Kuinka asentaa Hadoop UbuntuLataus- ja asennusvaiheet
⚡ Älykäs yhteenveto
Apache Hadoopin asentaminen Ubuntu vaatii kaksi vaihetta: purkaa julkaisun erilliselle järjestelmätilille salasanattoman SSH:n avulla, sitten muokkaa neljää XML-tiedostoa ennen HDFS:n alustamista ja yksisolmuisen klusterin käynnistämistä.

Tässä opetusohjelmassa käymme läpi vaiheittaisen prosessin Apache Hadoopin asentamiseksi Linux-tietokoneelle (Ubuntu). Tämä on kaksiosainen prosessi: lataa ja asenna ensin julkaisu ja määritä se sitten.
Edellytyksiä on kaksi:
- Sinun täytyy olla Ubuntu asennetaan ja juokseminen.
- Sinun täytyy olla Java asennetaan.
Hadoop 3.x -version muistiinpanoja tälle asennukselle
Tämän ohjeen kuvakaappaukset on otettu Hadoop 2.2.0:lla. Vaihejärjestys on pysynyt muuttumattomana nykyisissä versioissa, mutta joitakin nimiä ja oletusarvoja on siirretty. Tarkista alla oleva taulukko ennen kuin kopioit mitään komentoja sanatarkasti.
| Asetus tai vaihe | Tässä opetusohjelmassa (Hadoop 2.x) | Nykyinen Hadoop 3.x |
|---|---|---|
| Julkaisuarkisto | hadoop-2.2.0.tar.gz |
hadoop-3.5.0.tar.gz, ensimmäinen vakaa 3.5-julkaisu, julkaistu 2. huhtikuuta 2026 |
| Oletustiedostojärjestelmän ominaisuus | fs.default.name proosassa fs.defaultFS XML-tiedostossa |
fs.defaultFS vain; fs.default.name on vanhentunut |
| MapReduce-ominaisuus | mapreduce.jobtracker.address |
mapreduce.framework.name asetettu yarnTyöTracker-funktiota ei enää ole olemassa, kun YARN aikatauluttaa työn |
| mapred-site.xml | Kopioitu kohteesta mapred-site.xml.template |
Lähetetään sisään etc/hadoop jo, joten kopiointivaihe on tarpeeton |
| NameNode-verkkokäyttöliittymän portti | 50070 | 9870 |
| Java | Java 6 tai Java 7 | Java 8 tai Java 11 |
Kaikki muu tässä oppaassa toimii samalla tavalla Hadoop 3:ssa: erillinen tili, SSH-avain, neljä määritystiedostoa sekä aloitus- ja lopetusskriptit.
Osa 1) Lataa ja asenna Hadoop
Vaihe 1) Lisää Hadoop-järjestelmän käyttäjä
Lisää Hadoop-järjestelmän käyttäjä alla olevalla komennolla.
sudo addgroup hadoop_

sudo adduser --ingroup hadoop_ hduser_
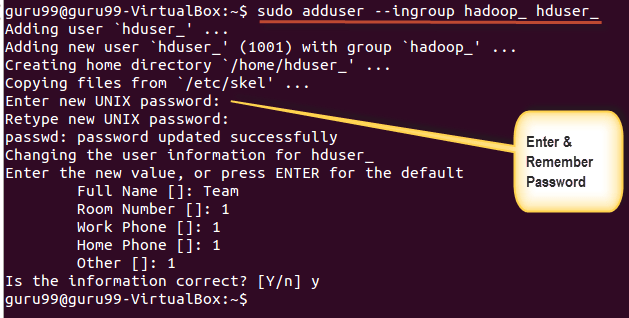
Anna salasanasi, nimesi ja muut tiedot.
HUOMAUTUS: Tässä asennusprosessissa on mahdollista, että esiintyy alla mainittu virhe.
"hduser ei ole sudoers-tiedostossa. Tästä tapauksesta tiedotetaan."

Tämä virhe voidaan korjata kirjautumalla sisään pääkäyttäjänä.

Suorita komento
sudo adduser hduser_ sudo

Re-login as hduser_

Vaihe 2) Määritä SSH
Solmujen hallintaan klusterissa Hadoop vaatii SSH-yhteyden.
Vaihda ensin käyttäjää ja anna seuraava komento
su - hduser_

Tämä komento luo uuden avaimen.
ssh-keygen -t rsa -P ""

Ota SSH-yhteys paikalliseen koneeseen käyttöön tällä avaimella.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
![]()
Testaa nyt SSH-asetuksia muodostamalla yhteys localhostiin käyttäjänä 'hduser_'.
ssh localhost

Huomautus: Jos näet alla olevan virheen vastauksena 'ssh localhost' -komennolle, on mahdollista, että SSH ei ole käytettävissä tässä järjestelmässä.

Tämän ratkaisemiseksi -
Tyhjennä SSH käyttämällä
sudo apt-get purge openssh-server
On hyvä käytäntö tyhjentää se ennen asennuksen aloittamista.

Asenna SSH komennolla-
sudo apt-get install openssh-server

Vaihe 3) Lataa Hadoop
Seuraava vaihe on ladata Hadoop osoitteesta Apache Hadoopin julkaisusivu.

Valitse Vakaa

Valitse tar.gz-tiedosto (ei src-päätteistä tiedostoa).

Kun lataus on valmis, siirry tar-tiedoston sisältävään hakemistoon.
![]()
Enter,
sudo tar xzf hadoop-2.2.0.tar.gz
![]()
Nimeä nyt hadoop-2.2.0 uudelleen nimellä hadoop.
sudo mv hadoop-2.2.0 hadoop
![]()
Lopuksi anna kansio uudelle tilille.
sudo chown -R hduser_:hadoop_ hadoop
![]()
Korvaa lataamasi versio hadoop-2.2.0 kolmessa yllä olevassa komennossa.
Osa 2) Määritä Hadoop
Vaihe 1) Muokkaa ~/.bashrc-tiedostoa
Lisää seuraavat rivit tiedoston ~/.bashrc loppuun.
#Set HADOOP_HOME export HADOOP_HOME=<Installation Directory of Hadoop> #Set JAVA_HOME export JAVA_HOME=<Installation Directory of Java> # Add bin/ directory of Hadoop to PATH export PATH=$PATH:$HADOOP_HOME/bin
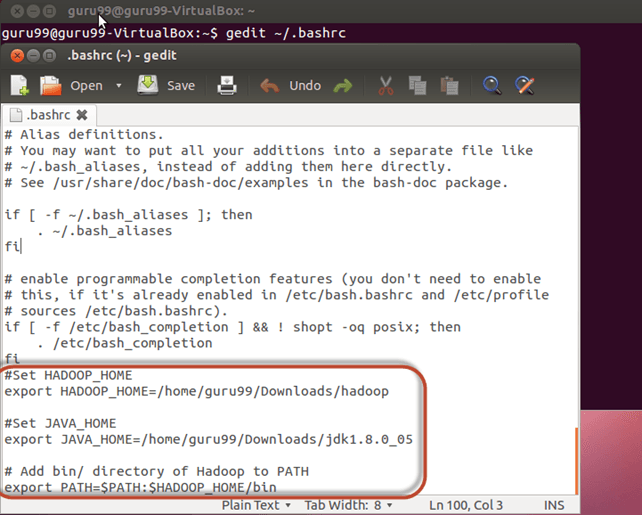
Nyt lähdekoodin luo tämä ympäristön kokoonpano alla olevalla komennolla.
. ~/.bashrc
![]()
Vaihe 2) HDFS:ään liittyvät konfiguraatiot
Aseta JAVA_HOME tiedostoon $HADOOP_HOME/etc/hadoop/hadoop-env.sh, kuten alla näkyy.
![]()

Kanssa

Tiedostossa $HADOOP_HOME/etc/hadoop/core-site.xml on kaksi parametria, jotka on asetettava:
1. 'hadoop.tmp.dir' – Käytetään määrittämään hakemisto, jota Hadoop käyttää datatiedostojensa tallentamiseen.
2. 'fs.defaultFS' – Tämä määrittää oletusarvoisen tiedostojärjestelmän. Saman ominaisuuden vanhempi nimi, 'fs.default.name', on vanhentunut.
Aseta nämä parametrit avaamalla core-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/core-site.xml
![]()
Kopioi alla olevat rivit tekstin väliin tunnisteet.
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. </description> </property>

Siirry hakemistoon $HADOOP_HOME/etc/hadoop.

Luo nyt core-site.xml-tiedostossa mainittu hakemisto.
sudo mkdir -p <Path of Directory used in above setting>
![]()
Myönnä hakemistoon käyttöoikeudet.
sudo chown -R hduser_:Hadoop_ <Path of Directory created in above step>
![]()
sudo chmod 750 <Path of Directory created in above step>
![]()
Vaihe 3) MapReduce-konfiguraatio
Ennen kuin aloitat näiden määritysten kanssa, asetetaan HADOOP_HOME-polku.
sudo gedit /etc/profile.d/hadoop.sh
Ja Enter
export HADOOP_HOME=/home/guru99/Downloads/Hadoop

Seuraavaksi syötä
sudo chmod +x /etc/profile.d/hadoop.sh
![]()
Poistu terminaalista ja käynnistä se uudelleen.
Tarkista polku kirjoittamalla echo $HADOOP_HOME.
![]()
Kopioi nyt tiedostot
sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
![]()
Avaa mapred-site.xml-tiedosto
sudo gedit $HADOOP_HOME/etc/hadoop/mapred-site.xml
![]()
Lisää alla olevat asetukset väliin ja tunnisteet.
<property> <name>mapreduce.jobtracker.address</name> <value>localhost:54311</value> <description>MapReduce job tracker runs at this host and port. </description> </property>

Avaa $HADOOP_HOME/etc/hadoop/hdfs-site.xml alla olevan mukaisesti,
sudo gedit $HADOOP_HOME/etc/hadoop/hdfs-site.xml
![]()
Lisää alla olevat asetukset väliin ja tunnisteet.
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser_/hdfs</value> </property>

Luo yllä olevassa asetuksessa määritetty hakemisto.
sudo mkdir -p <Path of Directory used in above setting>
sudo mkdir -p /home/hduser_/hdfs
![]()
Sitten myönnä sille omistajuus ja käyttöoikeudet.
sudo chown -R hduser_:hadoop_ <Path of Directory created in above step>
sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs
![]()
sudo chmod 750 <Path of Directory created in above step>
sudo chmod 750 /home/hduser_/hdfs
![]()
Vaihe 4) Alusta HDFS
Ennen kuin käynnistämme Hadoopin ensimmäistä kertaa, alusta HDFS alla olevalla komennolla.
$HADOOP_HOME/bin/hdfs namenode -format

Vaihe 5) Käynnistä Hadoop-yksisolmuklusteri
Käynnistä Hadoopin yhden solmun klusteri alla olevalla komennolla.
$HADOOP_HOME/sbin/start-dfs.sh
Yllä olevan komennon tuloste on esitetty alla.

Käynnistä sitten YARN-daemonit.
$HADOOP_HOME/sbin/start-yarn.sh

Tarkista 'jps'-työkalulla, ovatko kaikki Hadoopiin liittyvät prosessit käynnissä.
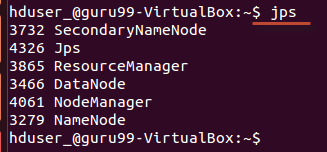
Jos Hadoop on käynnistynyt onnistuneesti, jps-tulosteen pitäisi sisältää NameNode, NodeManager, ResourceManager, SecondaryNameNode ja DataNode.
Vaihe 6) Pysähdyping Hadoop
Sammuta klusteri käänteisessä järjestyksessä.
$HADOOP_HOME/sbin/stop-dfs.sh

$HADOOP_HOME/sbin/stop-yarn.sh

Kuinka varmistaa, että Hadoop on käynnissä, ja korjata yleisiä virheitä
jps-tuloste vahvistaa prosessien käynnistymisen, mutta ei sitä, että klusteri on käyttökelpoinen. Neljä lisätarkistusta ratkaisee tämän kysymyksen.
- Avaa NameNoden web-käyttöliittymä osoitteessa
http://localhost:9870(portti 50070 Hadoop 2.x:ssä) ja vahvista, että yhteenveto raportoi yhden aktiivisen solmun. - Avaa ResourceManager-käyttöliittymä osoitteessa
http://localhost:8088vahvistaakseen, että YARN hyväksyi NodeManagerin. - ajaa
hdfs dfsadmin -reportkapasiteetin, aktiivisten DataNodejen ja alireplikoitujen lohkojen osalta. - Kirjoita jotain:
hdfs dfs -mkdir /testjälkeenhdfs dfs -ls /todistaa, että nimiavaruus hyväksyy muutokset.
Useimmat ensimmäiset epäonnistumiset kuuluvat johonkin viidestä kategoriasta.
| Oire | Aiheuttaa | Korjata |
|---|---|---|
| JAVA_HOME-tiedostoa ei ole asetettu eikä sitä löydetty. | Muuttuja viedään .bashrc-tiedostoon, mutta ei hadoop-env.sh-tiedostoon. | Aseta absoluuttinen JDK-polku myös hadoop-env.sh-tiedoston sisällä |
| Käyttöoikeus evätty (julkinen avain, salasana) ssh localhostissa | authorized_keys puuttuu tai on liian salliva | Liitä id_rsa.pub uudelleen ja suorita sitten chmod 600 hakemistossa ~/.ssh/authorized_keys |
| Yhteys estetty portissa 22 | openssh-palvelinta ei ole asennettu tai se ei ole käynnissä | Asenna openssh-server ja käynnistä ssh-palvelu |
| DataNode puuttuu jps:stä uudelleenmuotoilun jälkeen | Cluster Muotoillun NameNode-hakemiston ja vanhan DataNode-hakemiston ID-ristiriita | Tyhjennä dfs.datanode.data.dir-kansio ja alusta se uudelleen. |
| start-dfs.sh: komentoa ei löytynyt | HADOOP_HOME- ja PATH-metodeja ei koskaan sisällytetty nykyiseen komentotulkkiin. | Suorita .~/.bashrc tai avaa uusi pääte |