Penyematan Kata dan Word2Vec dengan Contoh
⚡ Ringkasan Cerdas
Word Embedding dan Word2Vec mengubah teks menjadi vektor numerik padat sehingga model pembelajaran mesin dapat mengenali kata-kata dengan makna yang serupa. Sumber daya ini menjelaskan teknik tersebut, arsitektur CBOW dan Skip-Gram, fungsi aktivasi, dan implementasi Gensim lengkap untuk aplikasi nyata.
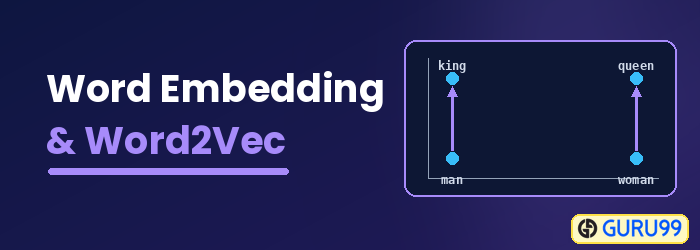
Apa itu Penyematan Kata?
Penyematan Kata adalah tipe representasi kata yang memungkinkan algoritma pembelajaran mesin untuk memahami kata-kata dengan makna yang serupa. Ini adalah teknik pemodelan bahasa dan pembelajaran fitur untuk memetakan kata-kata ke dalam vektor bilangan riil menggunakan jaringan saraf, model probabilistik, atau pengurangan dimensi pada matriks kemunculan bersama kata. Beberapa model penyematan kata adalah Word2vec (Google), GloVe (Stanford), dan fastText (Facebook).
Word Embedding juga disebut model semantik terdistribusi, model representasi terdistribusi, ruang vektor semantik, atau model ruang vektor. Saat Anda membaca nama-nama ini, Anda akan menemukan kata semantik, yang berarti mengkategorikan kata-kata yang serupa bersama-sama. Misalnya, buah-buahan seperti apel, mangga, dan pisang harus ditempatkan berdekatan, sedangkan buku akan ditempatkan berjauhan dari kata-kata tersebut. Dalam arti yang lebih luas, word embedding akan membuat vektor buah-buahan yang ditempatkan jauh dari representasi vektor buku.
Di mana Penyematan Kata digunakan?
Penyematan kata (word embedding) membantu dalam pembuatan fitur, pengelompokan dokumen, klasifikasi teks, dan tugas pemrosesan bahasa alami. Mari kita daftarkan aplikasi-aplikasi ini dan bahas masing-masing.
- Hitung kata-kata serupa: Word embedding digunakan untuk menyarankan kata-kata yang mirip dengan kata yang menjadi subjek model prediksi. Selain itu, word embedding juga menyarankan kata-kata yang tidak mirip, serta kata-kata yang paling umum.
- Buatlah sekelompok kata terkait: Ini digunakan untuk grup semantik.pingyang mengelompokkan hal-hal dengan karakteristik serupa dan menjauhkan hal-hal yang berbeda.
- Fitur untuk klasifikasi teks: Teks dipetakan ke dalam larik vektor yang kemudian dimasukkan ke dalam model untuk pelatihan dan prediksi. Model pengklasifikasi berbasis teks tidak dapat dilatih pada string, sehingga teks tersebut diubah menjadi bentuk yang dapat dilatih oleh mesin. Fitur pembentukan semantiknya semakin membantu dalam klasifikasi berbasis teks.
- Pengelompokan dokumen: Ini adalah aplikasi lain di mana Word Embedding dan Word2vec banyak digunakan.
- Pemrosesan bahasa alami: Ada banyak aplikasi di mana penyematan kata (word embedding) berguna dan lebih unggul daripada eksklusivitas fitur.tractahapan pemrosesan, seperti penandaan bagian ujaran, analisis sentimen, dan analisis sintaksis.
Setelah Anda memahami di mana word embedding diterapkan, mari kita lihat model paling populer yang digunakan untuk membuat embedding ini.
Apa itu Word2vec?
Kata2vec Ini adalah teknik atau model yang menghasilkan word embedding untuk representasi kata yang lebih baik. Ini adalah metode pemrosesan bahasa alami yang menangkap sejumlah besar hubungan sintaksis dan semantik kata yang tepat. Ini adalah jaringan saraf dua lapis dangkal yang dapat mendeteksi kata-kata sinonim dan menyarankan kata-kata tambahan untuk kalimat parsial setelah dilatih.
Sebelum melanjutkan, silakan lihat perbedaan antara jaringan saraf dangkal dan jaringan saraf dalam seperti yang ditunjukkan pada diagram contoh penyematan kata di bawah ini:
Jaringan saraf dangkal hanya terdiri dari satu lapisan tersembunyi antara input dan output, sedangkan jaringan saraf dalam berisi banyak lapisan tersembunyi antara input dan output. Input dikenakan pada node, sedangkan lapisan tersembunyi, serta lapisan output, berisi neuron.
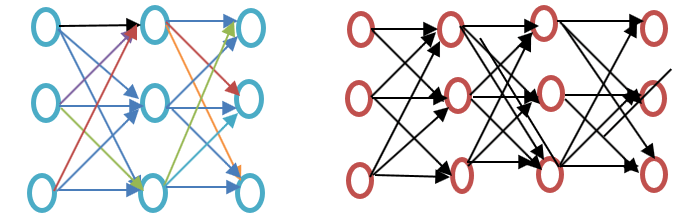
Word2vec adalah jaringan dua lapis yang terdiri dari satu lapisan masukan, satu lapisan tersembunyi, dan satu lapisan keluaran.
Word2vec dikembangkan oleh sekelompok peneliti yang dipimpin oleh Tomas Mikolov di GoogleWord2vec lebih baik dan lebih efisien daripada model analisis semantik laten.
Mengapa Word2vec?
Word2vec merepresentasikan kata-kata dalam representasi ruang vektor. Kata-kata direpresentasikan dalam bentuk vektor, dan penempatannya dilakukan sedemikian rupa sehingga kata-kata yang memiliki arti serupa muncul bersamaan dan kata-kata yang berbeda arti terletak berjauhan. Ini juga disebut hubungan semantik. Jaringan saraf tidak memahami teks; sebaliknya, mereka hanya memahami angka. Word Embedding menyediakan cara untuk mengubah teks menjadi vektor numerik.
Word2vec merekonstruksi konteks linguistik kata-kata. Sebelum melanjutkan, mari kita pahami apa itu konteks linguistik. Dalam skenario umum, ketika kita berbicara atau menulis untuk berkomunikasi, orang lain mencoba memahami tujuan kalimat tersebut. Misalnya, “Berapa suhu India?” Di sini, konteksnya adalah pengguna ingin mengetahui “suhu India.” Singkatnya, tujuan utama sebuah kalimat adalah konteks. Kata-kata atau kalimat yang mengelilingi bahasa lisan atau tulisan membantu menentukan makna konteks. Word2vec mempelajari representasi vektor kata-kata melalui konteks-konteks ini.
Apa yang dilakukan Word2vec?
Sebelum Penyematan Kata
Penting untuk mengetahui pendekatan apa yang digunakan sebelum word embedding dan apa kekurangannya, kemudian kita akan melihat bagaimana kekurangan tersebut diatasi oleh word embedding menggunakan pendekatan Word2vec. Terakhir, kita akan membahas cara kerja Word2vec, karena penting untuk memahami cara kerjanya.
Pendekatan Analisis Semantik Laten
Ini adalah pendekatan yang digunakan sebelum word embedding. Pendekatan ini menggunakan konsep Bag of Words, di mana kata-kata direpresentasikan dalam bentuk vektor yang dikodekan. Ini adalah representasi vektor jarang di mana dimensinya sama dengan ukuran kosakata. Jika kata tersebut muncul dalam kamus, maka kata tersebut dihitung; jika tidak, maka tidak dihitung. Untuk pemahaman lebih lanjut, silakan lihat program di bawah ini.
Contoh Word2vec

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Keluaran:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Penjelasan
- CountVectorizer adalah modul yang digunakan untuk menyimpan kosakata berdasarkan kesesuaian kata di dalamnya. Modul ini diimpor dari sklearn.
- Buat objeknya menggunakan kelas CountVectorizer.
- Tulis data ke dalam daftar yang akan dimasukkan ke dalam CountVectorizer.
- Data dimasukkan ke dalam objek yang dibuat dari kelas CountVectorizer.
- Terapkan pendekatan bag-of-words untuk menghitung kata dalam data menggunakan kosakata. Jika sebuah kata atau token tidak tersedia dalam kosakata, maka posisi indeks tersebut diatur menjadi nol.
- Variabel pada baris 5, yaitu x, dikonversi menjadi array (metode yang tersedia untuk x). Ini memberikan jumlah setiap token dalam kalimat atau daftar yang diberikan pada baris 3.
- Ini menunjukkan fitur-fitur yang menjadi bagian dari kosakata ketika disesuaikan menggunakan data pada baris 4.
Dalam pendekatan Semantik Laten, baris mewakili kata-kata unik, sedangkan kolom mewakili jumlah kemunculan kata tersebut dalam dokumen. Ini adalah representasi kata dalam bentuk matriks dokumen. Frekuensi Istilah-Frekuensi Dokumen Terbalik (TF-IDF) digunakan untuk menghitung frekuensi kata dalam dokumen, yaitu frekuensi istilah dalam dokumen dibagi dengan frekuensi istilah dalam seluruh korpus.
Kekurangan metode Bag of Words
- Ini mengabaikan urutan kata; misalnya, ini buruk = seburuk ini.
- Algoritma ini mengabaikan konteks kata-kata. Misalnya, kita menulis kalimat "Dia menyukai buku. Pendidikan paling baik ditemukan dalam buku." Algoritma ini akan membuat dua vektor: satu untuk "Dia menyukai buku" dan satu lagi untuk "Pendidikan paling baik ditemukan dalam buku." Algoritma ini akan memperlakukan keduanya sebagai ortogonal, yang membuatnya independen, tetapi pada kenyataannya, keduanya saling terkait.
Untuk mengatasi keterbatasan ini, word embedding dikembangkan, dan Word2vec adalah salah satu pendekatan yang digunakan untuk mengimplementasikannya.
Bagaimana Word2vec bekerja?
Word2vec mempelajari sebuah kata dengan memprediksi konteks di sekitarnya. Misalnya, mari kita ambil kata "He" (Dia). mencintai Sepak bola."
Kita ingin menghitung Word2vec untuk kata: mencintai.
Memperkirakan:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
kata mencintai Algoritma ini menelusuri setiap kata dalam korpus. Hubungan sintaksis dan semantik antar kata dikodekan. Hal ini membantu dalam menemukan kata-kata yang serupa dan analog.
Semua fitur acak dari kata tersebut mencintai dihitung. Fitur-fitur ini diubah atau diperbarui sehubungan dengan kata-kata tetangga atau konteks dengan bantuan sebuah Propagasi Kembali Metode.
Cara belajar lainnya adalah jika konteks dua kata serupa, atau dua kata memiliki ciri-ciri yang mirip, maka kata-kata tersebut berhubungan.
Kata2vec Architekstur
Ada dua arsitektur yang digunakan oleh Word2vec:
- Continuous Bag of Words (CBOW)
- Lewati-gram
Sebelum melanjutkan, mari kita bahas mengapa arsitektur atau model ini penting dari sudut pandang representasi kata. Pembelajaran representasi kata pada dasarnya tidak diawasi (unsupervised), tetapi target/label diperlukan untuk melatih model. Skip-gram dan CBOW mengubah representasi yang tidak diawasi menjadi bentuk yang diawasi (supervised) untuk pelatihan model.
Dalam CBOW, kata saat ini diprediksi menggunakan jendela konteks di sekitarnya. Misalnya, jika wi-1, Wi-2, Wi + 1, Wi + 2 diberi kata-kata atau konteks, model ini akan memberikan wi.
Skip-Gram melakukan kebalikan dari CBOW, yang berarti ia memprediksi urutan atau konteks yang diberikan dari kata tersebut. Anda dapat membalikkan contohnya untuk memahaminya. Jika wi jika diberikan, ini akan memprediksi konteksnya, atau wi-1, Wi-2, Wi + 1, Wi + 2.
Word2vec menyediakan opsi untuk memilih antara CBOW (Continuous Bag of Words) dan skip-gram. Parameter tersebut diberikan selama pelatihan model. Kita dapat memilih untuk menggunakan negative sampling atau lapisan hierarchical softmax.
Kantong Kata Berkelanjutan
Mari kita gambar diagram contoh Word2vec sederhana untuk memahami arsitektur bag-of-words yang berkelanjutan.

Mari kita hitung persamaannya secara matematis. Misalkan V adalah ukuran kosakata dan N adalah ukuran lapisan tersembunyi. Masukan didefinisikan sebagai { xi-1, Xi-2, Xi + 1, Xi + 2 Kita memperoleh matriks bobot dengan mengalikan V * N. Matriks lain diperoleh dengan mengalikan vektor input dengan matriks bobot. Hal ini juga dapat dipahami melalui persamaan berikut.
h = xitW
dimana xit dan W masing-masing adalah vektor input dan matriks bobot.
Untuk menghitung kecocokan antara konteks dan kata berikutnya, silakan lihat persamaan di bawah ini.
u = representasi prediksi * h
di mana representasi yang diprediksi diperoleh dari model pada persamaan di atas.
Model Lewati Gram
Pendekatan Skip-Gram digunakan untuk memprediksi kalimat berdasarkan kata masukan. Untuk memahaminya lebih baik, mari kita gambar diagram yang ditunjukkan pada contoh Word2vec di bawah ini.

Kita dapat menganggapnya sebagai kebalikan dari model Continuous Bag of Words, di mana inputnya adalah kata dan model menyediakan konteks atau urutan. Kita juga dapat menyimpulkan bahwa target dimasukkan sebagai input, dan lapisan output direplikasi beberapa kali untuk mengakomodasi jumlah kata konteks yang dipilih. Vektor kesalahan dari semua lapisan output dijumlahkan untuk menyesuaikan bobot melalui metode backpropagation.
Model mana yang harus dipilih?
CBOW beberapa kali lebih cepat daripada skip-gram dan memberikan frekuensi yang lebih baik untuk kata-kata yang sering muncul, sedangkan skip-gram hanya membutuhkan sedikit data pelatihan dan dapat merepresentasikan kata atau frasa yang jarang sekalipun. Tabel di bawah ini membandingkan kedua arsitektur tersebut secara sekilas.
| Aspek | CBOW | Lewati-Gram |
|---|---|---|
| Ramalan | Memprediksi kata target dari konteks. | Memprediksi konteks dari kata target |
| Kecepatan pelatihan | Lebih cepat | Lebih lambat |
| kata-kata yang sering digunakan | Akurasi yang lebih tinggi | Akurasi lebih rendah |
| Kata-kata langka | Representasi yang lebih lemah | Representasi yang lebih kuat |
| Data pelatihan | Membutuhkan lebih banyak data | Berfungsi dengan data yang lebih sedikit |
Hubungan antara Word2vec dan NLTK
NLTK adalah Alami Language ToolKit ini digunakan untuk pra-pemrosesan teks. Kita dapat melakukan berbagai operasi seperti penandaan bagian ujaran, lematisasi, stemming, penghapusan kata-kata penghenti (stop-word), dan penghapusan kata-kata langka atau yang jarang digunakan. Ini membantu membersihkan teks serta mempersiapkan fitur dari kata-kata yang efektif. Di sisi lain, Word2vec digunakan untuk pencocokan semantik (item yang terkait erat) dan sintaksis (urutan). Dengan menggunakan Word2vec, kita dapat menemukan kata-kata yang mirip, kata-kata yang tidak mirip, pengurangan dimensi, dan banyak lainnya. Fitur penting lainnya dari Word2vec adalah mengubah representasi teks berdimensi tinggi menjadi vektor berdimensi rendah.
Di mana menggunakan NLTK dan Word2vec?
Jika seseorang harus menyelesaikan beberapa tugas umum seperti yang disebutkan di atas, seperti tokenisasi, penandaan POS, dan penguraian, maka harus menggunakan NLTK, sedangkan untuk memprediksi kata berdasarkan konteks tertentu, pemodelan topik, atau kemiripan dokumen, harus menggunakan Word2vec.
Hubungan NLTK dan Word2vec dengan bantuan kode
NLTK dan Word2vec dapat digunakan bersama untuk menemukan representasi kata yang serupa atau pencocokan sintaksis. Toolkit NLTK dapat digunakan untuk memuat banyak paket yang disertakan dengan NLTK, dan model dapat dibuat menggunakan Word2vec. Kemudian dapat diuji pada kata-kata nyata. Mari kita lihat kombinasi keduanya dalam kode berikut. Sebelum melanjutkan, silakan lihat korpus yang disediakan NLTK. Anda dapat mengunduhnya menggunakan perintah:
nltk(nltk.download('all'))

Silakan lihat tangkapan layar untuk kodenya.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Keluaran:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
penjelasan dari Code
- Pustaka nltk diimpor, dari mana Anda dapat mengunduh korpus abc yang akan kita gunakan pada langkah selanjutnya.
- Gensim telah diimpor. Jika Gensim Word2vec belum terinstal, silakan instal menggunakan perintah “pip3 install gensim”. Silakan lihat tangkapan layar di bawah ini.

- Impor korpus abc, yang telah diunduh menggunakan nltk.download('abc').
- Kirimkan file-file tersebut ke model Word2vec, yang diimpor menggunakan Gensim, sebagai kalimat.
- Kosakata disimpan dalam bentuk variabel.
- Model tersebut diuji pada kata sampel. ilmu, karena berkas-berkas ini berkaitan dengan sains.
- Di sini, kata yang mirip dengan "sains" diprediksi oleh model tersebut.
Aktivator dan Word2Vec
Fungsi aktivasi suatu neuron mendefinisikan keluaran neuron tersebut berdasarkan serangkaian masukan. Konsep ini terinspirasi secara biologis oleh aktivitas di otak kita, di mana neuron yang berbeda diaktifkan menggunakan rangsangan yang berbeda. Mari kita pahami fungsi aktivasi melalui diagram berikut.

Di sini x1, x2, … x4 adalah node dari jaringan saraf.
w1, w2, w3 adalah bobot dari node.
Jumlah (Σ) dari semua bobot dan nilai node berfungsi sebagai fungsi aktivasi.
Mengapa fungsi Aktivasi?
Jika tidak menggunakan fungsi aktivasi, outputnya akan linear, tetapi fungsionalitas fungsi linear terbatas. Untuk mencapai fungsionalitas yang kompleks seperti deteksi objek, klasifikasi gambar, dll.ping Untuk pengolahan teks menggunakan suara, dan banyak keluaran non-linier lainnya, diperlukan fungsi aktivasi.
Bagaimana lapisan aktivasi dihitung dalam penyematan kata (Word2vec)
Lapisan Softmax (fungsi eksponensial yang dinormalisasi) adalah fungsi lapisan keluaran yang mengaktifkan atau memicu setiap node. Pendekatan lain yang digunakan adalah Hierarchical softmax, di mana kompleksitasnya dihitung dengan O(log2V), sedangkan pada softmax kompleksitasnya adalah O(V), di mana V adalah ukuran kosakata. Perbedaan antara keduanya terletak pada pengurangan kompleksitas pada lapisan softmax hierarkis. Untuk memahami fungsinya, silakan lihat contoh Word embedding di bawah ini:

Misalkan kita ingin menghitung probabilitas mengamati kata tersebut cinta dengan konteks tertentu. Alur dari akar ke simpul daun pertama-tama akan bergerak ke simpul 2 dan kemudian ke simpul 5. Jadi jika kita memiliki ukuran kosakata 8, hanya tiga perhitungan yang dibutuhkan. Ini memungkinkan dekomposisi perhitungan probabilitas satu kata (cinta).
Apa saja pilihan lain yang tersedia selain Hierarchical Softmax?
Secara umum, opsi penyematan kata yang tersedia adalah Differentiated Softmax, CNN-Softmax, Importance Sampling, Adaptive Importance Sampling, Noise Contrastive Estimation, Negative Sampling, Self-Normalization, dan Infrequent Normalization.
Berbicara secara khusus tentang Word2vec, kami memiliki sampel negatif yang tersedia.
Negative Sampling adalah cara untuk mengambil sampel data pelatihan. Metode ini agak mirip dengan stochastic gradient descent, tetapi dengan beberapa perbedaan. Negative sampling hanya mencari contoh pelatihan negatif. Metode ini didasarkan pada estimasi kontras noise dan secara acak mengambil sampel kata-kata yang tidak ada dalam konteks. Ini adalah metode pelatihan yang cepat dan memilih konteks secara acak. Jika kata yang diprediksi muncul dalam konteks yang dipilih secara acak, kedua vektor akan berdekatan.
Kesimpulan apa yang bisa diambil?
Aktivator mengaktifkan neuron sama seperti neuron kita diaktifkan oleh rangsangan eksternal. Lapisan Softmax adalah salah satu fungsi lapisan keluaran yang mengaktifkan neuron dalam kasus word embedding. Di Word2vec, kita memiliki opsi seperti hierarchical softmax dan negative sampling. Dengan menggunakan aktivator, seseorang dapat mengubah fungsi linier menjadi fungsi non-linier, dan algoritma pembelajaran mesin yang kompleks dapat diimplementasikan menggunakan fungsi tersebut.
Apa itu Gensim?
Gensim adalah perangkat pemodelan topik sumber terbuka dan pemrosesan bahasa alami yang diimplementasikan di Python dan Cython. Toolkit Gensim memungkinkan pengguna untuk mengimpor Word2vec untuk pemodelan topik guna menemukan struktur tersembunyi dalam isi teks. Gensim tidak hanya menyediakan implementasi Word2vec tetapi juga Doc2vec dan FastText.
Bagian ini berfokus pada Word2vec, jadi kita akan tetap membahas topik yang sedang dibahas.
Bagaimana Mengimplementasikan Word2vec menggunakan Gensim
Sampai saat ini, kita telah membahas apa itu Word2vec, berbagai arsitekturnya, mengapa terjadi pergeseran dari bag of words ke Word2vec, hubungan antara Word2vec dan NLTK dengan live code, serta fungsi aktivasi.
Berikut adalah metode langkah demi langkah untuk mengimplementasikan Word2vec menggunakan Gensim:
Langkah 1) Pengumpulan Data
Langkah pertama untuk mengimplementasikan model pembelajaran mesin atau pemrosesan bahasa alami adalah pengumpulan data.
Harap amati data untuk membangun chatbot cerdas seperti yang ditunjukkan pada contoh Gensim Word2vec di bawah ini.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Berikut yang kami pahami dari data tersebut:
- Data ini berisi tiga hal: tag, pola, dan respons. Tag adalah maksud (apa topik diskusinya).
- Datanya dalam format JSON.
- Pola adalah pertanyaan yang akan diajukan pengguna kepada bot.
- Respons adalah jawaban yang akan diberikan oleh chatbot untuk pertanyaan/pola yang sesuai.
Langkah 2) Pemrosesan awal data
Sangat penting untuk memproses data mentah. Jika data yang sudah dibersihkan dimasukkan ke mesin, maka model akan merespons lebih akurat dan mempelajari data dengan lebih efisien.
Langkah ini melibatkan penghapusan kata-kata penghenti (stop words), stemming, kata-kata yang tidak perlu, dll. Sebelum melanjutkan, penting untuk memuat data dan mengubahnya menjadi data frame. Silakan lihat kode di bawah ini untuk hal tersebut.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
penjelasan dari Code:
- Karena data dalam format JSON, maka JSON diimpor.
- File tersebut disimpan dalam variabel.
- Berkas dibuka dan dimuat ke dalam variabel data.
Sekarang data telah diimpor, dan saatnya untuk mengkonversi data tersebut menjadi data frame. Silakan lihat kode di bawah ini untuk langkah selanjutnya.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
penjelasan dari Code:
1. Data dikonversi menjadi data frame menggunakan pandas, yang telah diimpor di atas.
2. Fungsi ini mengubah daftar dalam pola kolom menjadi string.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Penjelasan:
1. Kata-kata penghenti (stop words) dalam bahasa Inggris diimpor menggunakan modul stop-word dari toolkit nltk.
2. Semua kata dalam teks diubah menjadi huruf kecil menggunakan kondisi for dan fungsi lambda. A Fungsi Lambda adalah fungsi anonim.
3. Semua baris teks dalam data frame diperiksa untuk tanda baca string, dan baris-baris tersebut difilter.
4. Karakter seperti angka atau titik dihilangkan menggunakan ekspresi reguler.
5. Digits dihapus dari teks.
6. Kata-kata berhenti dihilangkan pada tahap ini.
7. Kata-kata sekarang disaring, dan berbagai bentuk dari kata yang sama dihilangkan menggunakan lematisasi. Dengan ini, kita telah menyelesaikan pra-pemrosesan data.
Keluaran:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Langkah 3) Membangun Jaringan Neural menggunakan Word2vec
Sekarang saatnya membangun model menggunakan modul Word2vec dari Gensim. Kita harus mengimpor Word2vec dari Gensim. Mari kita lakukan ini, lalu kita akan membangunnya, dan pada tahap akhir kita akan memeriksa model tersebut pada data waktu nyata.
from gensim.models import Word2Vec
Sekarang kita dapat berhasil membangun model menggunakan Word2Vec. Silakan lihat baris kode berikutnya untuk mempelajari cara membuat model menggunakan Word2Vec. Teks diberikan ke model dalam bentuk daftar, jadi kita akan mengkonversi teks dari data frame ke daftar menggunakan kode di bawah ini.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
penjelasan dari Code:
1. Membuat bigger_list tempat daftar bagian dalam ditambahkan. Ini adalah format yang dimasukkan ke model Word2Vec.
2. Sebuah perulangan diimplementasikan, dan setiap entri dari kolom pola pada data frame diulang.
3. Setiap elemen dari pola kolom dipisahkan dan disimpan dalam daftar dalam li.
4. Daftar dalam ditambahkan dengan daftar luar.
5. Daftar ini diberikan kepada model Word2Vec. Mari kita pahami beberapa parameter yang diberikan di sini.
Jumlah_min: Metode ini mengabaikan semua kata dengan total frekuensi lebih rendah dari nilai tersebut.
Ukuran: Ini menceritakan dimensi dari kata vektor.
Pekerja: Ini adalah thread yang digunakan untuk melatih model.
Tersedia juga pilihan lain, dan beberapa yang penting dijelaskan di bawah ini.
Jendela: Jarak maksimum antara kata saat ini dan kata yang diprediksi dalam sebuah kalimat.
Sg: Ini adalah algoritma pelatihan: 1 untuk skip-gram dan 0 untuk Continuous Bag of Words. Kita telah membahasnya secara detail di atas.
Hs: Jika nilainya 1, maka kita menggunakan softmax hierarkis untuk pelatihan, dan jika 0, maka digunakan pengambilan sampel negatif.
Alfa: Tingkat pembelajaran awal.
Mari kita tampilkan kode terakhir di bawah ini:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Langkah 4) Penghematan model
Model dapat disimpan dalam bentuk bin dan file model. Bin adalah format biner. Silakan lihat baris di bawah ini untuk menyimpan model.
model.save("word2vec.model") model.save("model.bin")
Penjelasan kode di atas
1. Model tersebut disimpan dalam bentuk file .model.
2. Model tersebut disimpan dalam bentuk file .bin.
Kami akan menggunakan model ini untuk melakukan pengujian secara real-time seperti kata-kata yang mirip, kata-kata yang tidak mirip, dan kata-kata yang paling umum.
Langkah 5) Memuat model dan melakukan pengujian waktu nyata
Model dimuat menggunakan kode di bawah ini:
model = Word2Vec.load('model.bin')
Jika Anda ingin mencetak kosakata dari situ, Anda dapat melakukannya menggunakan perintah di bawah ini:
vocab = list(model.wv.vocab)
Silakan lihat hasilnya:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Langkah 6) Pemeriksaan kata-kata yang paling mirip
Mari kita terapkan secara praktis:
similar_words = model.most_similar('thanks') print(similar_words)
Silakan lihat hasilnya:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Langkah 7) Tidak cocok dengan kata yang diberikan
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Kami telah menyediakan kata-katanya 'Sampai jumpa lagi, terima kasih sudah berkunjung'Kode ini mencetak kata yang paling berbeda dari kata-kata tersebut. Mari kita jalankan kode ini dan temukan hasilnya.
Hasil setelah eksekusi kode di atas:
Thanks
Langkah 8) Menemukan persamaan antara dua kata
Ini menunjukkan hasilnya dalam bentuk probabilitas kemiripan antara dua kata. Silakan lihat kode di bawah ini tentang cara menjalankan bagian ini.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Hasil dari kode di atas adalah sebagai berikut:
0.13706
Anda dapat menemukan kata-kata serupa lainnya dengan menjalankan kode di bawah ini:
similar = model.similar_by_word('kind') print(similar)
Output dari kode di atas:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]