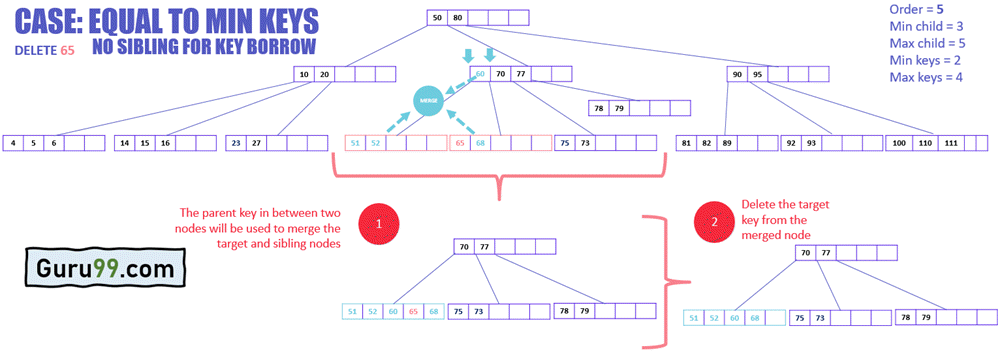
- 대상 노드를 부모 키와 함께 바로 아래 형제 노드들과 병합합니다.
- 부모 노드에서 병합될 두 노드 사이에 있는 키가 선택됩니다.
- 병합된 노드에서 대상 키를 삭제합니다.
. Operation 의사 Code
private int removeBiggestElement() { if (root has no child) remove and return the last element else { answer = subset[childCount-1].removeBiggestElement() if (subset[childCount-1].dataCount < MINIMUM) fixShort (childCount-1) return answer } }
출력: B-Tree에서 가장 큰 요소가 삭제됩니다.