Apache Flume bemutató: Mi az, Architecture és Hadoop példa
⚡ Okos összefoglaló
Az Apache Flume egy elosztott szolgáltatás nagy mennyiségű naplóadat gyűjtésére, összesítésére és HDFS-be mozgatására, amely olyan ügynökök köré épül, amelyek egy forrást, egy csatornát és egy nyelőt láncolnak össze.

Mi az Apache Flume a Hadoopban?
Az Apache Flume egy megbízható és elosztott rendszer hatalmas mennyiségű naplóadat gyűjtésére, összesítésére és mozgatására. Egyszerű, mégis rugalmas architektúrával rendelkezik, amely folyamatos adatfolyamokon alapul. Az Apache Flume a webszerverekről származó naplófájlokban található naplóadatok gyűjtésére és összesítésére szolgál. HDFS elemzéshez.
A Hadoop Flume több forrást is támogat, beleértve:
- „tail” (amely egy helyi fájlból adatokat továbbít, és a Flume segítségével HDFS-be írja, hasonlóan a Unix „tail” parancsához)
- Rendszernaplók
- Apache log4j (ami lehetővé teszi Java alkalmazások, amelyek eseményeket írhatnak HDFS-fájlokba a Flume segítségével).
A jelenlegi kiadás a Flume 1.11.0, közzétéve 2022. október 25-én és elérhető a következő címen: Apache Flume letöltési oldalEz az útmutató az 1.4.0 verzióhoz készült, ezért az alábbi lépések közül többnél megjegyzés található, ahol a jelenlegi kiadások eltérően viselkednek.
Flume Architectúra
A Flume ügynök egy JVM Egy három komponensből álló folyamat – csatornaforrás, csatornacsatorna és csatornanyelő –, amelyeken keresztül az események terjednek, miután egy külső forrásból kezdeményezték őket. Az alábbi ábra bemutatja, hogyan kapcsolódnak egymáshoz.
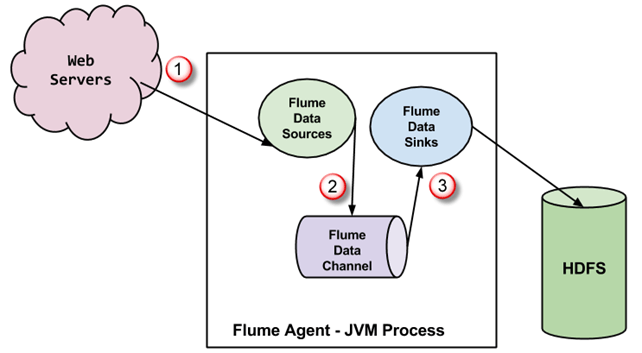
- A külső forrás (webszerver) által generált eseményeket a Flume forrás dolgozza fel. A külső forrás olyan formátumban küldi az eseményeket a Flume forrásnak, amelyet a célforrás felismer.
- A Flume forrás fogad egy eseményt, és egy vagy több csatornába tárolja. A csatorna tárolóként működik, amely addig tárolja az eseményt, amíg a Flume nyelő fel nem használja. Ez a csatorna helyi fájlrendszert használhat ezen események tárolására.
- A Flume nyelő eltávolítja az eseményt egy csatornából, és egy külső adattárba, például a HDFS-be tárolja. Több Flume ügynök is lehet, ebben az esetben a Flume nyelő továbbítja az eseményt a folyamatban következő ügynök Flume forrásához.
A Flume néhány fontos jellemzője
- A Flume rugalmas felépítésű, amely a folyamatos adatfolyamokon alapul. Hibatűrő és robusztus, több feladatátvételi és helyreállítási mechanizmussal. A Flume különböző megbízhatósági szinteket kínál, beleértve a következőket: "legjobb kézbesítés" és a "végponttól végpontig szállítás". Legjobb kézbesítés nem tolerálja a Flume csomópont meghibásodását, míg végponttól végpontig történő szállítás garantálja a szállítást több csomópont meghibásodása esetén is.
- A Flume adatokat továbbít források és nyelők között. Ez az adatgyűjtés lehet ütemezett vagy eseményvezérelt. A Flume saját lekérdezés-feldolgozó motorral rendelkezik, amely megkönnyíti az egyes új adatkötegek átalakítását, mielőtt azok a kívánt nyelőbe kerülnének.
- Lehetséges Flume süllyed beleértve a HDFS-t és HBaseA Flume eseményadatokat, például hálózati forgalmi adatokat, közösségi média webhelyek által generált adatokat és e-mail üzeneteket is képes továbbítani.
Flume, könyvtár és forráskód beállítása
Mielőtt belekezdenénk a tényleges folyamatba, győződjünk meg arról, hogy telepítve van a Hadoop; ha nem, akkor végezzük el a következő lépéseket: hogyan kell telepíteni a Hadoop-ot először. Változtasd meg a felhasználót 'hduser'-re (ez az azonosító, amit a Hadoop konfigurálásakor használtál; átválthatsz a saját Hadoop konfigurációd során használt felhasználói azonosítóra).

Step 1) Hozz létre egy új könyvtárat „FlumeTutorial” néven.
sudo mkdir FlumeTutorial
- Adjon olvasási, írási és végrehajtási jogosultságokat.
sudo chmod -R 777 FlumeTutorial
- Másolja a fájlokat MyTwitterSource.java és a MyTwitterSourceForFlume.java ebbe a könyvtárba.
Töltse le a bemeneti fájlokat innen
Ellenőrizd az összes fájl jogosultságait az alábbiak szerint, és ha hiányzik, adj nekik „olvasási” jogosultságot.

Step 2) Töltsd le az 'Apache Flume'-t innen https://flume.apache.org/download.html.
Ebben a Flume oktatóanyagban az Apache Flume 1.4.0-t használtuk.

Ezután kattintson át egy tükörre.

Step 3) Másold át a letöltött tarballt a választott könyvtárba, és használd az ex-t.traca tartalmat a következő paranccsal.
sudo tar -xvf apache-flume-1.4.0-bin.tar.gz

Ez létrehoz egy új könyvtárat apache-flume-1.4.0-bin néven, és az extracbemásolja a fájlokat. Ezt a könyvtárat úgy nevezik, hogy a cikk további részében.
Step 4) Flume könyvtár beállítása. Másold át a twitter4j-core-4.0.1.jar, flume-ng-configuration-1.4.0.jar, flume-ng-core-1.4.0.jar és flume-ng-sdk-1.4.0.jar fájlokat a következőre:
/lib/
Előfordulhat, hogy a másolt JAR fájlok bármelyike vagy mindegyike rendelkezik végrehajtási engedéllyel, ami problémát okozhat a kód fordítása során, ezért vonja vissza. Az én esetemben a twitter4j-core-4.0.1.jar fájlnak volt végrehajtási engedélye. Az alábbiak szerint vontam vissza.
sudo chmod -x twitter4j-core-4.0.1.jar

Ezután az alábbi parancs mindenkinek „olvasási” jogosultságot ad a twitter4j-core-4.0.1.jar fájlon.
sudo chmod +rrr /usr/local/apache-flume-1.4.0-bin/lib/twitter4j-core-4.0.1.jar
Kérlek, vedd figyelembe, hogy a twitter4j-core-4.0.1.jar fájlt innen töltöttem le: Maven adattár, és az összes Flume JAR fájl, azaz a flume-ng-*-1.4.0.jar fájl, innen: az org.apache.flume műtárgyai.
Töltsön be adatokat a Twitterről a Flume segítségével
Step 1) Lépj be abba a könyvtárba, amelyik a forráskódfájlokat tartalmazza.
Step 2) Állítsa be a CLASSPATH-ot úgy, hogy tartalmazza /lib/* és ~/FlumeTutorial/flume/mytwittersource/*.
export CLASSPATH="/usr/local/apache-flume-1.4.0-bin/lib/*:~/FlumeTutorial/flume/mytwittersource/*"

Step 3) Fordítsd le a forráskódot az alábbi parancs segítségével.
javac -d . MyTwitterSourceForFlume.java MyTwitterSource.java

Step 4) Hozz létre egy JAR fájlt. Először hozz létre egy Manifest.txt fájlt egy általad választott szövegszerkesztővel, és add hozzá az alábbi sort.
Main-Class: flume.mytwittersource.MyTwitterSourceForFlume
Itt a flume.mytwittersource.MyTwitterSourceForFlume a fő osztály neve. Kérjük, vegye figyelembe, hogy a sor végén meg kell nyomni az Enter billentyűt, ahogy az alább látható.

Most hozd létre a „MyTwitterSourceForFlume.jar” JAR fájlt az alábbiak szerint.
jar cfm MyTwitterSourceForFlume.jar Manifest.txt flume/mytwittersource/*.class

Step 5) Másolja ezt a JAR-t ide /lib/.
sudo cp MyTwitterSourceForFlume.jar <Flume Installation Directory>/lib/

Step 6) Menj a Flume konfigurációs könyvtárába, /conf.
Ha a flume.conf fájl nem létezik, másolja a flume-conf.properties.template fájlt, és nevezze át flume.conf névre.
sudo cp flume-conf.properties.template flume.conf

Ha a flume-env.sh nem létezik, másolja a flume-env.sh.template fájlt, és nevezze át flume-env.sh névre.
sudo cp flume-env.sh.template flume-env.sh

Twitter alkalmazás létrehozása
Először ezt olvasd el. A v1.1 streaming statuses/filter A twitter4j 4.0.1 által igényelt végpontot 2023. március 9-én visszavonták, és az azt felváltó API v2 szűrt adatfolyam most a következő címen érhető el: developer.x.com, egy fizetős szint mögött található. Tekintsd az alábbi képernyőket egyéni forrásmintaként, majd irányítsd ugyanazt az ügynököt egy fájlra, végrehajtásra vagy Kafka forrásra.
Step 1) Hozz létre egy Twitter alkalmazást a fejlesztői portálra való bejelentkezéssel.


Step 2) Lépjen a „Saját alkalmazások” menüpontra (ez az opció a jobb felső sarokban található „Tojás” gombra kattintva legördül).

Step 3) Hozz létre egy új alkalmazást az „Új alkalmazás létrehozása” gombra kattintva.
Step 4) Töltse ki az alkalmazás adatait az alkalmazás nevének, leírásának és weboldalának megadásával. Az egyes beviteli mezők alatt található megjegyzéseket is megtalálja.
Step 5) Görgess lejjebb az oldalon, fogadd el a feltételeket az „Igen, elfogadom” jelölőnégyzet bejelölésével, majd kattints a „Twitter-alkalmazás létrehozása” gombra.

Step 6) Az újonnan létrehozott alkalmazás ablakában lépjen az „API-kulcsok” fülre, görgessen lejjebb az oldalon, és kattintson a „Hozzáférés token létrehozása” gombra.


Step 7) Frissítsd az oldalt.
Step 8) Kattintson az „OAuth tesztelése” gombra. Ez megjeleníti az alkalmazás „OAuth” beállításait.

Step 9) Módosítsa a „flume.conf” fájlt ezekkel az OAuth beállításokkal. A „flume.conf” módosításának lépései alább olvashatók.

A 'flume.conf' frissítéséhez át kell másolnunk a felhasználói kulcsot, a felhasználói titkot, a hozzáférési tokent és a hozzáférési token titkát.
Megjegyzés: Ezek az értékek a felhasználóhoz tartoznak, ezért bizalmasak, ezért nem szabad megosztani őket.
Módosítsa a „flume.conf” fájlt
Step 1) Nyisd meg a 'flume.conf' fájlt írási módban, és állítsd be az alábbi paraméterek értékeit.
sudo gedit flume.conf
Másold le az alábbi tartalmat.
MyTwitAgent.sources = Twitter MyTwitAgent.channels = MemChannel MyTwitAgent.sinks = HDFS MyTwitAgent.sources.Twitter.type = flume.mytwittersource.MyTwitterSourceForFlume MyTwitAgent.sources.Twitter.channels = MemChannel MyTwitAgent.sources.Twitter.consumerKey = <Copy consumer key value from Twitter App> MyTwitAgent.sources.Twitter.consumerSecret = <Copy consumer secret value from Twitter App> MyTwitAgent.sources.Twitter.accessToken = <Copy access token value from Twitter App> MyTwitAgent.sources.Twitter.accessTokenSecret = <Copy access token secret value from Twitter App> MyTwitAgent.sources.Twitter.keywords = guru99 MyTwitAgent.sinks.HDFS.channel = MemChannel MyTwitAgent.sinks.HDFS.type = hdfs MyTwitAgent.sinks.HDFS.hdfs.path = hdfs://localhost:54310/user/hduser/flume/tweets/ MyTwitAgent.sinks.HDFS.hdfs.fileType = DataStream MyTwitAgent.sinks.HDFS.hdfs.writeFormat = Text MyTwitAgent.sinks.HDFS.hdfs.batchSize = 1000 MyTwitAgent.sinks.HDFS.hdfs.rollSize = 0 MyTwitAgent.sinks.HDFS.hdfs.rollCount = 10000 MyTwitAgent.channels.MemChannel.type = memory MyTwitAgent.channels.MemChannel.capacity = 10000 MyTwitAgent.channels.MemChannel.transactionCapacity = 1000

Step 2) Állítsa be a TwitterAgent.sinks.HDFS.hdfs.path fájlt az alábbiak szerint.
TwitterAgent.sinks.HDFS.hdfs.path = hdfs:// : / /flume/tweetek/

Megtalálni , és , lásd az 'fs.defaultFS' paraméter értékét a $HADOOP_HOME/etc/hadoop/core-site.xml fájlban, az alábbiak szerint.

Step 3) Ahhoz, hogy az adatokat a HDFS-be folyasd, amint megérkeznek, töröld az alábbi bejegyzést, ha létezik.
TwitterAgent.sinks.HDFS.hdfs.rollInterval = 600
Példa: Twitter-adatok streamelése a Flume segítségével
Step 1) Nyisd meg a 'flume-env.sh' fájlt írási módban, és állítsd be az alábbi paraméterek értékeit.
JAVA_HOME=<Installation directory of Java>
FLUME_CLASSPATH="<Flume Installation Directory>/lib/MyTwitterSourceForFlume.jar"

Step 2) Indítsd el a Hadoopot.
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Step 3) A Flume tarballban található két JAR fájl nem kompatibilis a Hadoop 2.2.0-val, ezért ebben az Apache Flume példában az alábbi lépéseket követjük, hogy a Flume kompatibilis legyen a Hadoop 2.2.0-val. Ez a JAR swap egy 1.4.0-korszakbeli javítás; a Flume 1.11.0 már tartalmazza a jelenlegi protobuf és Guava buildeket, így egy modern tarballnak általában nincs szüksége ezekre.
a. Helyezze át a protobuf-java-2.4.1.jar fájlt a következőből: ' /lib'. Először lépj be ebbe a könyvtárba.
CD /lib
sudo mv protobuf-java-2.4.1.jar ~/

b. Keresd meg a „guava” JAR fájlt az alábbiak szerint.
find . -name "guava*"

A guava-10.0.1.jar fájl áthelyezése innen: ' /lib'.
sudo mv guava-10.0.1.jar ~/

c. Töltse le a guava-17.0.jar fájlt innen: Maven adattár, lásd lent.

Most másold át ezt a letöltött JAR fájlt a következőbe: /lib'.
Step 4) Menj ide: ' /bin' parancsot, és indítsa el a Flume-ot az alábbiak szerint.
./flume-ng agent -n MyTwitAgent -c conf -f <Flume Installation Directory>/conf/flume.conf

A parancssori ablak, ahol a Flume tweeteket fogad, így néz ki.

A parancsablak üzenetéből láthatjuk, hogy a kimenet a /user/hduser/flume/tweets/ könyvtárba kerül. Most nyisd meg ezt a könyvtárat egy webböngészőben.
Step 5) Az adatbetöltés eredményének megtekintéséhez nyissa meg a http://localhost:50070/ címet egy böngészőben, keresse meg a fájlrendszert, majd lépjen be abba a könyvtárba, ahová az adatokat betöltötte, azaz
/flume/tweetek/
Az 50070-es port a NameNode webes felhasználói felülete a Hadoop 2-n; a Hadoop 3 ugyanezt az oldalt áthelyezte a 9870-es portra.

A Flume a lenyelés fele: Sqoop Táblázatokat importál kötegekben, a Flume streameli az eseményeket, majd Disznó or Kaptár formázd a fájlokat és oozie ütemezi a láncot. Lásd még nagy adatelemző eszközök, MapReduce csatlakozások és számlálók és a Talend.