Apprendimento automatico supervisionato: cos'è Algorithms con esempi
Che cos'è l'apprendimento automatico supervisionato?
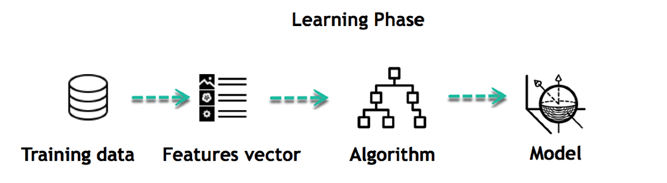
Apprendimento automatico supervisionato è un algoritmo che apprende dai dati di addestramento etichettati per aiutarti a prevedere i risultati per dati imprevisti. Nell'apprendimento supervisionato, si addestra la macchina utilizzando dati ben "etichettati". Significa che alcuni dati sono già contrassegnati con risposte corrette. Può essere paragonato all’apprendimento in presenza di un supervisore o di un insegnante.
Creazione, scalabilità e distribuzione di successo preciso I modelli di machine learning supervisionati richiedono tempo e competenze tecniche da parte di un team di data scientist altamente qualificati. Inoltre, Dati lo scienziato deve ricostruire modelli per garantire che le informazioni fornite rimangano vere fino a quando i dati non cambiano.
Come funziona l'apprendimento supervisionato
L'apprendimento automatico supervisionato utilizza set di dati di addestramento per ottenere i risultati desiderati. Questi set di dati contengono input e l'output corretto che aiuta il modello ad apprendere più velocemente. Ad esempio, vuoi addestrare una macchina per aiutarti a prevedere quanto tempo impiegherai per tornare a casa dal posto di lavoro.
Qui inizierai creando un set di dati etichettati. Questi dati includono:
- Condizioni meteo
- Ora del giorno
- Festività
Tutti questi dettagli sono i tuoi input in questo esempio di apprendimento supervisionato. L'output è la quantità di tempo impiegata per tornare a casa in quel giorno specifico.

Sai istintivamente che se fuori piove, ci vorrà più tempo per tornare a casa. Ma la macchina ha bisogno di dati e statistiche.
Vediamo alcuni esempi di apprendimento supervisionato su come sviluppare un modello di apprendimento supervisionato di questo esempio che aiuti l'utente a determinare il tempo di percorrenza. La prima cosa che devi creare è un set di allenamento. Questo set di allenamento conterrà il tempo totale del tragitto giornaliero e i fattori corrispondenti come il tempo, il tempo, ecc. In base a questo set di allenamento, la tua macchina potrebbe vedere che esiste una relazione diretta tra la quantità di pioggia e il tempo che impiegherai per tornare a casa.
Quindi, accerta che più piove, più a lungo dovrai guidare per tornare a casa. Potrebbe anche vedere la connessione tra il momento in cui lasci il lavoro e il tempo in cui sarai in viaggio.
Più sei vicino alle 6, più tempo impiegherai per tornare a casa. La tua macchina potrebbe trovare alcune relazioni con i tuoi dati etichettati.
Questo è l'inizio del tuo modello di dati. Inizia a influenzare il modo in cui la pioggia influisce sul modo in cui le persone guidano. Si comincia anche a notare che sempre più persone viaggiano in un determinato momento della giornata.
Tipi di machine learning supervisionato Algorithms
Di seguito sono riportati i tipi di algoritmi di apprendimento automatico supervisionato:
Regressione
La tecnica di regressione prevede un singolo valore di output utilizzando i dati di training.
Esempio: puoi utilizzare la regressione per prevedere il prezzo della casa dai dati di addestramento. Le variabili di input saranno la località, la dimensione di una casa, ecc.
Punti di forza: Gli output hanno sempre un'interpretazione probabilistica e l'algoritmo può essere regolarizzato per evitare un overfitting.
Punti di debolezza: La regressione logistica potrebbe avere prestazioni inferiori quando ci sono confini decisionali multipli o non lineari. Questo metodo non è flessibile, quindi non cattura relazioni più complesse.
Regressione logistica:
Metodo di regressione logistica utilizzato per stimare valori discreti sulla base di un insieme di variabili indipendenti. Ti aiuta a prevedere la probabilità che si verifichi un evento adattando i dati a una funzione logit. Pertanto, è anche noto come regressione logistica. Poiché prevede la probabilità, il suo valore di output è compreso tra 0 e 1.
Ecco alcuni tipi di regressione Algorithms
Classificazione
Classificare significa raggruppare l'output all'interno di una classe. Se l'algoritmo tenta di etichettare l'input in due classi distinte, si parla di classificazione binaria. La selezione tra più di due classi viene definita classificazione multiclasse.
Esempio: Determinare se qualcuno sarà o meno inadempiente rispetto al prestito.
Punti di forza: Gli alberi di classificazione funzionano molto bene nella pratica
Punti di debolezza: Senza vincoli, i singoli alberi tendono a sovradimensionarsi.
Ecco alcuni tipi di classificazione Algorithms
Classificatori Naive Bayes
Il modello Naive Bayesiano (NBN) è facile da costruire e molto utile per set di dati di grandi dimensioni. Questo metodo è composto da grafici aciclici diretti con un genitore e diversi figli. Presuppone l'indipendenza tra i nodi figli separati dal genitore.
Alberi decisionali
Gli alberi decisionali classificano le istanze ordinandole in base al valore della caratteristica. In questo metodo, ciascuna modalità è la caratteristica di un'istanza. Va classificato, ed ogni ramo rappresenta un valore che il nodo può assumere. È una tecnica ampiamente utilizzata per la classificazione. In questo metodo, la classificazione è un albero noto come albero decisionale.
Ti aiuta a stimare i valori reali (costo di acquisto di un'auto, numero di chiamate, vendite mensili totali, ecc.).
Supporta la macchina vettoriale
La Support Vector Machine (SVM) è un tipo di algoritmo di apprendimento sviluppato nel 1990. Questo metodo si basa sui risultati della teoria dell'apprendimento statistico introdotta da Vap Nik.
Le macchine SVM sono anche strettamente connesse alle funzioni del kernel, che è un concetto centrale per la maggior parte delle attività di apprendimento. Il framework del kernel e SVM sono utilizzati in una varietà di campi. Include il recupero di informazioni multimediali, la bioinformatica e il riconoscimento di modelli.
Tecniche di apprendimento automatico supervisionato e non supervisionato
| Basato su | Tecnica di machine learning supervisionata | Tecnica di machine learning non supervisionata |
|---|---|---|
| Dati in ingresso | Algorithms vengono addestrati utilizzando dati etichettati. | Algorithms vengono utilizzati rispetto a dati non etichettati |
| Complessità computazionale | L’apprendimento supervisionato è un metodo più semplice. | L'apprendimento non supervisionato è computazionalmente complesso |
| Precisione | Metodo estremamente accurato e affidabile. | Less metodo accurato e affidabile. |
Sfide nell'apprendimento automatico supervisionato
Ecco le sfide affrontate nell'apprendimento automatico supervisionato:
- La funzione di input irrilevante presente nei dati di addestramento potrebbe fornire risultati imprecisi
- La preparazione e la pre-elaborazione dei dati rappresentano sempre una sfida.
- La precisione soffre quando vengono immessi valori impossibili, improbabili e incompleti come dati di training
- Se l’esperto interessato non è disponibile, l’altro approccio è la “forza bruta”. Significa che devi pensare alle giuste funzionalità (variabili di input) su cui addestrare la macchina. Potrebbe essere impreciso.
Vantaggi dell'apprendimento supervisionato
Ecco i vantaggi dell’apprendimento automatico supervisionato:
- Apprendimento supervisionato in machine Learning consente di raccogliere dati o produrre un output di dati dall'esperienza precedente
- Ti aiuta a ottimizzare i criteri di prestazione utilizzando l'esperienza
- L'apprendimento automatico supervisionato ti aiuta a risolvere vari tipi di problemi di calcolo del mondo reale.
Svantaggi dell'apprendimento supervisionato
Di seguito sono riportati gli svantaggi dell’apprendimento automatico supervisionato:
- Il limite decisionale potrebbe essere eccessivo se il tuo set di formazione non contiene esempi che desideri avere in una classe
- Devi selezionare molti buoni esempi da ogni classe mentre stai addestrando il classificatore.
- Classificazione Big Data può essere una vera sfida.
- La formazione per l’apprendimento supervisionato richiede molto tempo di calcolo.
migliori pratiche per l'apprendimento supervisionato
- Prima di fare qualsiasi altra cosa, è necessario decidere quale tipo di dati utilizzare come set di addestramento
- È necessario decidere la struttura della funzione appresa e dell'algoritmo di apprendimento.
- Raccogliere i risultati corrispondenti da esperti umani o da misurazioni
Sintesi
- Negli algoritmi di apprendimento supervisionato, si addestra la macchina utilizzando dati ben “etichettati”.
- Vuoi addestrare una macchina che ti aiuti a prevedere quanto tempo impiegherai per tornare a casa dal tuo posto di lavoro è un esempio di apprendimento supervisionato.
- Regressione e classificazione sono due dimensioni di un algoritmo di apprendimento automatico supervisionato.
- Apprendimento supervisionato è un metodo più semplice mentre l'apprendimento non supervisionato è un metodo complesso.
- La sfida più grande nell'apprendimento supervisionato è che la funzionalità di input irrilevante presente nei dati di formazione potrebbe fornire risultati imprecisi.
- Il vantaggio principale dell'apprendimento supervisionato è che consente di raccogliere dati o produrre un output di dati dall'esperienza precedente.
- Lo svantaggio di questo modello è che il limite decisionale potrebbe essere eccessivo se il tuo set di formazione non contiene esempi che desideri avere in una classe.
- Come best practice per supervisionare l'apprendimento, è necessario prima decidere quale tipo di dati utilizzare come set di formazione.