Scikit-Learn チュートリアル: インストール方法と Scikit-Learn の例
⚡ スマートサマリー
Scikit-learnはオープンソースです Python 前処理、分類、回帰、クラスタリング、モデル選択を単一の一貫した推定器インターフェースで網羅するライブラリであり、生データからスコア付き予測まで、機械学習ワークフロー全体を短く、読みやすく、再現可能なものにします。

Scikit-learnとは何ですか?
シキット学習 オープンソースです Python ライブラリ 機械学習KNN、勾配ブースティング、ランダムフォレスト、SVMなどの確立されたアルゴリズムをサポートしており、 NumPy SciPyもその一つです。Scikit-learnは、Kaggleのコンペティションや著名なテクノロジー企業で広く利用されています。前処理、次元削減、分類、回帰、クラスタリング、モデル選択といった機能を網羅しています。
Scikit-learnは、オープンソースライブラリの中でも最高レベルのドキュメントを備えています。インタラクティブな推定チャートも提供しています。 適切な見積りツールの選択これは、データセットのサイズから、試してみる価値のあるアルゴリズムの候補リストを作成するまでの手順を案内します。
下の図は、Scikit-learnの仕組みを示しています。
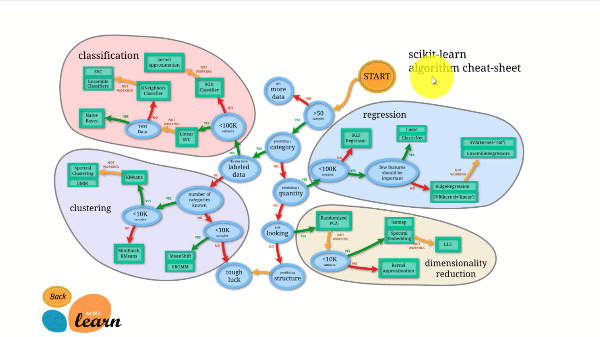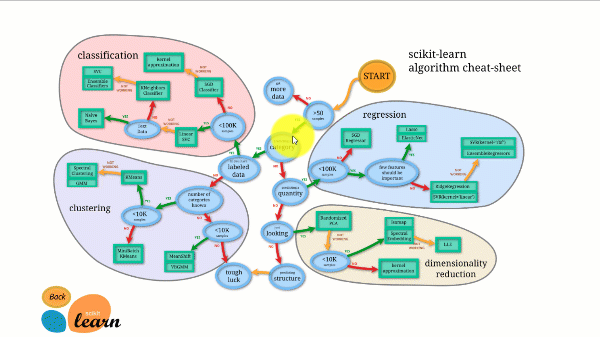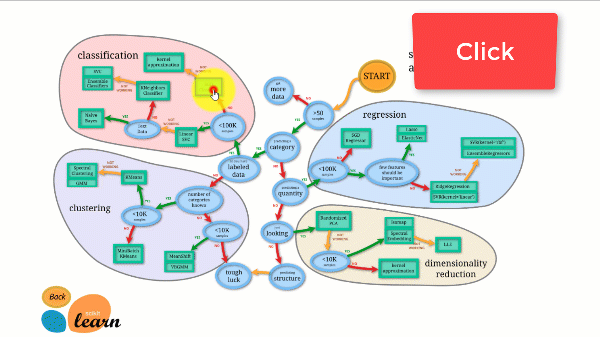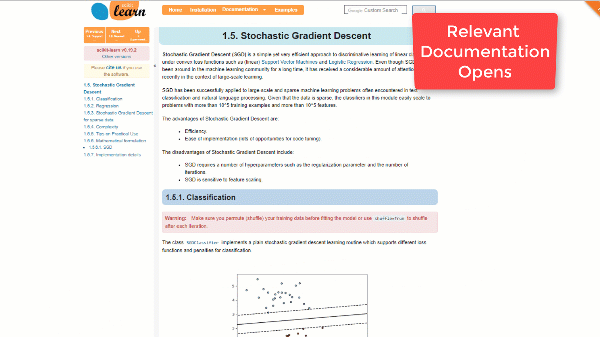
Scikit-learnは使い方が難しくなく、優れた結果が得られます。ただし、GPUではなくCPU上で学習します。n_jobs引数で並列処理をコア間で実行します。ディープラーニングアルゴリズムを実行することは可能ですが、特に既に別の方法を知っている場合は、最適とは言えません。 TensorFlow.
Scikit-learn をダウンロードしてインストールする方法
今これで Python Scikit-learnチュートリアルでは、Scikit-learnのダウンロードとインストール方法を学びます。
オプション1:AWS
Scikit-learnはAWS上で使用できます。Scikit-learnがプリインストールされたDockerイメージを使用すれば、セットアップ作業を完全に省略できます。
開発者バージョンをインストールするには、以下のコマンドを Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
オプション2:Macまたは Windows アナコンダを使用する
Anacondaのインストール方法については、以下を参照してください。 TensorFlowのダウンロードとインストール方法.
このチュートリアルが書かれた時点では、scikitの開発者は当時のリリースに存在する問題を修正した開発版をリリースしていたため、以下の手順ではその開発者ビルドを使用します。今日の新しいマシンでは、現在の安定版リリースにはここで使用されているすべてのトランスフォーマーが既に含まれており、 pip install -U scikit-learn 十分です
Conda 環境で scikit-learn をインストールする方法
conda環境でscikit-learnをインストールした場合は、以下の手順に従ってバージョン0.20にアップデートしてください。
ステップ1)TensorFlow環境をアクティブ化する
source activate hello-tf
ステップ2)condaコマンドを使用してscikit-learnを削除します
conda remove scikit-learn
ステップ3)開発者版をインストールする
scikit-learnの開発者版と必要なライブラリをインストールしてください。
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
注: Windows ユーザーが必要 Microsoft ビジュアル C++ 14. 入手できます こちら.
機械学習を使用した Scikit-Learn の例
この Scikit チュートリアルは XNUMX つの部分に分かれています。
- scikit-learn による機械学習
- LIME でモデルを信頼する方法
第1部では、パイプラインの構築方法、モデルの作成方法、ハイパーパラメータの調整方法について詳しく説明し、第2部ではモデルの解釈について解説します。
ステップ 1) データをインポートする
このScikit-learnチュートリアルでは、成人国勢調査データセットを使用します。
以下のコードでは、ファイルはUCI機械学習リポジトリから直接読み込まれるため、手動でダウンロードする必要はありません。記述統計に興味がある場合は、DiveツールとOverviewツールをご覧ください。 このチュートリアル ダイビングと概要についてさらに詳しく知りたい場合は、こちらをご覧ください。
pandasを使ってデータセットをインポートします。連続変数は浮動小数点形式に変換する必要があることに注意してください。
このデータセットには、CATE_FEATURESに記載されている8つのカテゴリ変数が含まれています。
- ワーククラス
- 教育
- 夫婦の
- 職業
- 関係
- レース
- セックス
- 母国
また、CONTI_FEATURESに記載されている6つの連続変数も含まれています。
- 年齢
- fnlwgt
- 教育番号
- 資本利得
- 資本損失
- 時間_週
ここでは、どの列が関係しているかをより明確に把握できるように、リストを手動で入力しています。カテゴリ列または連続列のリストをより迅速に作成する方法は次のとおりです。
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
データをインポートするコードは次のとおりです。
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
フレームに対して describe() を呼び出すと、6 つの連続列の要約統計情報が返されます。
| 年齢 | fnlwgt | 教育番号 | 資本利得 | 資本損失 | 時間_週 | |
|---|---|---|---|---|---|---|
| カウント | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| 意味する | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| STD | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| 分 | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| マックス | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
native_country 特徴量の一意の値の数を確認できます。オランダ出身の世帯は 1 つだけです。この世帯は情報を提供しないため、トレーニング中にエラーが発生します。
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
この情報量の少ない行をデータセットから除外できます。
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
次に、連続フィーチャの位置をリストに保存します。 これは、パイプラインを構築する次のステップで必要になります。
以下のコードは、CONTI_FEATURES 内のすべての列名をループ処理し、各位置 (つまり、その列番号) を読み取り、conti_features というリストに追加します。
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
次のブロックは、カテゴリ変数に対しても同様の処理を行います。
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
次に、データセット自体を見てみましょう。各カテゴリカル特徴量は文字列ですが、モデルに文字列値を入力することはできません。そのため、データセットをダミー変数で変換する必要があります。
df_train.head(5)
実際には、各フィーチャー内の各グループごとに1つの列が必要です。まず、以下のコードを実行して、必要な列の総数を計算してください。
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
データセット全体は、上記のように101のグループで構成されています。workclassフィーチャだけでも9つのグループがあります。以下のコードでグループ名を一覧表示できます。unique()関数は、各カテゴリカルフィーチャの重複しない値を返します。
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
したがって、トレーニングデータセットには、ワンホットグループと6つの連続特徴量を含む101+6列が含まれます。
Scikit-learnは、以下の2つのステップで変換処理を行うことができます。
- 文字列をIDに変換します。State-govはID 1、Self-emp-not-incはID 2、といった具合です。LabelEncoderはこの処理を自動的に行ってくれます。
- 各IDを新しい列に転置します。データセットには101個のグループIDがあるため、カテゴリカル特徴グループごとに101個の列が作成されます。Scikit-learnはこの操作にOneHotEncoderを提供しています。
ステップ 2) トレーニング/テスト セットを作成する
データセットの準備ができたので、それを80対20の割合で分割します。つまり、80%をトレーニングセットに、20%をテストセットに割り当てます。
train_test_split関数を使用できます。最初の引数は特徴量のデータフレーム、2番目の引数はラベルです。test_size関数でテストセットのサイズを設定します。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
ステップ 3) パイプラインを構築する
このパイプラインを使うことで、モデルに一貫性のあるデータを簡単に供給できるようになります。基本的な考え方は、生データを1つのオブジェクトに通し、そのオブジェクトがすべての操作を順番に実行することです。
このデータセットでは、連続変数を標準化し、カテゴリ変数を変換する必要があります。あらゆる操作をパイプライン内で実行できます。欠損値は平均値または中央値で置き換えたり、新しい変数を作成したりできます。
選択肢は2つあります。2つのプロセスをハードコーディングするか、パイプラインを構築するかです。ハードコーディングすると、テストデータが適合統計に漏れ込み、時間の経過とともに矛盾が生じる可能性があるため、パイプラインの方がより良い選択肢です。
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
このパイプラインは、ロジスティック分類器にデータを入力する前に、2つの操作を実行します。
- 変数を標準化する: StandardScaler()
- カテゴリ特徴量を変換します: OneHotEncoder(sparse=False)
どちらのステップもmake_column_transformer関数で実行します。このチュートリアルを作成した時点では、この関数はscikit-learnのリリース版(0.19)には含まれていなかったため、開発者向けビルドを使用しました。0.20以降の安定版リリースには必ず含まれています。
make_column_transformer は簡単です。変換する列と適用する変換を宣言するだけです。連続フィーチャを標準化するには、次の値を渡します。
- conti_features、make_column_transformer内のStandardScaler()
- conti_features: 連続列のリスト
- StandardScaler: これらの列を標準化します
make_column_transformer 内の OneHotEncoder オブジェクトは、ラベルを自動的にエンコードします。
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
バージョンノート: 上記のブロック内の 2 つの引数が移動しました。現在のリリースでは、トランスフォーマーが最初に、列が次に実行されることが想定されています。 まばらな 名前が変更されました 疎な出力 scikit-learn 1.2 で導入され、1.4 で削除されたため、新しいコードでは次のようになります。 OneHotEncoder(sparse_output=False).
fit_transform を使用してパイプラインが正しく動作するかどうかをテストできます。出力は 26048、107 の形状になるはずです。
preprocess.fit_transform(X_train).shape
(26048, 107)
データ変換ツールが準備できました。make_pipelineコマンドでパイプラインを作成し、データ変換が完了したら、ロジスティック回帰にデータを入力します。
model = make_pipeline(
preprocess,
LogisticRegression())
scikit-learn を使ってモデルをトレーニングするのは簡単です。パイプラインで fit メソッドを呼び出すだけです。精度は score メソッドで表示できます。
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
最後に、predict_proba関数を使ってクラスを予測できます。この関数は各クラスの確率を返します。なお、2つの確率の合計は1になります。
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
ステップ 4) グリッド検索でパイプラインを使用する
モデルの構造を決定づけるハイパーパラメータの値を調整する作業は、面倒で骨の折れる作業になりかねない。
モデルを評価する一つの方法は、トレーニングセットのサイズを変更してパフォーマンスを測定し、それを10回繰り返してスコアのばらつきを確認することです。しかし、これはかなりの手作業になります。
その代わりに、scikit-learnはパラメータ調整や交差検証を自動的に実行してくれる関数を提供しています。
交差検証
交差検証とは、トレーニング中にトレーニングセットをn回に分割し、モデルをn回評価することを意味します。cvを10に設定すると、モデルは10回トレーニングおよび評価されます。各ラウンドでは、分類器はランダムに選択された9つのフォールドでトレーニングを行い、10番目のフォールドは評価用に保持されます。
グリッド検索
どの分類器にも調整すべきハイパーパラメータがあります。値を一つずつ試すことも、パラメータグリッドを設定することもできます。scikit-learnのドキュメントには、ロジスティック分類器が受け入れるすべてのパラメータが記載されています。トレーニングを高速化するために、この例では正則化を制御するCパラメータのみを調整します。Cは正の値でなければならず、値が小さいほど正則化項の重みが大きくなります。
GridSearchCVオブジェクトを使用します。このオブジェクトは、調整するハイパーパラメータの辞書を受け取ります。各ハイパーパラメータとその後に試したい値を列挙します。Cを調整するには、次のように記述します。
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — パラメータ名の前には、小文字の分類器名と2つのアンダースコアが付きます。
このモデルは、0.001、0.01、0.1、1 の 4 つの異なる値を試行します。10 分割交差検証 (cv=10) で学習を行います。
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
これで、GridSearchCV を grid と cv のパラメータで使用してモデルをトレーニングできます。
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
出力:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
バージョンノート: iid この出力に表示されている引数は、scikit-learn 0.22 で非推奨となり、0.24 で削除されたため、現在のリリースでは GridSearchCV 呼び出しから単純に削除する必要があります。
最適なパラメータにアクセスするには、best_params_ を使用します。
grid_clf.best_params_
出力:
{'logisticregression__C': 1.0}
4つの異なる正則化値でモデルを学習させた結果、最適なパラメータは次のようになりました。
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
グリッド検索からの最良のロジスティック回帰: 0.850891
予測確率にアクセスするには:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
scikit-learn を使用した XGBoost モデル
それでは、市場で最も強力な分類器の1つを試してみましょう。XGBoostは、ランダムフォレストを勾配ブースティングで改良したものです。その理論的背景は、この範囲外です。 Python Scikit-learnのチュートリアルを参照してください。ただし、XGBoostはKaggleのコンペティションで数多くの優勝を飾っていることを覚えておいてください。平均的なサイズのデータセットであれば、ディープラーニングアルゴリズムと同等、あるいはそれ以上の性能を発揮できます。
分類器は多数のパラメータを持つため、学習が難しい。もちろん、GridSearchCVを使ってパラメータを選択することもできる。
より良い選択肢は RandomizedSearchCV です。GridSearchCV は、グリッドが大きくなると、パラメータを追加するたびに探索空間が拡大するため、処理速度が低下します。一方、RandomizedSearchCV は、各反復処理で各ハイパーパラメータの値をランダムにサンプリングするため、1,000 回の反復処理で 1,000 通りの組み合わせが評価されます。それ以外は GridSearchCV とほぼ同じように動作します。
xgboostをインポートする必要があります。ライブラリがインストールされていない場合は、pip3 install xgboostを実行するか、または内部からインストールしてください。 Jupyter ノートブックの内容:
use import sys
!{sys.executable} -m pip install xgboost
次に、分類器と2つの検索ヘルパーをインポートします。
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
このScikitの次のステップ Python このチュートリアルでは、調整するパラメータを指定します。公式のXGBoostドキュメントには、それらすべてがリストされています。 Python Sklearnのチュートリアルでは、XGBoostの学習には時間がかかり、グリッドポイントが増えるごとに待ち時間が長くなるため、2つのハイパーパラメータとそれぞれ2つの値のみを選択します。
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
次に、XGBoost分類器と600個の推定器を使用して新しいパイプラインを構築します。n_estimatorsは調整可能な値であり、値が大きいと過学習につながる可能性があります。他の値を試すこともできますが、数時間かかる場合があることに注意してください。その他のパラメータはすべてデフォルト値のままです。
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
層別K分割交差検証器を使用すると、交差検証の精度を向上させることができます。ここでは計算速度を上げるために3つの分割のみを使用していますが、その分精度が若干低下します。より良い結果を得るには、ご自身のマシンで分割数を5または10に増やしてください。モデルは4回の反復で学習されます。
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
ランダム探索の準備ができたので、モデルのトレーニングを開始できます。
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
ご覧のとおり、XGBoostは以前のロジスティック回帰よりも優れたスコアを示しています。
print("Best parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
scikit-learn で MLPClassifier を使用して DNN を作成する
最後に、scikit-learn自体を使ってニューラルネットワークを学習させることもできます。学習方法は他の分類器と同じで、推定器はMLPClassifierです。
from sklearn.neural_network import MLPClassifier
以下のネットワークは以下のように定義されます。
- アダムソルバー
- ReLU活性化機能
- アルファ = 0.0001
- バッチサイズ150
- それぞれ 200 個と 100 個のニューロンを持つ XNUMX つの隠れ層
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
レイヤー数を変更することで、モデルの精度を向上させることができます。
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN 回帰スコア: 0.821253
ライム: 自分のモデルを信頼してください
優れたモデルができたとしても、それを信頼する方法が必要です。機械学習アルゴリズム、特にランダムフォレストやニューラルネットワークは、ブラックボックスモデルとして知られています。つまり、機能はするものの、その理由を誰も理解できないのです。
3人の研究者が、コンピューターが予測に至る過程を示すツールを開発した。彼らの論文は 「なぜあなたを信用しなければならないのですか?」そして、彼らが発表したアルゴリズムは、ローカル解釈可能モデル非依存説明(LIME)と呼ばれています。
例えば、機械学習による予測が信頼できるかどうか分からない場合があります。医師はコンピューターが出した診断結果を鵜呑みにすることはできませんし、モデルを実運用に導入する前に、その信頼性を確認する必要があります。
ニューラルネットワーク、ランダムフォレスト、任意のカーネルを持つSVMなど、複雑なモデルであっても、分類器がなぜ予測を行ったのかを視覚的に確認できるとしたらどうでしょうか。予測の根拠が明確になれば、その予測を信頼しやすくなり、同時に、モデルを信頼すべきでないかどうかを判断するのも容易になります。LIMEは、分類器の決定を左右した特徴量を示します。
データの準備
LIMEを実行するには、いくつか変更する必要があります。 Pythonまず、ターミナルで pip install lime コマンドを実行して lime をインストールします。
Limeは、LimeTabularExplainerオブジェクトを使用してモデルをローカルで近似します。このオブジェクトには以下が必要です。
- データセット NumPy 形式でアーカイブしたプロジェクトを保存します.
- 機能の名前: feature_names
- クラスの名前: class_names
- カテゴリ特徴量の列のインデックス: categorical_features
- 各カテゴリ特徴量のグループ名:categorical_names
NumPyトレインセットを作成する
pandasのdf_trainをNumPyにコピーして変換するのは非常に簡単です。
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
クラス名を取得する
ラベルはunique()関数でアクセスできます。以下のような表示になるはずです。
- '<= 50K'
- '> 50K'
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
カテゴリカル特徴列にインデックスを付ける
先に学習した方法を使って、各グループの名前を取得します。ラベルをLabelEncoderでエンコードし、この操作をすべてのカテゴリカル特徴量に対して繰り返します。
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
データセットの準備ができたので、以下の Scikit learn の例に示すさまざまなデータセットを作成できます。LIME でエラーが発生しないように、ここではパイプラインの外でデータを変換しています。LimeTabularExplainer に渡されるトレーニングセットは文字列を含まない NumPy 配列である必要があり、上記の方法ですでにそのような配列が生成されています。
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
XGBoostによって見つかった最適なパラメータを使用してパイプラインを作成できます。
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
警告が表示されます。パイプラインの前にラベルエンコーダを作成する必要はないことが説明されています。LIMEを使用していない場合は、このScikit-learnを使った機械学習チュートリアルの最初の部分で説明した方法で問題ありません。それ以外の場合は、次の方法を維持してください。まずエンコードされたデータセットを作成し、次にパイプライン内でワンホットエンコーダを適用します。
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
LIMEを実行する前に、誤って分類された行の特徴量を格納するNumPy配列を作成してください。このリストは後で、分類器が誤った判断を下した原因を把握するために使用できます。
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826、16)
次に、新しいデータに対するモデルからの予測値を取得するラムダ関数を作成します。これは後ほど必要になります。
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
pandasデータフレームをNumPy配列に変換します。
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
それでは、テストセットからランダムに世帯を選び、予測結果と、コンピューターがどのようにしてその予測に至ったのかを確認してみましょう。
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
explain_instance と組み合わせた説明ツールを使用すると、モデルの背後にある論理的根拠を検証できます。表示されるグラフは以下のとおりです。
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

分類器はこの世帯を正しく予測しました。収入は確かに50万ドルを超えています。
まず注目すべき点は、この分類器の予測精度がそれほど高くないことです。50万ドル以上の収入を64%の確率で予測していますが、この64%という確率は、キャピタルゲインと婚姻状況によって左右されています。青色はプラスのクラスにマイナスの影響を与え、オレンジ色の線はプラスの影響を与えています。
この世帯のキャピタルゲインはゼロであるため、分類器は判断に迷っています。キャピタルゲインは通常、富裕度を予測する上で有効な指標となるからです。また、この世帯の労働時間は週40時間未満です。年齢、職業、性別はすべてプラスに寄与しています。
婚姻状況が独身の場合、分類器は収入が50万ドル未満であると予測しただろう(0.64 - 0.18 = 0.46)。
今度は、誤って分類された別の世帯を試してみましょう。その世帯の説明表は、コードの後に続きます。
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

分類器は収入が50万ドル未満と予測しましたが、これは誤りです。この世帯は特殊で、キャピタルゲインもキャピタルロスもなく、離婚歴があり、60歳近くで、教育水準も高く(education_num > 12)、全体的な傾向から、分類器はこの世帯の収入を50万ドル未満と判定しました。
LIMEを実際に使ってみると、分類器に多くの明らかな誤りがあることに気づくでしょう。ライブラリ作者のGitHubリポジトリには、画像とテキストの分類に関する追加ドキュメントが掲載されています。
Scikit-learn コマンドリファレンス
以下は、scikit-learn バージョン 0.20 以降に適用される便利なコマンドの一覧です。
| 仕事 | 関数またはクラス |
|---|---|
| トレーニング/テストデータセットを作成する | train_test_split |
| パイプラインを構築する | |
| 列を選択して変換を適用する | 列変換を作成する |
| 変換の種類 | |
| 標準化 | StandardScaler |
| 最小最大スケーリング | MinMaxScaler |
| ノーマライズ | ノーマライザー |
| 欠損値を補完する | SimpleImputer |
| カテゴリカルに変換する | OneHotEncoder |
| データを適合させて変換する | フィットトランスフォーム |
| パイプラインを作る | パイプラインの作成 |
| ベーシックモデル | |
| ロジスティック回帰 | ロジスティック回帰 |
| XGブースト | XGB分類子 |
| ニューラルネット | MLP分類子 |
| グリッド検索 | GridSearchCV |
| ランダム検索 | ランダム化検索CV |