Modèle Seq2seq (séquence à séquence) avec PyTorch
⚡ Résumé intelligent
Seq2Seq est une architecture encodeur-décodeur qui transforme une séquence d'entrée en une séquence de sortie à l'aide de deux réseaux neuronaux récurrents, permettant la traduction automatique et d'autres tâches de traitement du langage naturel où les longueurs d'entrée et de sortie diffèrent.

Qu'est-ce que la PNL?
Le traitement automatique du langage naturel (TALN) est l'une des branches les plus populaires de l'intelligence artificielle. Il permet aux ordinateurs de comprendre, de manipuler et de répondre à un humain dans son langage naturel. Le TALN est le moteur de l'intelligence artificielle. Google Translate cela nous aide à comprendre d’autres langues.
Qu’est-ce que Seq2Seq ?
Séq2Séq est une méthode de traduction automatique et de traitement du langage basée sur un codeur-décodeur qui mappe une entrée de séquence à une sortie de séquence avec une balise et une valeur d'attention. L'idée est d'utiliser 2 RNN qui fonctionneront ensemble avec un jeton spécial et tenteront de prédire la séquence d'état suivante à partir de la séquence précédente.
Comment prédire la séquence de la séquence précédente
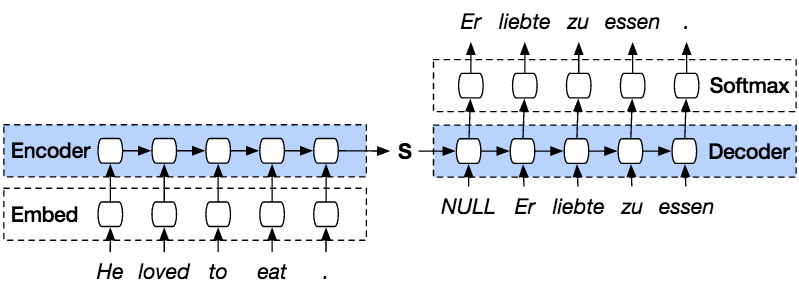
Voici les étapes pour prédire une séquence à partir de la séquence précédente avec PyTorch.
Étape 1) Chargement de nos données
Pour notre ensemble de données, vous utiliserez un ensemble de données de Paires de phrases bilingues délimitées par des tabulations. Ici, j'utiliserai l'ensemble de données anglais vers indonésien. Vous pouvez choisir ce que vous voulez, mais n'oubliez pas de modifier le nom du fichier et le répertoire dans le code.
from __future__ import unicode_literals, print_function, division import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import numpy as np import pandas as pd import os import re import random device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Étape 2) Préparation des données
Vous ne pouvez pas utiliser directement l'ensemble de données. Vous devez découper les phrases en mots et les convertir en vecteurs one-hot. Chaque mot sera indexé de manière unique dans la classe Lang pour créer un dictionnaire. La classe Lang stockera chaque phrase et la découpera mot par mot grâce à la méthode addSentence. Un dictionnaire sera ensuite créé en indexant chaque mot inconnu pour les modèles de type séquence à séquence.
SOS_token = 0 EOS_token = 1 MAX_LENGTH = 20 #initialize Lang Class class Lang: def __init__(self): #initialize containers to hold the words and corresponding index self.word2index = {} self.word2count = {} self.index2word = {0: "SOS", 1: "EOS"} self.n_words = 2 # Count SOS and EOS #split a sentence into words and add it to the container def addSentence(self, sentence): for word in sentence.split(' '): self.addWord(word) #If the word is not in the container, the word will be added to it, else, update the word counter def addWord(self, word): if word not in self.word2index: self.word2index[word] = self.n_words self.word2count[word] = 1 self.index2word[self.n_words] = word self.n_words += 1 else: self.word2count[word] += 1
La classe Lang nous permettra de créer un dictionnaire. Pour chaque langue, chaque phrase sera décomposée en mots, puis ajoutée au conteneur. Chaque conteneur stockera les mots à l'index approprié, comptera les occurrences de chaque mot et ajoutera son index afin de pouvoir rechercher un mot à partir de son index.
Parce que nos données sont séparées par TAB, vous devez utiliser pandas Pandas sera notre outil de chargement de données. Il lira nos données sous forme de dataFrame et les séparera en phrases source et cible. Pour chaque phrase, il faudra la normaliser en minuscules, supprimer les caractères non alphanumériques, la convertir en ASCII (à partir d'Unicode) et la découper en mots.
#Normalize every sentence def normalize_sentence(df, lang): sentence = df[lang].str.lower() sentence = sentence.str.replace('[^A-Za-z\s]+', '') sentence = sentence.str.normalize('NFD') sentence = sentence.str.encode('ascii', errors='ignore').str.decode('utf-8') return sentence def read_sentence(df, lang1, lang2): sentence1 = normalize_sentence(df, lang1) sentence2 = normalize_sentence(df, lang2) return sentence1, sentence2 def read_file(loc, lang1, lang2): df = pd.read_csv(loc, delimiter='\t', header=None, names=[lang1, lang2]) return df def process_data(lang1,lang2): df = read_file('text/%s-%s.txt' % (lang1, lang2), lang1, lang2) print("Read %s sentence pairs" % len(df)) sentence1, sentence2 = read_sentence(df, lang1, lang2) source = Lang() target = Lang() pairs = [] for i in range(len(df)): if len(sentence1[i].split(' ')) < MAX_LENGTH and len(sentence2[i].split(' ')) < MAX_LENGTH: full = [sentence1[i], sentence2[i]] source.addSentence(sentence1[i]) target.addSentence(sentence2[i]) pairs.append(full) return source, target, pairs
Une autre fonction utile que vous utiliserez est la conversion des paires en tenseurs. C'est essentiel car notre réseau ne lit que des données de type tenseur. Cette conversion est également importante car elle permet d'ajouter un jeton à la fin de chaque phrase pour indiquer au réseau que l'entrée est terminée. Pour chaque mot de la phrase, le réseau récupère son index dans le dictionnaire et ajoute un jeton à la fin de la phrase.
def indexesFromSentence(lang, sentence): return [lang.word2index[word] for word in sentence.split(' ')] def tensorFromSentence(lang, sentence): indexes = indexesFromSentence(lang, sentence) indexes.append(EOS_token) return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1) def tensorsFromPair(input_lang, output_lang, pair): input_tensor = tensorFromSentence(input_lang, pair[0]) target_tensor = tensorFromSentence(output_lang, pair[1]) return (input_tensor, target_tensor)
Modèle Seq2Seq

PyTorLe modèle ch Seq2seq est un type de modèle qui utilise un PyTorLe modèle utilise un encodeur-décodeur. L'encodeur convertit chaque mot de la phrase en un index de vocabulaire (mots connus). Le décodeur, quant à lui, prédit la sortie correspondante en décodant l'entrée séquentiellement et en réutilisant la dernière entrée comme suivante, si possible. Cette méthode permet également de prédire l'entrée suivante pour former une phrase. Chaque phrase se voit attribuer un jeton marquant la fin de la séquence. À la fin de la prédiction, un autre jeton marque la fin de la sortie. Ainsi, l'encodeur transmet un état au décodeur pour la prédiction de la sortie.

L'encodeur encode notre phrase d'entrée mot par mot, de manière séquentielle, et un jeton marque la fin de chaque phrase. L'encodeur est composé d'une couche d'intégration et d'une couche GRU. La couche d'intégration est une table de correspondance qui stocke l'intégration de notre entrée dans un dictionnaire de mots de taille fixe. Ce dictionnaire est ensuite transmis à la couche GRU. La couche GRU est une unité récurrente à porte (GRU) composée de plusieurs couches. RNN qui calculera l'entrée séquencée. Cette couche calculera l'état caché par rapport à la précédente et mettra à jour les portes de réinitialisation, de mise à jour et de nouvelles.

Le décodeur décode le signal d'entrée à partir du signal de sortie de l'encodeur. Il tente de prédire la sortie suivante et, si possible, de l'utiliser comme entrée suivante. Le décodeur est composé d'une couche d'intégration, d'une couche GRU et d'une couche linéaire. La couche d'intégration crée une table de correspondance pour la sortie et la transmet à la couche GRU afin de calculer l'état de sortie prédit. Ensuite, la couche linéaire calcule la fonction d'activation pour déterminer la valeur réelle de la sortie prédite.
class Encoder(nn.Module): def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers): super(Encoder, self).__init__() #set the encoder input dimesion , embbed dimesion, hidden dimesion, and number of layers self.input_dim = input_dim self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.num_layers = num_layers #initialize the embedding layer with input and embbed dimention self.embedding = nn.Embedding(input_dim, self.embbed_dim) #intialize the GRU to take the input dimetion of embbed, and output dimention of hidden and #set the number of gru layers self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) def forward(self, src): embedded = self.embedding(src).view(1,1,-1) outputs, hidden = self.gru(embedded) return outputs, hidden class Decoder(nn.Module): def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers): super(Decoder, self).__init__() #set the encoder output dimension, embed dimension, hidden dimension, and number of layers self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.output_dim = output_dim self.num_layers = num_layers # initialize every layer with the appropriate dimension. For the decoder layer, it will consist of an embedding, GRU, a Linear layer and a Log softmax activation function. self.embedding = nn.Embedding(output_dim, self.embbed_dim) self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) self.out = nn.Linear(self.hidden_dim, output_dim) self.softmax = nn.LogSoftmax(dim=1) def forward(self, input, hidden): # reshape the input to (1, batch_size) input = input.view(1, -1) embedded = F.relu(self.embedding(input)) output, hidden = self.gru(embedded, hidden) prediction = self.softmax(self.out(output[0])) return prediction, hidden class Seq2Seq(nn.Module): def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH): super().__init__() #initialize the encoder and decoder self.encoder = encoder self.decoder = decoder self.device = device def forward(self, source, target, teacher_forcing_ratio=0.5): input_length = source.size(0) #get the input length (number of words in sentence) batch_size = target.shape[1] target_length = target.shape[0] vocab_size = self.decoder.output_dim #initialize a variable to hold the predicted outputs outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device) #encode every word in a sentence for i in range(input_length): encoder_output, encoder_hidden = self.encoder(source[i]) #use the encoder's hidden layer as the decoder hidden decoder_hidden = encoder_hidden.to(device) #add a token before the first predicted word decoder_input = torch.tensor([SOS_token], device=device) # SOS #topk is used to get the top K value over a list #predict the output word from the current target word. If we enable the teaching force, then the next decoder input is the next word, else, use the decoder output highest value. for t in range(target_length): decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden) outputs[t] = decoder_output teacher_force = random.random() < teacher_forcing_ratio topv, topi = decoder_output.topk(1) input = (target[t] if teacher_force else topi) if(teacher_force == False and input.item() == EOS_token): break return outputs
Étape 3) Formation du modèle
Le processus d'entraînement des modèles Seq2seq commence par la conversion de chaque paire de phrases en tenseurs à partir de leur index de langue. Notre modèle séquence à séquence utilise la descente de gradient stochastique (SGD) comme optimiseur et la fonction NLLLoss pour calculer les pertes. L'entraînement débute par la soumission d'une paire de phrases au modèle afin qu'il prédise la sortie correcte. À chaque étape, la sortie du modèle est recalculée avec les mots corrects pour déterminer les pertes et mettre à jour les paramètres. Ainsi, comme vous utiliserez 75 000 itérations, notre modèle séquence à séquence générera 75 000 paires aléatoires à partir de notre ensemble de données.
teacher_forcing_ratio = 0.5 def clacModel(model, input_tensor, target_tensor, model_optimizer, criterion): model_optimizer.zero_grad() input_length = input_tensor.size(0) loss = 0 epoch_loss = 0 # print(input_tensor.shape) output = model(input_tensor, target_tensor) num_iter = output.size(0) print(num_iter) #calculate the loss from a predicted sentence with the expected result for ot in range(num_iter): loss += criterion(output[ot], target_tensor[ot]) loss.backward() model_optimizer.step() epoch_loss = loss.item() / num_iter return epoch_loss def trainModel(model, source, target, pairs, num_iteration=20000): model.train() optimizer = optim.SGD(model.parameters(), lr=0.01) criterion = nn.NLLLoss() total_loss_iterations = 0 training_pairs = [tensorsFromPair(source, target, random.choice(pairs)) for i in range(num_iteration)] for iter in range(1, num_iteration+1): training_pair = training_pairs[iter - 1] input_tensor = training_pair[0] target_tensor = training_pair[1] loss = clacModel(model, input_tensor, target_tensor, optimizer, criterion) total_loss_iterations += loss if iter % 5000 == 0: avarage_loss= total_loss_iterations / 5000 total_loss_iterations = 0 print('%d %.4f' % (iter, avarage_loss)) torch.save(model.state_dict(), 'mytraining.pt') return model
Étape 4) Testez le modèle
Le processus d'évaluation de Seq2seq PyTorL'objectif est de vérifier la sortie du modèle. Chaque paire de modèles séquence à séquence est fournie au modèle pour générer les mots prédits. Ensuite, la valeur la plus élevée de chaque sortie est identifiée afin de trouver l'index correspondant. Enfin, la prédiction du modèle est comparée à la phrase réelle.
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH): with torch.no_grad(): input_tensor = tensorFromSentence(input_lang, sentences[0]) output_tensor = tensorFromSentence(output_lang, sentences[1]) decoded_words = [] output = model(input_tensor, output_tensor) # print(output_tensor) for ot in range(output.size(0)): topv, topi = output[ot].topk(1) # print(topi) if topi[0].item() == EOS_token: decoded_words.append('' ) break else: decoded_words.append(output_lang.index2word[topi[0].item()]) return decoded_words def evaluateRandomly(model, source, target, pairs, n=10): for i in range(n): pair = random.choice(pairs) print('source {}'.format(pair[0])) print('target {}'.format(pair[1])) output_words = evaluate(model, source, target, pair) output_sentence = ' '.join(output_words) print('predicted {}'.format(output_sentence))
Commençons maintenant notre entraînement avec Seq to Seq, avec un nombre d'itérations de 75 000 et un nombre de couches RNN de 1 avec une taille cachée de 512.
lang1 = 'eng' lang2 = 'ind' source, target, pairs = process_data(lang1, lang2) randomize = random.choice(pairs) print('random sentence {}'.format(randomize)) #print number of words input_size = source.n_words output_size = target.n_words print('Input : {} Output : {}'.format(input_size, output_size)) embed_size = 256 hidden_size = 512 num_layers = 1 num_iteration = 100000 #create encoder-decoder model encoder = Encoder(input_size, hidden_size, embed_size, num_layers) decoder = Decoder(output_size, hidden_size, embed_size, num_layers) model = Seq2Seq(encoder, decoder, device).to(device) #print model print(encoder) print(decoder) model = trainModel(model, source, target, pairs, num_iteration) evaluateRandomly(model, source, target, pairs)
Comme vous pouvez le voir, notre phrase prédite ne correspond pas très bien, donc pour obtenir une plus grande précision, vous devez vous entraîner avec beaucoup plus de données et essayer d'ajouter plus d'itérations et de nombres de couches en utilisant Sequence pour séquencer l'apprentissage.
random sentence ['tom is finishing his work', 'tom sedang menyelesaikan pekerjaannya'] Input : 3551 Output : 4253 Encoder( (embedding): Embedding(3551, 256) (gru): GRU(256, 512) ) Decoder( (embedding): Embedding(4253, 256) (gru): GRU(256, 512) (out): Linear(in_features=512, out_features=4253, bias=True) (softmax): LogSoftmax() ) 5000 4.0906 10000 3.9129 15000 3.8171 20000 3.8369 25000 3.8199 30000 3.7957 75000 3.7044