SAP HANA Architietokanta: Tietokannan yleiskatsaus
⚡ Älykäs yhteenveto
SAP HANA ArchiRakenne, maisema ja koko muodostavat SUSE Linuxille rakennetun muistissa olevan data-alustan perustan. C++Tässä artikkelissa selitetään indeksipalvelin, tallennusmoottorit, rivi- ja saraketallennustilat, delta-yhdistämisen ja laitteiston kokomääritysmenetelmät.

Mikä on SAP HANA-tietokanta?
SAP HANA on keskusmuistikeskeinen tiedonhallinta-alusta. Tietokanta toimii SUSE Linux Enterprise Server (SLES) -alustalla ja Red Hat Enterprise Linux (RHEL) ja se on kirjoitettu C++Se voi skaalautua useiden koneiden kesken erittäin suuria työkuormia varten.
Tärkeimmät edut SAP HANA:
- Erittäin nopea kyselyiden suorituskyky, koska kaikki tiedot ladataan muistiin, mikä poistaa hitaan levyn I/O:n kriittiseltä polulta.
- Yhdistetty OLAP (Online Analytical Processing) ja OLTP (Online Transaction Processing) samassa tietokannassa, mikä yksinkertaistaa dataympäristöä.
SAP HANA-tietokanta koostuu joukosta muistissa olevia prosessointimoottoreita. Laskentamoottori on päämoottori, joka on vuorovaikutuksessa muiden moottoreiden, kuten relaatiomoottorin (rivi- ja sarakevarasto), OLAP-moottorin, tekstimoottorin ja graafimoottorin, kanssa. Relaatiotaulukko sijaitsee joko rivi- tai sarakevarastossa, ja lisämoottorit käsittelevät teksti- ja graafidataa, kun muistia on käytettävissä.
SAP HANA Archirakenne
Sarakemuistin tiedot pakataan käyttämällä tekniikoita, kuten sanakirjakoodausta, run-length-koodausta, harvaa koodausta, klusterikoodausta ja epäsuoraa koodausta. Kun päämuistin raja saavutetaan, käyttämättömät tietokantaobjektit (taulukot, näkymät jne.) puretaan levylle automaattisesti ja ladataan uudelleen, kun niitä pyydetään uudelleen.
Ylläpitäjät voivat myös ladata tai poistaa yksittäisen taulukon manuaalisesti napsauttamalla taulukkoa hiiren kakkospainikkeella SAP HANA Studio ja valitsemalla Purkaa or Ladata.
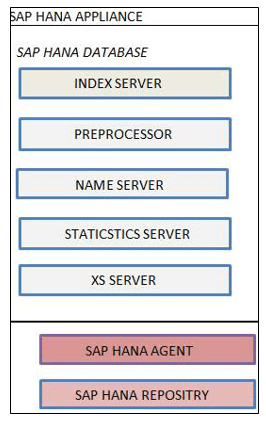
SAP HANA-palvelin koostuu seuraavista osista:
- Hakemistopalvelin
- Esikäsittelypalvelin
- name Server
- Tilastopalvelin
- XS moottori
1. SAP HANA-hakemistopalvelin
Indeksipalvelin on tärkein SAP HANA-tietokantakomponentti:
- Se on sydän SAP HANA-tietokantamoottori.
- Se sisältää varsinaiset tietovarastot ja moottorit, jotka käsittelevät tietoja.
- Se suorittaa saapuvia SQL- ja MDX-lausekkeita.
Indeksipalvelimen arkkitehtuuri on esitetty alla.

SAP HANA-indeksipalvelimen yleiskatsaus
- Istunto- ja tapahtumapäällikkö: Istunto-komponentti hallitsee tietokannan yhteyksiä ja istuntoja. Transaktionhallinta koordinoi ja ohjaa kaikkia tapahtumia.
- SQL- ja MDX-prosessori: SQL-suoritin lähettää kyselyt asianmukaiselle hakumoottorille (SQL / SQL Script / R / Calc Engine). MDX-suoritin käsittelee moniulotteisia kyselyitä (esimerkiksi analyyttistä näkymää vastaan tehtyjä kyselyitä).
- SQL / SQL Script / R / Calc Engine: Suorittaa SQL:ää, SQL-skriptejä, R:ää ja laskentamalleja dataa vasten.
- Repository: Säilyttää versioinnin SAP HANA-metatieto-objektit, kuten attribuuttinäkymät, analyyttiset näkymät ja tallennetut proseduurit.
- Pysyvyyskerros: Tarjoaa sisäänrakennetun palautusominaisuuden kirjoittamalla tallennuspisteitä ja lokeja levyllä olevalle data-asemalle.
2. Esiprosessoripalvelin
Tekstianalyysi käyttää esiprosessoripalvelinta. Se esim.tracja valmistelee tietoja tekstisisällöstä, kun hakutoimintoa kutsutaan.
3. Nimipalvelin
Nimipalvelin sisältää tietoja koko järjestelmäympäristöstä. Hajautetussa käyttöönotossa se tracks tunnistaa jokaisen käynnissä olevan komponentin ja datan sijainnin solmujen välillä, jotta kyselyt voidaan reitittää oikealle palvelimelle.
4. Tilastopalvelin
Tilastopalvelin kerää tila-, resurssien kohdentamis-, kulutus- ja suorituskykytietoja SAP HANA-järjestelmä. Huomautus: HANA SPS 7:ssä ja uudemmissa versioissa upotettu tilastopalvelu toimii indeksipalvelimen sisällä eikä itsenäisenä prosessina.
5. XS-palvelin
XS Server isännöi XS Engineä, jonka avulla ulkoiset sovellukset ja kehittäjät voivat käyttää SAP HANA-tietokanta HTTP:n kautta. XS Engine itse toimii kevyenä HTTP-palvelimena, jonka avulla selainpohjaiset ja REST-asiakkaat voivat kommunikoida suoraan HANA:n kanssa.
SAP HANA Maisema
”HANA” tarkoittaa Tehokas analyyttinen laite ja se toimitetaan yhdistettynä laitteisto- ja ohjelmistoalustana.
- Nykyaikainen laitteisto tarjoaa paljon enemmän suorittimen ytimiä, RAM-muistia ja tallennuskaistanleveyttä kuin vanhat tietokantapalvelimet on suunniteltu käyttämään.
- SAP HANA hyödyntää tätä Kee:n toimesta.ping kaikki työdata päämuistissa, mikä poistaa perinteisiä tietokantoja rajoittavan levyn I/O-pullonkaulan.
Alla oleva kaavio tiivistää SAP HANA-laitteisto- ja ohjelmistoinnovaatiot.

SAP HANA tukee kahta relaatiotietovarastoa: Rivikauppa ja Sarakekauppa.
Rivikauppa
Rivivarasto toimii kuten perinteinen tietokanta (Oracle, SQL Server). Keskeinen ero on, että kaikki rivit sijaitsevat päämuistissa SAP HANA, kun taas perinteinen tietokanta säilyttää niitä pääasiassa levyllä.
Sarakekauppa
Column Store säilyttää tiedot sarakemuodossa muistissa. Saraketaulukot tallennetaan tänne, ja moottori tasapainottaa hyvän kirjoitustehon optimoidun lukutehon kanssa. Alla oleva kaavio näyttää kaksi rakennetta, jotka saavuttavat tämän tasapainon.

Päävarasto
Päämuisti säilyttää suurimman osan tiedoista. Muistin säästämiseksi ja hakujen nopeuttamiseksi käytetään pakkausmenetelmiä, kuten sanakirjakoodausta, klusterikoodausta, harvaa koodausta ja run-length-koodausta.
- Pakatun datan muokkaaminen suoraan päämuistissa on kallista, joten kirjoitukset eivät kohdistu päämuistiin.
- Sen sijaan jokainen muutos kirjoitetaan erilliseen alueeseen nimeltä Delta varastointiLukuoperaatiot voivat osua joko pää- tai delta-tallennustilaan.
Tiedot voidaan ladata tai purkaa manuaalisesti käyttämällä Lataa muistiin ja Pura muistista alla esitetyt vaihtoehdot.

Delta varastointi
Delta Tallennustila on optimoitu kirjoituksille ja siinä käytetään kevyempää pakkausta. Kaikki saraketaulukon vahvistamattomat muutokset tallennetaan tänne. Kun muutokset on yhdistettävä takaisin päätallennustilaan, suorita Delta mennä toiminta alkaen SAP HANA Studio.

- Delta-yhdistäminen siirtää delta-tallennustilaan kerätyt muutokset päätallennustilaan.
- Yhdistämisen jälkeen uusi päätallennussisältö tallennetaan levylle ja pakkaus lasketaan uudelleen.
Miten tiedot siirtyvät Delta päämuistiin

Rivijärjestetty puskuri, jota kutsutaan L1-Delta sijaitsee jokaisen saraketaulukon edessä, minkä vuoksi saraketaulukko voi absorboida suuren läpimenon kirjoitussuorituksia.
- Käyttäjä suorittaa taulukolle UPDATE- tai INSERT-komennon.
- Data laskeutuu ensin tasolle L1-Delta (sitoutumaton data).
- Kun tiedot on vahvistettu, ne siirretään sarakepohjaiseen L2-muotoon.Delta puskuria.
- Kun L2-Delta on täynnä tai yhdistäminen suoritetaan, tiedot kirjoitetaan päämuistiin.
Saraketallennus on siis sekä kirjoitusoptimoitua (L1- ja L2-deltan kautta) että lukuoptimoitua (päätallennuksen kautta). Käsittelyn jälkeen tiedot tallennetaan levylle pysyvyyskerroksen avulla.
Esimerkki rivipohjaisesta taulukosta:

Sama looginen taulukko tallennetaan levylle eri tavoin tallennustyypistä riippuen. Rivisäilössä rivit kirjoitetaan vierekkäin:

Sarakevarastossa saman sarakkeen arvot tallennetaan yhdessä:

Koska sarakearvot jakavat saman tietotyypin ja usein toistuvat, sarakeasettelu pakkautuu erittäin hyvin – mikä on saraketallennustilan tärkein muistietu.

SAP HANA Mitoitus
Kokomääritys on prosessi, jossa määritetään laitteistoresurssit – RAM-muisti, levy ja suoritin – joita tarvitaan SAP HANA-järjestelmä. Muisti on tärkein tekijä, suoritin on toinen ja levy on johdettu kahdesta ensimmäisestä.
Jonkin sisällä SAP HANA-toteutuksessa oikean palvelimen koon valitseminen liiketoiminnan työkuormalle on yksi kriittisimmistä tehtävistä. Perinteiseen tietokannan hallintajärjestelmään verrattuna HANA-kootus eroavat kolmella osa-alueella:
- Keskusmuisti: metatietojen sekä muistissa olevien tapahtuma- ja analyyttisten tietojen määrän perusteella.
- CPU: arvioitu eikä mitattu, ennustekyselyn ja kuormitusmallien perusteella.
- Levy: kooltaan datan säilyvyyden ja lokimäärien mukaan, ei online-kyselydatan mukaan.
Sovelluspalvelimen suorittimen ja muistin määrä pysyy samana kuin edellisessä tietokannassa, koska HANA korvaa vain tietokantatason.
SAP tarjoaa useita menetelmiä oikean koon laskemiseksi:
- Koko ABAP-raportin avulla (tapahtumakoodi ST03 tiedot ja raportti /SDF/HDB_KOKO).
- Kokomääritys tietokantakomentosarjan avulla muille kuin ABAP-järjestelmille.
- Mitoitus käyttämällä SAP Pikakokolaskuri työkalu päällä SAP Palvelumarkkinapaikka.
Kun käytetään Pikakoon mittaus -työkalua, vaatimus näytetään alla olevassa muodossa.
