XPath の Selenium: チュートリアル

XPathとは何ですか Selenium?
XPath の Selenium ページの HTML 構造内のナビゲーションに使用される XML パスです。 これは、XML パス表現を使用して Web ページ上の要素を検索するための構文または言語です。 XPath は HTML ドキュメントと XML ドキュメントの両方に使用でき、HTML DOM 構造を使用して Web ページ上の要素の場所を検索できます。
In Selenium 自動化では、ID、クラス、名前などの一般的なロケータで要素が見つからない場合、Web ページ上の要素を見つけるために XPath が使用されます。
このチュートリアルでは、更新や操作によって属性が動的に変化する複雑な要素や動的な要素を見つけるための Xpath とさまざまな XPath 式について学習します。
XPath 構文
XPath には、Web ページにある要素のパスが含まれます。 XPath を作成するための標準の XPath 構文は次のとおりです。
Xpath=//tagname[@attribute='value']
Selenium における XPath の基本形式を、以下にスクリーンショットとともに説明します。
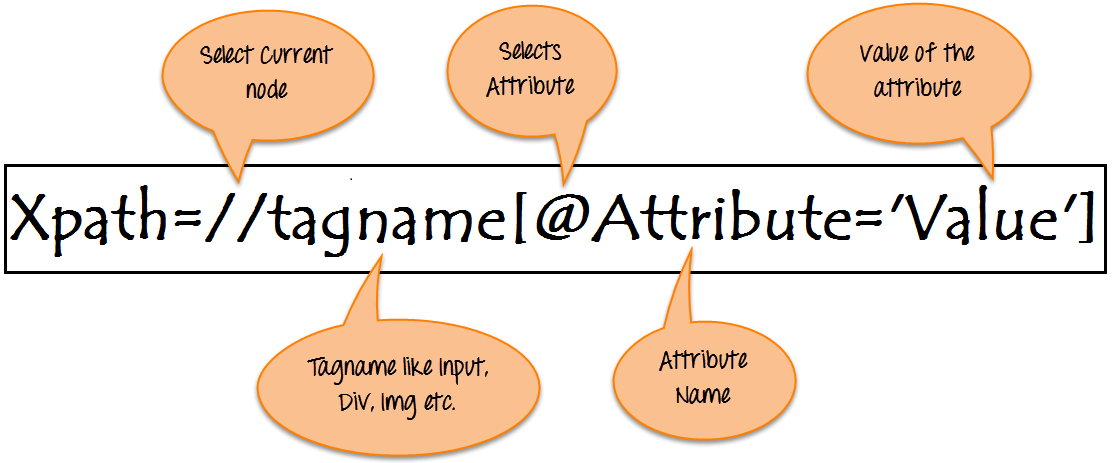
- //: 現在のノードを選択します。
- タグ名: 特定のノードのタグ名。
- @: 属性を選択します。
- 属性: ノードの属性名。
- 値: 属性の値。
Web ページ上の要素を正確に見つけるために、さまざまなタイプのロケーターがあります。
| XPath ロケーター | Web ページ上のさまざまな要素を見つける |
|---|---|
| ID | 要素のIDで要素を検索するには |
| クラス名 | 要素のクラス名で要素を検索するには |
| 名前 | 要素の名前で要素を検索するには |
| リンクテキスト | リンクのテキストで要素を検索するには |
| XPath | 動的要素を検索し、Web ページのさまざまな要素間を移動するために必要な XPath |
| CSSパス | CSS パスでは、名前、クラス、ID のない要素も検索されます。 |
Xパスの種類
XPath には次の XNUMX 種類があります。
1) 絶対 XPath
2) 相対 XPath
絶対 XPath
これは要素を見つける直接的な方法ですが、絶対 XPath の欠点は、要素のパスに変更が加えられた場合に XPath が失敗することです。
XPath の主な特徴は、単一のスラッシュ (/) で始まることです。これは、ルート ノードから要素を選択できることを意味します。
以下は、以下の画面に表示される要素の絶対 Xpath 式の例です。
注: 次のXPath演習をこの上で練習することができます https://demo.guru99.com/test/selenium-xpath.html
詳しくはこちら こちら ビデオにアクセスできない場合
絶対 XPath:
/html/body/div[2]/div[1]/div/h4[1]/b/html[1]/body[1]/div[2]/div[1]/div[1]/h4[1]/b[1]

相対Xpath
相対Xpath HTML DOM 構造の途中から始まります。二重スラッシュ (//) で始まります。Web ページ上の任意の場所にある要素を検索できるため、長い xpath を記述する必要がなく、HTML DOM 構造の途中から開始できます。相対 Xpath はルート要素からの完全なパスではないため、常に優先されます。
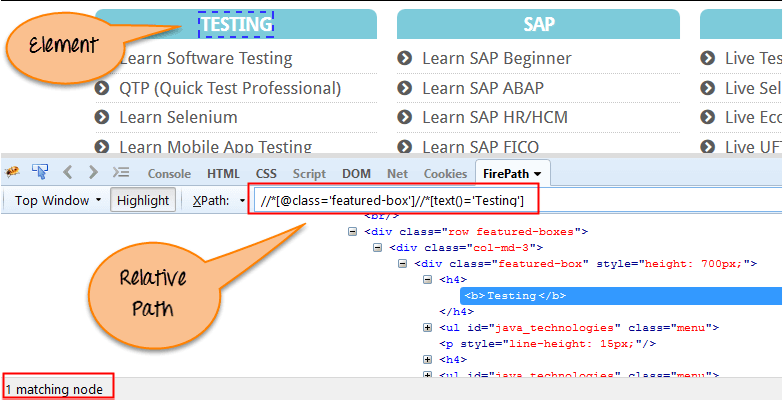
以下は、以下の画面に示されている同じ要素の相対 XPath 式の例です。 これは、XPath による要素の検索に使用される一般的な形式です。
詳しくはこちら こちら ビデオにアクセスできない場合
Relative XPath: //div[@class='featured-box cloumnsize1']//h4[1]//b[1]
XPath 軸とは何ですか?
XPath軸は、現在のコンテキストノードからXML文書内の異なるノードを検索します。XPath軸は、ID、クラス名、名前などを持たない通常のXPathメソッドでは見つけられない動的な要素を見つけるために使用されるメソッドです。XPathは Selenium Contains、AND、Absolute XPath、Relative XPath などのさまざまな属性と条件に基づいて動的な要素を識別および特定するいくつかの方法が含まれています。
軸メソッドは、リフレッシュやその他の操作で動的に変化する要素を見つけるために使用されます。 Selenium ウェブドライバー 子、親、祖先、兄弟、先行者、自分自身など。
動的 XPath を書き込む方法 Selenium webdriver
1) 基本的な XPath
XPath 式は、次のような属性に基づいてノードまたはノードのリストを選択します。 ID、名前、クラス名以下に示すように、XML ドキュメントから、などを取得します。
Xpath=//input[@name='uid']
ページにアクセスするためのリンクはこちらです https://demo.guru99.com/test/selenium-xpath.html

さらに基本的な xpath 式をいくつか示します。
Xpath=//input[@type='text'] Xpath=//label[@id='message23'] Xpath=//input[@value='RESET'] Xpath=//*[@class='barone'] Xpath=//a[@href='https://demo.guru99.com/'] Xpath=//img[@src='//guru99.com/images/home/java.png']
2) を含む()
Contains() は XPath 式で使用されるメソッドです。 これは、ログイン情報など、属性の値が動的に変更される場合に使用されます。
以下の XPath の例に示すように、contain 機能には部分的なテキストを含む要素を検索する機能があります。
この例では、属性の部分的なテキスト値のみを使用して要素を識別しようとしました。 以下の XPath 式では、部分値「sub」が送信ボタンの代わりに使用されています。 要素が正常に検出されたことがわかります。
「Type」の完全な値は「submit」ですが、部分的な値「sub」のみを使用しています。
Xpath=//*[contains(@type,'sub')]
「name」の完全な値は「btnLogin」ですが、部分的な値「btn」のみが使用されています。
Xpath=//*[contains(@name,'btn')]
上記の式では、以下のスクリーンショットに示すように、「name」を属性として、「btn」を部分値として取得しています。 これにより、「name」属性が「btn」で始まる 2 つの要素 (LOGIN および RESET) が検索されます。

同様に、以下の式では、「id」を属性として、「message」を部分値として取得しています。 これにより、「id」属性が「message」で始まるため、2 つの要素 (「User-ID は空白であってはなりません」と「Password は空白であってはなりません」) が見つかります。
Xpath=//*[contains(@id,'message')]

以下の式では、以下のスクリーンショットに示すように、リンクの「テキスト」を属性として、「here」を部分値として取得しています。 これにより、「ここ」というテキストが表示されるため、リンク (「ここ」) が検索されます。
Xpath=//*[contains(text(),'here')]
Xpath=//*[contains(@href,'guru99.com')]

3) OR と AND の使用
OR 式では、1 番目の条件または 2 番目の条件が真であるかどうかの XNUMX つの条件が使用されます。 いずれかの条件が true である場合、または両方の条件が true である場合にも適用されます。 要素を見つけるには、いずれかの条件が true でなければならないことを意味します。
以下の XPath 式では、単一または両方の条件が true である要素を識別します。
Xpath=//*[@type='submit' or @name='btnReset']
両方の要素を、属性 'type' を持つ「LOGIN」要素と、属性 'name' を持つ「RESET」要素として強調表示します。

AND 式では XNUMX つの条件が使用され、要素を検索するには両方の条件が true である必要があります。 いずれかの条件が false の場合、要素の検索は失敗します。
Xpath=//input[@type='submit' and @name='btnLogin']
以下の式では、属性「type」と「name」の両方を持つ「LOGIN」要素を強調表示しています。

4) Xpath で始まる
XPath は () で始まります は、Web ページの更新時や、その他の動的操作によって属性値が変更される Web 要素を見つけるために使用される関数です。この方法では、属性の開始テキストを照合して、属性値が動的に変化する要素を見つけます。属性値が静的 (変化しない) な要素を見つけることもできます。
例 -: 特定の要素の ID が次のように動的に変更されるとします。
ID=”メッセージ12”
ID=”メッセージ345”
ID=”メッセージ8769”
など。ただし、最初のテキストは同じです。 この場合、Start-with 式を使用します。
以下の式には、「message」で始まる ID を持つ要素が XNUMX つあります (つまり、「ユーザー ID は空白であってはなりません」と「パスワードは空白であってはなりません」)。 以下の例では、XPath は「ID」が「message」で始まる要素を検索します。
Xpath=//label[starts-with(@id,'message')]

5) XPath Text() 関数
その XPath text() 関数 は、Web 要素のテキストに基づいて要素を検索するために使用される、Selenium WebDriver の組み込み関数です。正確なテキスト要素を見つけるのに役立ち、テキスト ノードのセット内で要素を検索します。検索する要素は文字列形式である必要があります。
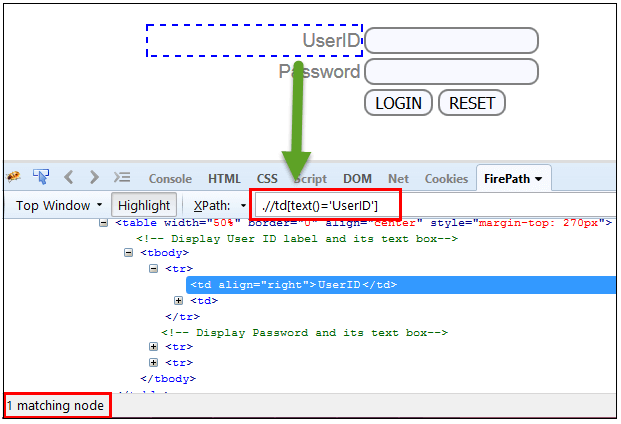
この式では、text 関数を使用して、以下に示すようにテキストが完全に一致する要素を見つけます。 この例では、「UserID」というテキストを持つ要素が見つかります。
Xpath=//td[text()='UserID']
XPath 軸メソッド
これらの XPath 軸メソッドは、複雑な要素や動的な要素を見つけるために使用されます。以下では、これらのメソッドのいくつかについて説明します。
これらの XPath 軸メソッドを説明するために、 Guru99銀行のデモサイト。
1) フォロー
下の画面に示すように、現在のノード( )[UserID入力ボックスが現在のノードです]のドキュメント内のすべての要素を選択します。
Xpath=//*[@type='text']//following::input

「次の」軸を使用して一致する 3 つの「入力」ノードがあります - パスワード、ログイン、リセット ボタン。特定の要素に焦点を当てたい場合は、以下の XPath メソッドを使用できます。
Xpath=//*[@type='text']//following::input[1]
[1]、[2]…………などと入力することで、要件に応じて XPath を変更できます。
入力が「1」の場合、下のスクリーンショットは「パスワード」入力ボックス要素である特定のノードを見つけます。

2) 先祖
以下の画面に示すように、祖先軸は現在のノードのすべての祖先要素 (祖父母、親など) を選択します。
以下の式では、現在のノード(「ENTERPRISE TESTING」ノード)の祖先要素を検索しています。
Xpath=//*[text()='Enterprise Testing']//ancestor::div

「ancestor」軸を使用して一致する「div」ノードが 13 個あります。 特定の要素に焦点を当てたい場合は、以下の XPath を使用できます。要件に応じて数値 1、2 を変更します。
Xpath=//*[text()='Enterprise Testing']//ancestor::div[1]
[1]、[2]…………などと入力することで、必要に応じてXPathを変更できます。
3) 子供
現在のノードのすべての子要素を選択します(Java)をクリックします。
Xpath=//*[@id='java_technologies']//child::li

「子」軸を使用して一致する「li」ノードは 71 個あります。 特定の要素に注目したい場合は、以下の xpath を使用できます。
Xpath=//*[@id='java_technologies']//child::li[1]
[1]、[2]…………などと入力することで、要件に応じて xpath を変更できます。
4) 先行
以下の画面に示すように、現在のノードの前にあるすべてのノードを選択します。
以下の式では、「LOGIN」ボタンの前にあるすべての入力要素を識別します。 ユーザーID (NAIST) と password 入力要素。
Xpath=//*[@type='submit']//preceding::input
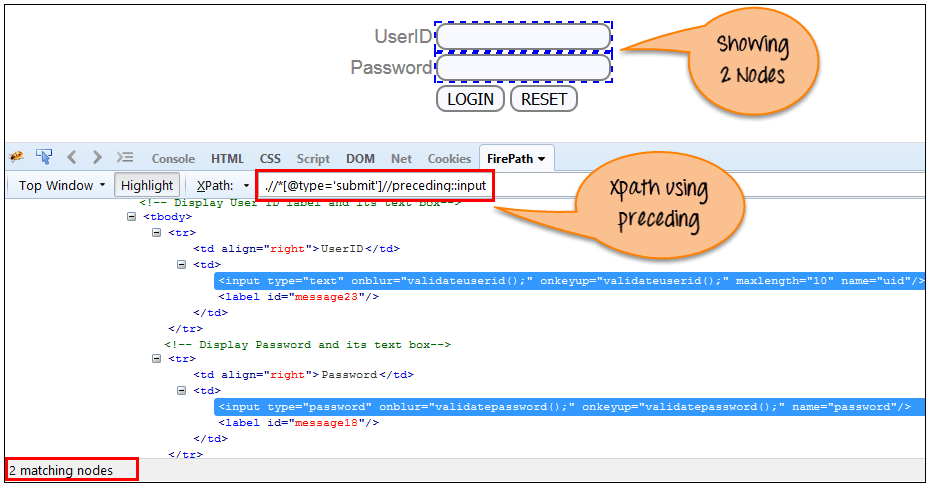
「前の」軸を使用して一致する「入力」ノードが 2 つあります。 特定の要素に注目したい場合は、以下の XPath を使用できます。
Xpath=//*[@type='submit']//preceding::input[1]
[1]、[2]…………などと入力することで、要件に応じて xpath を変更できます。
5) 兄弟姉妹
コンテキスト ノードの次の兄弟を選択します。兄弟は、下の画面に示すように、現在のノードと同じレベルにあります。現在のノードの後の要素が検索されます。
xpath=//*[@type='submit']//following-sibling::input

「following-sibling」軸を使用して一致する 1 つの入力ノード。
6) 親
以下の画面に示すように、現在のノードの親を選択します。
Xpath=//*[@id='rt-feature']//parent::div

「親」軸を使用して一致する「div」ノードが 65 個あります。 特定の要素に注目したい場合は、以下の XPath を使用できます。
Xpath=//*[@id='rt-feature']//parent::div[1]
[1]、[2]…………などと入力することで、要件に応じて XPath を変更できます。
7) 自分自身
現在のノードまたは「self」を選択すると、以下の画面に示すようにノード自体を示します。

「self」軸を使用して一致する XNUMX つのノード。 自己要素を表すため、常に XNUMX つのノードのみが見つかります。
Xpath =//*[@type='password']//self::input
8) 子孫
以下の画面に示すように、現在のノードの子孫を選択します。
以下の式では、現在の要素 (「本体周囲」フレーム要素) のすべての子孫、つまりノード (子ノード、孫ノードなど) の下にある要素を識別します。
Xpath=//*[@id='rt-feature']//descendant::a
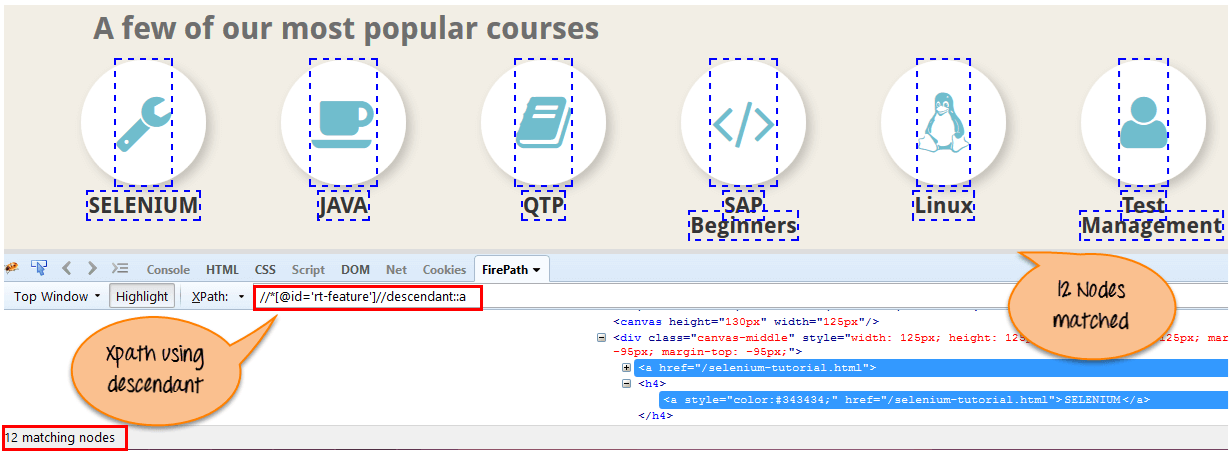
「子孫」軸を使用して一致する「リンク」ノードは 12 個あります。 特定の要素に注目したい場合は、以下の XPath を使用できます。
Xpath=//*[@id='rt-feature']//descendant::a[1]
[1]、[2]…………などと入力することで、要件に応じて XPath を変更できます。
よくあるご質問
製品概要
特定の要素に対して操作を実行するには、Web ページ上の要素を見つけるために XPath が必要です。
- Selenium XPath には 2 つの種類があります。
- 絶対 XPath
- 相対XPath
- XPath軸は、通常のXPathメソッドでは見つけられない動的要素を見つけるために使用されるメソッドです。
- XPath 式は、XML ドキュメントの ID、名前、クラス名などの属性に基づいてノードまたはノードのリストを選択します。
また、チェックしてください:- Selenium 初心者向けチュートリアル: 7 日間で WebDriver を学ぶ