MongoDB 正規表現($regex)とその例
⚡ スマートサマリー
MongoDB 正規表現は、$regex演算子、大文字小文字を区別しないための$optionsフラグ、完全一致のためのアンカー、および正確なフィールド値が不明な場合のスラッシュ区切り文字を使用して、ドキュメント内の文字列を検索するためにパターンマッチングを実行します。

正規表現はパターンマッチングに使用され、これは基本的に文書内の文字列を検索するために使用されます。
コレクション内のドキュメントを取得するときに、検索する正確なフィールド値が正確にわからない場合があります。 したがって、正規表現を使用すると、パターン マッチング検索値に基づいたデータの取得を支援できます。
パターンマッチングに$regex演算子を使用する
$regex 演算子 MongoDB コレクション内の特定の文字列を検索するために使用されます。次の例は、これがどのように実行されるかを示しています。
フィールド名が「Employeeid」と「EmployeeName」である、同じ従業員コレクションがあると仮定します。また、コレクションには以下のドキュメントが含まれていると仮定します。
| 従業員ID | 従業員名 |
|---|---|
| 22 | ニューマーティン |
| 2 | モハン |
| 3 | ジョー |
| 4 | モハンR |
| 100 | Guru99 |
| 6 | 年 |
以下のコードでは、$regex演算子を使用して検索条件を指定しています。

db.Employee.find({EmployeeName : {$regex: "Gu" }}).forEach(printjson)
Code 説明:
- ここでは、「Gu」という文字を含むすべての従業員名を検索します。そのため、$regex演算子を使用して「Gu」という検索条件を定義します。
- printjson は、クエリによって返された各ドキュメントをより適切な方法で印刷するために使用されます。
コマンドが正常に実行されると、次の出力が表示されます。
出力:

出力には、従業員名に「Gu」文字が含まれるドキュメントが返されることが明確に示されています。
コレクションに以下の文書があり、従業員名が「Guru検索条件を「999」と入力した場合Guru99」という文字列を含む文書も返されます。Guru999」。しかし、もし私たちがこれを望まず、単に「999」というドキュメントを返したいだけだったらどうでしょう。Guru99」。次に、正確なパターンマッチングでこれを行うことができます。正確なパターンマッチングを行うには、^ と $ 文字を使用します。文字列の先頭に ^ 文字を追加し、文字列の末尾に $ を追加します。
| 従業員ID | 従業員名 |
|---|---|
| 22 | ニューマーティン |
| 2 | モハン |
| 3 | ジョー |
| 4 | モハンR |
| 100 | Guru99 |
| 6 | 年 |
| 8 | Guru999 |
次の例は、これを実行する方法を示しています。

db.Employee.find({EmployeeName : {$regex: "^Guru99$"}}).forEach(printjson)
Code 説明:
- 検索条件では、^ と $ 文字を使用しています。^ は文字列が特定の文字で始まることを保証するために使用され、$ は文字列が特定の文字で終わることを保証するために使用されます。したがって、コードが実行されると、名前が「Guru99。 "
- printjson は、クエリによって返された各ドキュメントをより適切な方法で印刷するために使用されます。
コマンドが正常に実行されると、次の出力が表示されます。
出力:
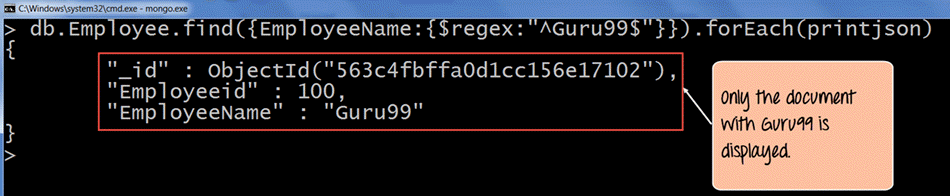
出力では、文字列「Guru99”が取得されました。
$options を使用したパターン マッチング
$regex 演算子を使用する場合、以下のオプションを追加することもできます。 $ options キーワード。 たとえば、大文字と小文字が区別されるかどうかに関係なく、従業員名に「Gu」が含まれるすべてのドキュメントを検索したいとします。 そのような結果が必要な場合は、次を使用する必要があります。 $ options 大文字小文字を区別しないパラメータを使用。
次の例は、これを実行する方法を示しています。
「Employeeid」と「EmployeeName」というフィールド名を持つ、同じ従業員コレクションがあると仮定しましょう。
また、私たちのコレクションには以下の文書が含まれていると仮定しましょう。
| 従業員ID | 従業員名 |
|---|---|
| 22 | ニューマーティン |
| 2 | モハン |
| 3 | ジョー |
| 4 | モハンR |
| 100 | Guru99 |
| 6 | 年 |
| 7 | 達人99 |
さて、前回のトピックと同じクエリを実行しても、結果に「GURU99」を含むドキュメントは表示されません。このドキュメントが結果セットに含まれるようにするには、$options パラメータに「i」を追加する必要があります。

db.Employee.find({EmployeeName:{$regex: "Gu",$options:'i'}}).forEach(printjson)
Code 説明:
- 'i' パラメータ (大文字小文字を区別しないことを意味します) を指定した $options は、'Gu' という文字が小文字でも大文字でも検索を実行することを指定します。
コマンドが正常に実行されると、次の出力が表示されます。
出力:
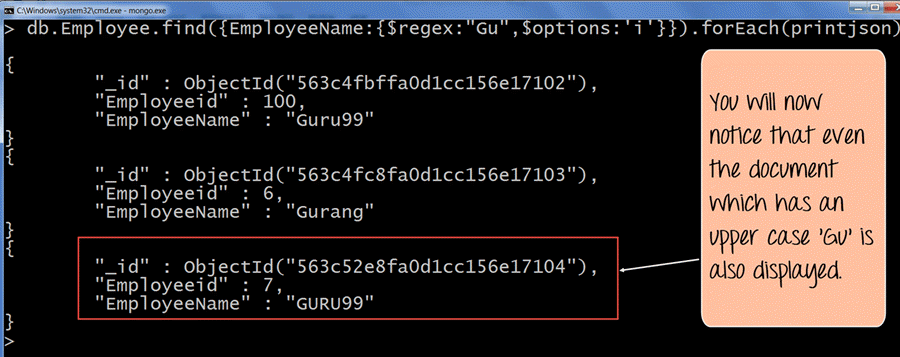
- 出力結果から明らかなように、ある文書に大文字の「Gu」が含まれていても、その文書は結果セットに表示されます。
正規表現演算子を使用しないパターンマッチング
正規表現演算子($regex)を使わずにパターンマッチングを行うこともできます。以下の例は、その方法を示しています。

db.Employee.find({EmployeeName: /Gu/}).forEach(printjson)
Code 説明:
- 「//」区切り文字は、基本的にこれらの区切り文字内で検索条件を指定することを意味します。したがって、従業員名に「Gu」が含まれる文書を検索するために、/Gu/ と指定しています。
コマンドが正常に実行されると、次の出力が表示されます。
出力:
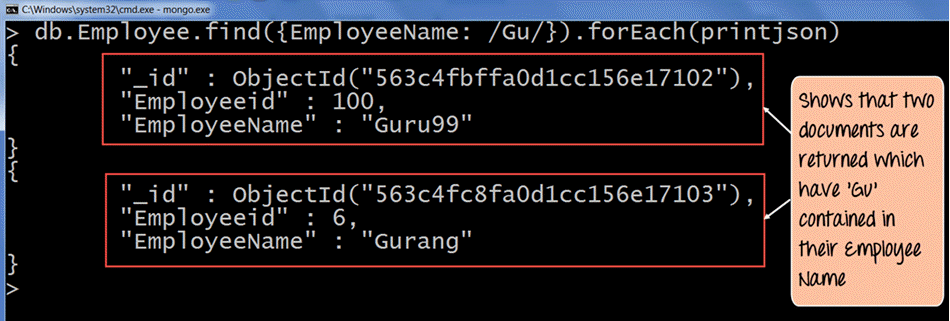
出力には、従業員名に「Gu」文字が含まれるドキュメントが返されることが明確に示されています。
コレクションから最後の「n」個のドキュメントを取得する
コレクション内の最後の n 個のドキュメントを取得するには、さまざまな方法があります。
それでは、以下の手順を通して、その方法の一つを見ていきましょう。
次の例は、これを実行する方法を示しています。
「Employeeid」と「EmployeeName」というフィールド名を持つ、同じ従業員コレクションがあると仮定しましょう。
また、私たちのコレクションには以下の文書が含まれていると仮定しましょう。
| 従業員ID | 従業員名 |
|---|---|
| 22 | ニューマーティン |
| 2 | モハン |
| 3 | ジョー |
| 4 | モハンR |
| 100 | Guru99 |
| 6 | 年 |
| 7 | 達人99 |
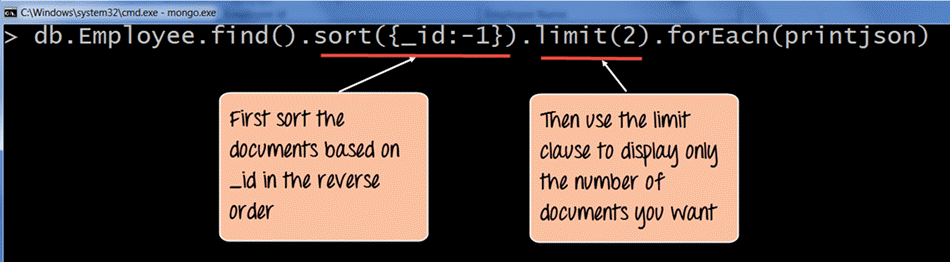
db.Employee.find().sort({_id:-1}).limit(2).forEach(printjson)
Code 説明:
- ドキュメントをクエリする際は、ソート機能を使用して、コレクション内の_idフィールドの値に基づいてレコードを逆順に並べ替えます。-1は基本的に、ドキュメントを逆順(降順)に並べ替えることを意味し、最後のドキュメントが最初に表示されるようになります。
- 次に、limit句を使用して、表示したいレコード数だけを表示します。ここではlimit句(2)を設定しているので、最後の2つのドキュメントが取得されます。
コマンドが正常に実行されると、次の出力が表示されます。
出力:
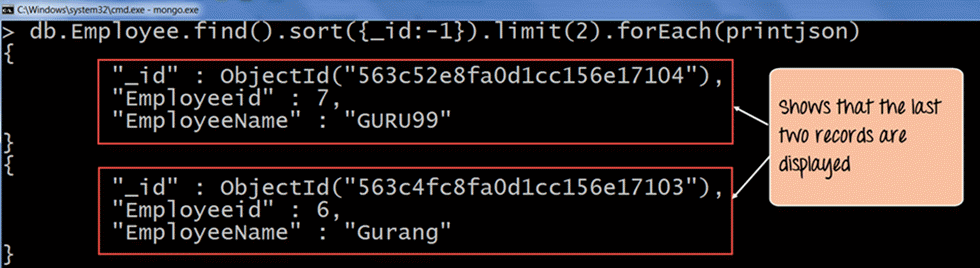
出力には、コレクション内の最後の 2 つのドキュメントが表示されていることが明確に示されています。したがって、コレクション内の最後の 'n' 個のドキュメントを取得するには、まずドキュメントを降順で並べ替え、次に limit 句を使用して必要な 'n' 個のドキュメントを返すことができることが明確に示されています。
お願い注: 38,000 文字を超える文字列に対して検索を実行すると、正しい結果が表示されません。