Vodič za Scikit-Learn: Kako instalirati i Scikit-Learn primjeri
⚡ Pametni sažetak
Scikit-learn je program otvorenog koda Python biblioteka koja pokriva predobradu, klasifikaciju, regresiju, klasteriranje i odabir modela iza jednog konzistentnog sučelja za procjenu, što čini kompletan tijek rada strojnog učenja kratkim, čitljivim i reproducibilnim od sirovih podataka do bodovanih predviđanja.

Što je Scikit-learn?
Scikit-nauči je open source Python knjižnica za stroj za učenjePodržava dobro utvrđene algoritme kao što su KNN, pojačavanje gradijenta, slučajna šuma i SVM, a izgrađen je na numpy i SciPy. Scikit-learn se široko koristi u Kaggle natjecanjima, kao i u istaknutim tehnološkim tvrtkama. Obuhvaća predprocesiranje, smanjenje dimenzionalnosti, klasifikaciju, regresiju, klasteriranje i odabir modela.
Scikit-learn ima jednu od najboljih dokumentacija od svih biblioteka otvorenog koda. Čak pruža i interaktivni grafikon procjene, Odabir pravog procjenitelja, koji vas vodi od veličine vašeg skupa podataka do kratkog popisa algoritama koje vrijedi isprobati.
Donja slika ilustrira kako Scikit-learn funkcionira.
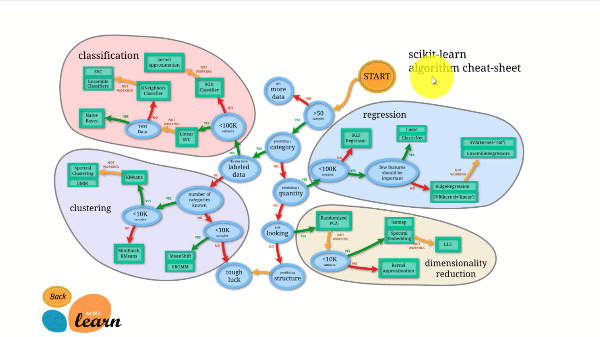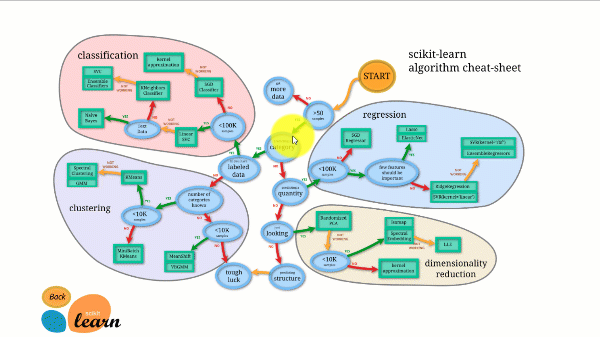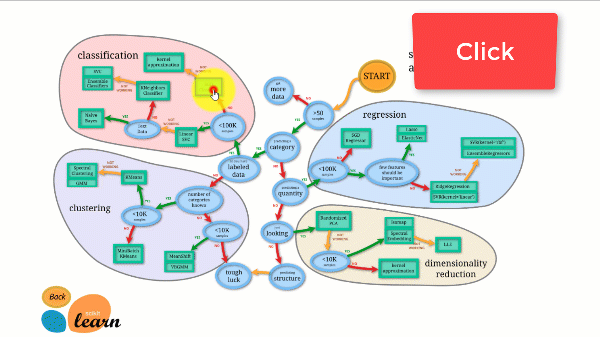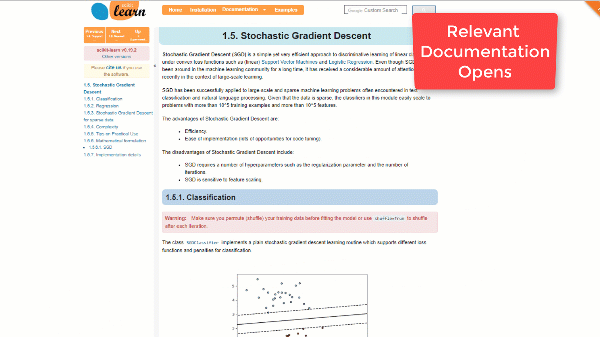
Scikit-learn nije težak za korištenje i daje izvrsne rezultate. Međutim, trenira na CPU-u: rad se paralelno izvodi na više jezgri s argumentom n_jobs, a ne na GPU-u. Pokretanje algoritma dubokog učenja s njim je moguće, ali rijetko optimalno, pogotovo ako već znate kako ga koristiti. TensorFlow.
Kako preuzeti i instalirati Scikit-learn
Sada u ovome Python Scikit-learn tutorial, naučit ćete kako preuzeti i instalirati Scikit-learn:
Opcija 1: AWS
Scikit-learn se može koristiti preko AWS-a. Docker slika s unaprijed instaliranim scikit-learn-om u potpunosti štedi vrijeme na postavljanju.
Za instalaciju razvojne verzije, pokrenite naredbu u nastavku Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Opcija 2: Mac ili Windows pomoću Anaconde
Za više informacija o instalaciji Anaconde, pogledajte Kako preuzeti i instalirati TensorFlow.
U vrijeme pisanja ovog vodiča, programeri scikita su izdali razvojnu verziju koja je riješila probleme prisutne u tadašnjoj trenutnoj verziji, tako da koraci u nastavku koriste tu razvojnu verziju. Na novom računalu danas trenutna stabilna verzija već sadrži svaki transformator korišten ovdje i pip instalacija -U scikit-learn dovoljno je.
Kako instalirati scikit-learn s Conda okruženjem
Ako ste instalirali scikit-learn s conda okruženjem, slijedite dolje navedene korake za ažuriranje na verziju 0.20.
Korak 1) Aktivirajte tensorflow okruženje
source activate hello-tf
Korak 2) Uklonite scikit-learn pomoću naredbe conda
conda remove scikit-learn
Korak 3) Instalirajte verziju za razvojne programere
Instalirajte scikit-learn razvojnu verziju zajedno s potrebnim bibliotekama.
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
NAPOMENA: Windows korisnici trebaju Microsoft Visual C++ 14. Možeš to dobiti ovdje.
Scikit-Learn primjer sa strojnim učenjem
Ovaj vodič za Scikit podijeljen je u dva dijela:
- Strojno učenje sa scikit-learnom
- Kako vjerovati svom modelu uz LIME
Prvi dio detaljno opisuje kako izgraditi cjevovod, stvoriti model i podesiti hiperparametre, dok drugi dio pokriva interpretaciju modela.
Korak 1) Uvezite podatke
Tijekom ovog Scikit learn tutoriala, koristit ćete skup podataka popisa odraslih.
Datoteka se u donjem kodu čita izravno iz UCI repozitorija strojnog učenja, tako da nije potrebno ručno preuzimanje. Ako vas zanima deskriptivna statistika, vrijedi pogledati alate Dive i Overview. Pogledajte Ovaj vodič kako biste saznali više o ronjenju i pregledu.
Skup podataka uvozite pomoću pandas-a. Imajte na umu da kontinuirane varijable trebate pretvoriti u format s pomičnim zarezom.
Ovaj skup podataka uključuje osam kategoričkih varijabli, navedenih u CATE_FEATURES:
- radna klasa
- obrazovanje
- bračni
- okupacija
- odnos
- utrka
- seks
- rodna_zemlja
Također uključuje šest kontinuiranih varijabli, navedenih u CONTI_FEATURES:
- starost
- fnlwgt
- obrazovanje_br
- kapitalni dobitak
- gubitak_kapitala
- sati_tjedan
Popisi se ovdje popunjavaju ručno kako biste imali jasniju ideju o tome koji su stupci u igri. Brži način za izradu popisa kategoričkih ili kontinuiranih stupaca je:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
Evo koda za uvoz podataka:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
Pozivanjem funkcije describe() na okviru vraća se sažetak statistike za šest kontinuiranih stupaca:
| starost | fnlwgt | obrazovanje_br | kapitalni dobitak | gubitak_kapitala | sati_tjedan | |
|---|---|---|---|---|---|---|
| računati | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| značiti | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| sati | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| minuta | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Možete provjeriti broj jedinstvenih vrijednosti značajke native_country. Samo jedno kućanstvo dolazi iz Holand-Netherlands. To kućanstvo ne donosi nikakve informacije i izbacit će grešku tijekom učenja.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Ovaj neinformativni redak možete isključiti iz skupa podataka:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Zatim pohranjujete položaj kontinuiranih značajki na popisu. Trebat će vam u sljedećem koraku za izgradnju cjevovoda.
Donji kod prolazi kroz sva imena stupaca u CONTI_FEATURES, čita svaku lokaciju (tj. broj stupca) i dodaje je na popis pod nazivom conti_features.
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
Sljedeći blok obavlja isti posao za kategoričke varijable.
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Sada pogledajte sam skup podataka. Svaka kategorička značajka je niz znakova, a modelu se ne može dodijeliti niz znakova, pa se skup podataka mora transformirati pomoću lažnih varijabli.
df_train.head(5)
Zapravo, potreban vam je jedan stupac za svaku grupu u svakoj značajki. Prvo pokrenite donji kôd kako biste izračunali ukupan broj potrebnih stupaca.
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
Cijeli skup podataka sadrži 101 grupu, kao što je prikazano gore. Samo značajka radne klase ima devet grupa. Nazive grupa možete navesti pomoću donjeg koda; unique() vraća različite vrijednosti svake kategoričke značajke.
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Skup podataka za učenje stoga će sadržavati 101 + 6 stupaca: grupe s jednom vrućom skupinom plus šest kontinuiranih značajki.
Scikit-learn može izvršiti konverziju u dva koraka:
- Pretvorite niz znakova u ID. State-gov postaje ID 1, Self-emp-not-inc postaje ID 2 i tako dalje. LabelEncoder to radi za vas.
- Transponirajte svaki ID u novi stupac. Skup podataka ima 101 grupni ID, tako da će biti 101 stupac koji obuhvaća svaku kategoričku skupinu značajki. Scikit-learn nudi OneHotEncoder za ovu operaciju.
Korak 2) Kreirajte set za treniranje/testiranje
Sada kada je skup podataka spreman, podijelite ga 80/20: 80 posto za skup za učenje i 20 posto za skup za testiranje.
Možete koristiti train_test_split. Prvi argument je okvir podataka značajki, a drugi je oznaka. Veličinu testnog skupa postavljate pomoću test_size.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Korak 3) Izgradite cjevovod
Cjevovod olakšava punjenje modela konzistentnim podacima. Ideja je progurati sirove podatke kroz jedan objekt koji izvršava svaku operaciju redom.
S ovim skupom podataka potrebno je standardizirati kontinuirane varijable i pretvoriti kategoričke. Bilo koja operacija može se nalaziti unutar cjevovoda: nedostajuće vrijednosti mogu se zamijeniti srednjom vrijednošću ili medijanom, a mogu se stvoriti i nove varijable.
Imate izbor: fiksno kodirati oba procesa ili izgraditi cjevovod. Fiksno kodiranje može procuriti testne podatke u prilagođenu statistiku i s vremenom stvoriti nedosljednosti, pa je cjevovod bolja opcija.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Cjevovod obavlja dvije operacije prije punjenja logističkog klasifikatora:
- Standardizirajte varijablu: StandardScaler()
- Pretvorite kategoričke značajke: OneHotEncoder(sparse=False)
Oba koraka izvršavate s make_column_transformer. Kada je ovaj vodič napisan, funkcija nije bila u objavljenoj verziji scikit-learn (0.19), zbog čega je korištena razvojna verzija; isporučena je u svakom stabilnom izdanju od verzije 0.20.
Naredba make_column_transformer je jednostavna: deklarirate koje stupce transformirati i koju transformaciju primijeniti. Za standardizaciju kontinuiranih značajki koje prosljeđujete:
- conti_features, StandardScaler() unutar make_column_transformer
- conti_features: popis kontinuiranih stupaca
- StandardScaler: standardizira te stupce
Objekt OneHotEncoder unutar make_column_transformer automatski kodira oznake.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Napomena o verziji: Dva argumenta u gornjem bloku su se pomaknula dalje. Trenutni izlazi očekuju prvo transformator, a zatim stupce, i rijedak je preimenovan rijedak_izlaz u scikit-learn 1.2 i uklonjeno u 1.4, pa noviji kod glasi OneHotEncoder(sparse_output=False).
Možete testirati radi li cjevovod pomoću fit_transform. Izlaz bi trebao imati oblik 26048, 107.
preprocess.fit_transform(X_train).shape
(26048, 107)
Transformator podataka je spreman. Izrađujete cjevovod pomoću make_pipeline, a nakon što su podaci transformirani, unosite podatke u logističku regresiju.
model = make_pipeline(
preprocess,
LogisticRegression())
Treniranje modela pomoću scikit-learn je tada jednostavno: pozovite fit na cjevovodu. Točnost možete ispisati metodom score.
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Konačno, klase možete predvidjeti pomoću funkcije predict_proba, koja vraća vjerojatnost svake klase. Imajte na umu da se zbroj dvije vjerojatnosti daje jedan.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Korak 4) Korištenje našeg cjevovoda u pretraživanju mreže
Podešavanje hiperparametara, vrijednosti koje određuju strukturu modela, može biti zamorno i iscrpljujuće.
Jedan od načina za procjenu modela bio bi promjena veličine skupa za učenje i mjerenje performansi, ponavljajući vježbu deset puta kako bi se vidjela raspršenost rezultata. To je puno ručnog rada.
Umjesto toga, scikit-learn pruža funkcije koje provode podešavanje parametara i unakrsnu validaciju umjesto vas.
Križna validacija
Unakrsna validacija znači da se tijekom treniranja skup za treniranje dijeli n puta na nabore, a model se evaluira n puta. Ako je cv postavljen na 10, model se trenira i evaluira deset puta. U svakom krugu klasifikator trenira na devet nasumično odabranih nabora, a deseti nabor se zadržava za evaluaciju.
Pretraživanje mreže
Svaki klasifikator ima hiperparametre za podešavanje. Možete isprobavati vrijednosti jednu po jednu ili postaviti mrežu parametara. Dokumentacija scikit-learn navodi sve parametre koje logistički klasifikator prihvaća. Kako bi se učenje održalo brzim, ovaj primjer podešava samo parametar C, koji kontrolira regularizaciju. Mora biti pozitivan, a mala vrijednost daje veću težinu regularizatoru.
Koristite objekt GridSearchCV, koji uzima rječnik hiperparametara za podešavanje. Navedite svaki hiperparametar nakon kojeg slijede vrijednosti koje želite isprobati. Za podešavanje C-a pišete:
- 'logistikregresija__C': [0.001, 0.01, 0.1, 1.0] — nazivu parametra prethodi naziv klasifikatora malim slovima i dvije podvlake.
Model će isprobati četiri različite vrijednosti: 0.001, 0.01, 0.1 i 1. Treniran je s 10 nabora, odnosno cv=10.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
Sada možete trenirati model koristeći GridSearchCV s parametrima grid i cv.
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
Izlaz:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
Napomena o verziji: o identifikator identiteta Argument vidljiv u ovom izlazu je zastario u scikit-learn verziji 0.22 i uklonjen u verziji 0.24, pa bi ga jednostavno trebalo izbaciti iz poziva GridSearchCV u trenutnim izdanjima.
Za pristup najboljim parametrima koristite best_params_.
grid_clf.best_params_
Izlaz:
{'logisticregression__C': 1.0}
Nakon treniranja modela s četiri različite vrijednosti regularizacije, optimalni parametar daje:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
najbolja logistička regresija iz pretraživanja mreže: 0.850891
Za pristup predviđenim vjerojatnostima:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
XGBoost model sa scikit-learn
Sada isprobajte jedan od najjačih klasifikatora na tržištu. XGBoost je poboljšanje slučajne šume s pojačanim gradijentom. Njegova teorijska pozadina izlazi iz okvira ovog... Python Scikit tutorial, ali imajte na umu da je XGBoost pobijedio na mnogim Kaggle natjecanjima. Na skupu podataka prosječne veličine može raditi jednako dobro kao algoritam dubokog učenja ili čak i bolje.
Klasifikator je izazovan za treniranje jer otkriva veliki broj parametara. Naravno, možete koristiti GridSearchCV da ih odaberete umjesto sebe.
Bolja opcija ovdje je RandomizedSearchCV. GridSearchCV postaje spor kada je mreža velika, jer prostor pretraživanja raste sa svakim dodanim parametrom. RandomizedSearchCV umjesto toga nasumično uzorkuje vrijednosti svakog hiperparametra u svakoj iteraciji, tako da 1,000 iteracija procjenjuje 1,000 kombinacija. Inače radi slično kao GridSearchCV.
Morate uvesti xgboost. Ako biblioteka nije instalirana, pokrenite pip3 install xgboost ili je instalirajte iznutra Jupyter bilježnica s:
use import sys
!{sys.executable} -m pip install xgboost
Zatim uvezite klasifikator i dva pomoćnika za pretraživanje:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Sljedeći korak u ovom Scikitu Python U tutorijalu je odrediti parametre za podešavanje. Službena XGBoost dokumentacija ih sve navodi. Zbog ovoga Python U Sklearn tutorialu birate samo dva hiperparametra s dvije vrijednosti svaki, jer XGBoostu treba puno vremena za treniranje i svaka dodatna točka mreže povećava vrijeme čekanja.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Zatim konstruirate novi cjevovod s XGBoost klasifikatorom i 600 estimatora. n_estimators je sam po sebi podesiv, a visoka vrijednost može dovesti do prekomjernog prilagođavanja. Možete isprobati i druge vrijednosti, ali imajte na umu da to može potrajati satima. Svaki ostali parametar zadržava svoju zadanu vrijednost.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Unakrsnu validaciju možete poboljšati pomoću Stratified K-Folds unakrsnog validatora. Ovdje se koriste samo tri nabora kako bi se ubrzao izračun, uz određenu štetu u kvaliteti; povećajte to na 5 ili 10 na vlastitom računalu za bolje rezultate. Model se trenira kroz četiri iteracije.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Nasumično pretraživanje je spremno, tako da možete trenirati model.
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Kao što vidite, XGBoost postiže bolje rezultate od ranije logističke regresije.
print("Best parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Stvorite DNN s MLPClassifierom u scikit-learn
Konačno, neuronsku mrežu možete trenirati pomoću samog scikit-learn-a. Metoda je ista kao i za bilo koji drugi klasifikator, a estimator je MLPClassifier.
from sklearn.neural_network import MLPClassifier
Donja mreža definirana je sa:
- Adam rješavač
- ReLU aktivacijska funkcija
- Alfa = 0.0001
- Veličina serije od 150
- Dva skrivena sloja sa 200 odnosno 100 neurona
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Možete promijeniti broj slojeva kako biste poboljšali model.
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN regresijski rezultat: 0.821253
LIME: Vjerujte svom modelu
Sada kada imate dobar model, potreban vam je način da mu vjerujete. Algoritmi strojnog učenja, posebno slučajne šume i neuronske mreže, poznati su kao modeli crne kutije: oni rade, ali nitko ne vidi zašto.
Tri istraživača su izgradila alat koji pokazuje kako računalo dolazi do predviđanja. Njihov rad je "Zašto bih ti trebao vjerovati?", a algoritam koji su objavili naziva se Lokalno interpretabilna modelno-agnostička objašnjenja (LIME).
Uzmimo primjer. Ponekad ne znate može li se vjerovati predviđanju strojnog učenja. Liječnik ne može prihvatiti dijagnozu samo zato što ju je dalo računalo, a vi morate znati je li model pouzdan prije nego što ga stavite u proizvodnju.
Zamislite da možete vidjeti zašto je bilo koji klasifikator napravio predviđanje, čak i za modele složene poput neuronskih mreža, slučajnih šuma ili SVM-ova s proizvoljnom jezgrom. Mnogo je lakše vjerovati predviđanju kada su razlozi za njega vidljivi, a jednako je lakše odlučiti kada se modelu ne treba vjerovati. LIME vam govori koje su značajke utjecale na odluku klasifikatora.
Priprema podataka
Postoji nekoliko stvari koje trebate promijeniti da biste mogli koristiti LIME PythonPrvo, instalirajte Lime u terminal pomoću naredbe pip install lime.
Lime koristi objekt LimeTabularExplainer za lokalnu aproksimaciju modela. Ovaj objekt zahtijeva:
- skup podataka u numpy format
- Naziv značajki: naziv_značajki
- Naziv klasa: class_names
- Indeks stupca kategoričkih obilježja: kategorička obilježja
- Naziv grupe za svaku kategoričku značajku: categorical_names
Izradite NumPy skup vlakova
Možete vrlo lako kopirati i pretvoriti df_train iz pande u NumPy.
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
Nabavite naziv klase
Oznaka je dostupna putem unique(). Trebali biste vidjeti:
- '<=50K'
- '>50K'
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
Indeksiranje stupaca kategoričkih značajki
Upotrijebite metodu koju ste ranije naučili kako biste dobili naziv svake grupe. Kodirajte oznaku pomoću LabelEncodera i ponovite operaciju na svakoj kategoričkoj značajki.
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Sada kada je skup podataka spreman, možete izraditi različite skupove podataka prikazane u Scikit learn primjerima u nastavku. Podaci se ovdje transformiraju izvan cjevovoda kako bi se izbjegle pogreške s LIME-om: skup za učenje proslijeđen LimeTabularExplaineru mora biti NumPy niz bez nizova, a gornja metoda je već generirala jedan.
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
Možete napraviti cjevovod s optimalnim parametrima koje je pronašao XGBoost.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
Dobivate upozorenje. Objašnjava se da ne morate stvoriti label encoder prije cjevovoda. Ako ne koristite LIME, metoda iz prvog dijela ovog tutoriala o strojnom učenju sa Scikit-learn je u redu. Inače, zadržite ovaj pristup: prvo stvorite kodirani skup podataka, a zatim primijenite one-hot encoder unutar cjevovoda.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Prije nego što LIME pokrenete, stvorite NumPy niz koji sadrži značajke pogrešno klasificiranih redaka. Taj popis možete kasnije koristiti kako biste dobili ideju o tome što je zavelo klasifikator.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
Zatim kreirate lambda funkciju koja dohvaća predviđanje iz modela za nove podatke. Uskoro će vam trebati.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Pandas podatkovni okvir pretvarate u NumPy niz.
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
Sada odaberite slučajno kućanstvo iz testnog skupa i pogledajte i predviđanje i kako je računalo došlo do njega.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Objašnjavač možete koristiti s explain_instance kako biste provjerili obrazloženje modela. Grafikon koji prikazuje prikazan je u nastavku.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klasifikator je ispravno predvidio ovo kućanstvo: prihod je doista iznad 50 tisuća.
Prvo što treba napomenuti jest da klasifikator nije baš siguran u sebe. Predviđa prihod veći od 50 tisuća s vjerojatnošću od 64%, a da je 64% uvjetovano kapitalnim dobitkom i bračnim statusom. Plava boja negativno doprinosi pozitivnoj klasi, a narančasta linija pozitivno.
Klasifikator oklijeva jer je kapitalni dobitak ovog kućanstva nula, dok je kapitalni dobitak obično dobar prediktor bogatstva. Kućanstvo također radi manje od 40 sati tjedno. Dob, zanimanje i spol pozitivno doprinose.
Da je bračni status bio samac, klasifikator bi predvidio prihod ispod 50 tisuća (0.64 – 0.18 = 0.46).
Sada pokušajte s drugim kućanstvom, onim koje je pogrešno klasificirano. Tablica s objašnjenjem slijedi kod.
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klasifikator je predvidio prihod ispod 50 tisuća, što je pogrešno. Ovo kućanstvo je neobično: nema ni kapitalni dobitak ni kapitalni gubitak, osoba je razvedena, ima blizu 60 godina i obrazovana je, tj. broj_obrazovanja > 12. Slijedeći opći obrazac, klasifikator je smjestio kućanstvo ispod 50 tisuća.
Igrajte se s LIME-om i primijetit ćete mnoštvo očitih grešaka klasifikatora. GitHub repozitorij autora biblioteke sadrži dodatnu dokumentaciju za klasifikaciju slika i teksta.
Scikit-learn referenca naredbi
U nastavku je popis korisnih naredbi koje se primjenjuju na scikit-learn verziju 0.20 i novije.
| Zadatak | Funkcija ili klasa |
|---|---|
| Izradi skup podataka za učenje/testiranje | train_test_split |
| Izgradite cjevovod | |
| Odaberite stupce i primijenite transformaciju | napraviti_stupac_transformator |
| Vrsta transformacije | |
| Standardiziraj | StandardScaler |
| Min-max skaliranje | MinMaxScaler |
| Normaliziraj | Normalizator |
| Imputirajte nedostajuće vrijednosti | Jednostavni imputer |
| Pretvori kategorički | OneHotEncoder |
| Prilagodite i transformirajte podatke | fit_transformacija |
| Napravite cjevovod | napraviti_cjevovod |
| Osnovni model | |
| Logistička regresija | Logistička regresija |
| XGBoost | XGBClassifier |
| Neuronska mreža | MLPC klasifikator |
| Pretraživanje mreže | GridSearchCV |
| Nasumično pretraživanje | RandomizedSearchCV |