ETL (esim.tract-, muunnos- ja latausprosessi tietovarastossa
Älykäs yhteenveto
ETL (esim.tracTietovaraston (t, Transform ja Load) prosessi kuvaa systemaattista tiedonsiirtoa useista heterogeenisistä lähteistä keskitettyyn tietovarastoon. Se varmistaa tiedon johdonmukaisuuden, tarkkuuden ja analytiikkavalmiuden strukturoidun analyysin avulla.tractio, muunnos ja optimoidut lastausmekanismit.

Mikä on ETL?
ETL on prosessi, joka esim.trackerää tietoja eri lähdejärjestelmistä, muuntaa ne (kuten laskelmien ja ketjutusten avulla) ja lopuksi lataa ne tietovarastojärjestelmään. ETL:n täydellinen muoto on Extract, Muunna ja Lataa.
On houkuttelevaa ajatella, että tietovaraston luominen yksinkertaisesti vaatii esim.tracdatan keräämistä useista lähteistä ja lataamista tietokantaan. Todellisuudessa se kuitenkin vaatii monimutkaisen ETL-prosessin. ETL-prosessi vaatii aktiivista panosta useilta sidosryhmiltä, kuten kehittäjiltä, analyytikoilta, testaajilta ja johdolta, ja on teknisesti haastava.
Jotta tietovarastojärjestelmä säilyisi päätöksentekijöiden työkaluna, sen on muututtava liiketoiminnan muutosten mukana. ETL on tietovarastojärjestelmän toistuva toiminto (päivittäin, viikoittain tai kuukausittain), ja sen on oltava ketterä, automatisoitu ja hyvin dokumentoitu.
Miksi tarvitset ETL:n?
ETL:n käyttöönotolle organisaatiossa on monia syitä:
- Se auttaa yrityksiä analysoimaan liiketoimintatietojaan kriittisten liiketoimintapäätösten tekemiseksi.
- Transaktiotietokannat eivät pysty vastaamaan monimutkaisiin liiketoimintakysymyksiin, joihin voidaan vastata ETL-esimerkillä.
- Tietovarasto tarjoaa yhteisen tietovaraston
- ETL tarjoaa tavan siirtää dataa eri lähteistä tietovarastoon.
- Kun tietolähteet muuttuvat, tietovarasto päivittyy automaattisesti.
- Hyvin suunniteltu ja dokumentoitu ETL-järjestelmä on lähes välttämätön tietovarastoprojektin onnistumiselle.
- Salli datan muunnos-, yhdistämis- ja laskentasääntöjen tarkistaminen.
- ETL-prosessi mahdollistaa näytedatan vertailun lähde- ja kohdejärjestelmän välillä.
- ETL-prosessi voi suorittaa monimutkaisia muunnoksia ja vaatii ylimääräisen tallennustilan datan tallentamiseen.
- ETL auttaa siirtämään tietoja tietovarastoon muuntamalla eri muodot ja tyypit yhdeksi yhtenäiseksi järjestelmäksi.
- ETL on ennalta määritetty prosessi lähdetietojen käyttämiseksi ja käsittelemiseksi kohdetietokantaan.
- ETL tietovarastossa tarjoaa syvällisen historiallisen kontekstin liiketoiminnalle.
- Se auttaa parantamaan tuottavuutta, koska se koodaa ja käyttää uudelleen ilman teknisiä taitoja.
Ymmärrettyämme ETL:n arvon, sukeltakaamme kolmivaiheiseen prosessiin, joka saa kaiken toimimaan.
ETL-prosessi tietovarastoissa
ETL on 3-vaiheinen prosessi
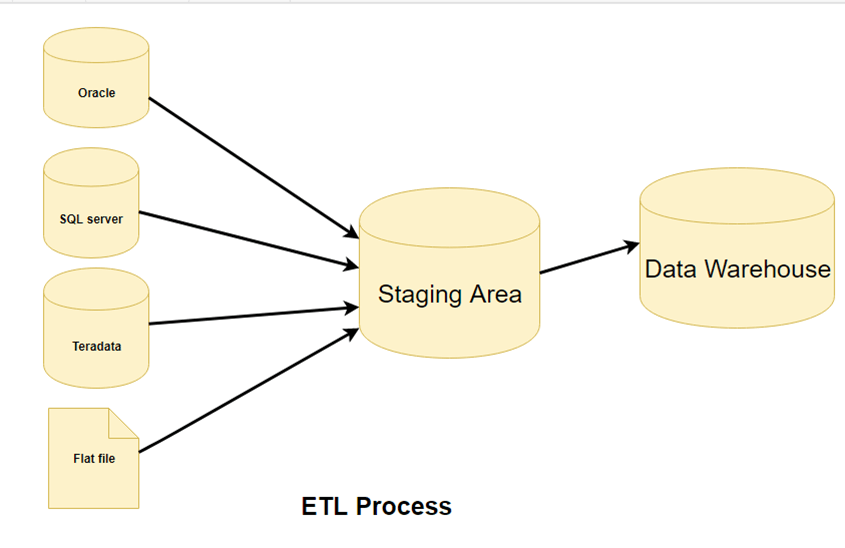
Vaihe 1) Esim.tracTUKSEN
Tässä ETL-arkkitehtuurin vaiheessa dataa käytetään esimerkiksi seuraavissa vaiheissa:traclähdejärjestelmästä lavastusalueelle. Mahdolliset muunnokset tehdään lavastusalueella, jotta lähdejärjestelmän suorituskyky ei heikkene. Myös jos vioittunutta dataa kopioidaan suoraan lähteestä tietovaraston tietokantaan, palautus on haasteellista. Lavastusalue antaa mahdollisuuden validoida extracdataa ennen sen siirtämistä tietovarastoon.
Tietovaraston on integroitava järjestelmiä, joilla on erilaiset tietokannan hallintajärjestelmät, laitteistot, Operating-järjestelmät ja tietoliikenneprotokollat. Lähteisiin voivat kuulua muun muassa vanhat sovellukset, kuten keskustietokoneet, räätälöidyt sovellukset, yhteyspistelaitteet, kuten pankkiautomaatit, puhelunvälittimet, tekstitiedostot, laskentataulukot, toiminnanohjausjärjestelmät sekä toimittajien ja kumppaneiden tiedot.
Siksi tarvitaan looginen datakartta ennen kuin dataa voidaan käyttäätracfyysisesti testattu ja ladattu. Tämä datakartta kuvaa lähteiden ja kohdedatan välistä suhdetta.
Kolme dataa Extracmenetelmät:
- Täysi entinentracTUKSEN
- Osittainen Extractio - ilman päivitysilmoitusta.
- Osittainen Extracpäivitysilmoituksella
Käytetystä menetelmästä riippumatta, esim.traction ei pitäisi vaikuttaa lähdejärjestelmien suorituskykyyn tai vasteaikaan. Nämä lähdejärjestelmät ovat reaaliaikaisia tuotantotietokantoja. Mikä tahansa hidastuminen tai lukittuminen voi vaikuttaa yrityksen tulokseen.
Jotkin validoinnit tehdään Ex-jakson aikanatracseen:
- Täsmätä tietueet lähdetietojen kanssa
- Varmista, ettei roskapostia/ei-toivottuja tietoja ole ladattu
- Tietotyypin tarkistus
- Poista kaiken tyyppiset päällekkäiset/hajanaiset tiedot
- Tarkista, ovatko kaikki avaimet paikoillaan.
Vaihe 2) Muunnos
Data extracLähdepalvelimelta saatu data on raakaa eikä sitä voi käyttää alkuperäisessä muodossaan. Siksi se on puhdistettava, kartoitettava ja muunnettava. Itse asiassa tämä on avainvaihe, jossa ETL-prosessi lisää arvoa ja muuttaa dataa siten, että voidaan luoda hyödyllisiä BI-raportteja.
Se on yksi tärkeimmistä ETL-käsitteistä, jossa käytät joukkoa funktioita esim.tracted-dataa. Dataa, joka ei vaadi muunnoksia, kutsutaan suora liike or läpikulkudata.
Muunnosvaiheessa voit suorittaa mukautettuja toimintoja datalle. Jos käyttäjä esimerkiksi haluaa myyntituottojen summan, jota ei ole tietokannassa. Tai jos taulukon etunimi ja sukunimi ovat eri sarakkeissa, ne voidaan yhdistää ennen lataamista.

Seuraavat ovat tietoja Integrity Ongelmat:
- Saman henkilön eri kirjoitusasut, kuten Jon, John jne.
- Yrityksen nimeä voi merkitä monella eri tavalla, esim. Google, Google Inc.
- Eri nimien, kuten Cleaveland ja Cleveland, käyttö.
- Voi olla tapauksia, joissa eri sovellukset luovat samalle asiakkaalle eri tilinumeroita.
- Joissakin tapauksissa vaaditut tiedostot jäävät tyhjiksi
- Myyntipisteeltä noudettu virheellinen tuote, koska manuaalinen syöttö voi johtaa virheisiin.
Vahvistukset tehdään tässä vaiheessa
- Suodatus – Valitse vain tietyt ladattavat sarakkeet
- Sääntöjen ja hakutaulukoiden käyttäminen tietojen standardointiin
- Merkistöjen muuntaminen ja koodauksen käsittely
- Mittayksiköiden muuntaminen, kuten päivämäärän ja kellonajan muuntaminen, valuuttamuuntaminen, numeerinen muuntaminen jne.
- Tietojen kynnysarvon validointitarkistus. Esimerkiksi ikä ei voi olla yli kaksinumeroinen.
- Tietovirran validointi lavastusalueelta välitaulukoihin.
- Pakollisia kenttiä ei saa jättää tyhjiksi.
- Siivous (esimerkiksi kartanping NULL arvoon 0 tai sukupuoli (mies arvoon ”M” ja nainen arvoon ”N” jne.)
- Jaa sarake useisiin sarakkeisiin ja yhdistä useita sarakkeita yhdeksi sarakkeeksi.
- Rivien ja sarakkeiden transponointi,
- Käytä hakuja tietojen yhdistämiseen
- Käyttämällä mitä tahansa monimutkaista datan validointia (esim. jos rivin kaksi ensimmäistä saraketta ovat tyhjiä, rivi hylätään automaattisesti käsittelystä)
Vaihe 3) Lataus
Datan lataaminen kohdetietovaraston tietokantaan on ETL-prosessin viimeinen vaihe. Tyypillisessä tietovarastossa on ladattava valtava määrä dataa suhteellisen lyhyessä ajassa (yössä). Siksi latausprosessi tulisi optimoida suorituskyvyn kannalta.
Latausvirheen sattuessa palautusmekanismit tulisi konfiguroida käynnistymään uudelleen vikaantumiskohdasta ilman tietojen eheyden menetystä. Tietovaraston ylläpitäjien on valvottava, jatkettava ja peruutettava latauksia palvelimen vallitsevan suorituskyvyn mukaan.
Lataustyypit:
- Alkukuorma — kaikkien tietovarastotaulukoiden täyttäminen
- Inkrementaalinen kuormitus — jatkuvien muutosten tekeminen tarvittaessa säännöllisesti.
- Täysi päivitys — yhden tai useamman taulukon sisällön poistaminen ja uusien tietojen lataaminen.
Lataa vahvistus
- Varmista, että avainkentän tiedot eivät ole puuttuvia tai tyhjiä.
- Testaa mallinnusnäkymiä kohdetaulukoiden perusteella.
- Tarkista yhdistetyt arvot ja lasketut mitat.
- Tietojen tarkistukset sekä ulottuvuus- että historiataulukossa.
- Tarkista BI-raportit ladatusta fakta- ja dimensiotaulukosta.
ETL-liukuhihnakäsittely ja rinnakkaiskäsittely
ETL-liukuhihna mahdollistaa esim.tractapahtua, muuttua ja lastautua samanaikaisesti peräkkäisen sijaan. Heti kun osa tiedoista on poistettutracted, se muunnetaan ja ladataan samalla kun uutta dataa luodaantracjatkuu. Tämä rinnakkainen käsittely parantaa huomattavasti suorituskykyä, vähentää seisokkiaikoja ja maksimoi järjestelmän resurssien käytön.
Tämä rinnakkaiskäsittely on välttämätöntä reaaliaikainen analyysi, laajamittainen datan integrointi ja pilvipohjaiset ETL-järjestelmät. Päällekkäisyyden kauttaping tehtäviä, liukuhihnapohjainen ETL varmistaa nopeamman tiedonsiirron, paremman tehokkuuden ja yhdenmukaisemman tiedon toimituksen nykyaikaisille yrityksille.
Kuinka tekoäly parantaa nykyaikaisia ETL-putkistoja?
Tekoäly revolutionisoi ETL:ää tekemällä dataputkista mukautuvia, älykkäitä ja itseoptimoituvia. Tekoälyalgoritmit voivat automaattisesti kartoittaa skeemoja, havaita poikkeavuuksia ja ennustaa muunnossääntöjä ilman manuaalista konfigurointia. Tämä mahdollistaa ETL-työnkulkujen käsitellä kehittyviä tietorakenteita vaivattomasti ja samalla säilyttää tiedon laadun.
Nykyaikaiset tekoälyllä parannetut ETL-alustat hyödyntävät teknologioita, kuten AutoML:ää automaattiseen ominaisuuksien suunnitteluun ja NLP-pohjaista skeemakarttaa.ping joka ymmärtää kenttien välisiä semanttisia suhteita, ja poikkeamien havaitsemisalgoritmeja, jotka tunnistavat datan laatuongelmia reaaliajassa. Nämä ominaisuudet vähentävät merkittävästi manuaalista työtä, jota perinteisesti vaaditaan ETL-kehityksessä ja -ylläpidossa.
Koneen oppiminen Parantaa suorituskyvyn optimointia varmistaen nopeamman ja tarkemman datan integroinnin. Automaatiota ja ennakoivaa älykkyyttä hyödyntävä tekoälypohjainen ETL tarjoaa reaaliaikaisia tietoja ja tehostaa pilvi- ja hybriditietoekosysteemejä.
Yllä käsiteltyjen konseptien toteuttamiseksi organisaatiot luottavat erikoistuneisiin ETL-työkaluihin. Tässä on joitakin markkinoiden johtavia vaihtoehtoja.
ETL-työkalut
On olemassa monia ETL-työkalut saatavilla markkinoilla. Tässä on joitakin merkittävimmistä:
1. MarkLogic:
MarkLogic on tietovarastointiratkaisu, joka helpottaa ja nopeuttaa tietojen integrointia käyttämällä useita yritystason ominaisuuksia. Se voi tehdä kyselyitä erityyppisistä tiedoista, kuten dokumenteista, suhteista ja metatiedoista.
https://www.marklogic.com/product/getting-started/
2. Oracle:
Oracle on alan johtava tietokanta. Se tarjoaa laajan valikoiman tietovarastoratkaisuja sekä paikallisesti että pilvessä. Se auttaa optimoimaan asiakaskokemuksia lisäämällä toiminnan tehokkuutta.
https://www.oracle.com/index.html
3. Amazon punainenShift:
Amazon Redshift on tietovarastotyökalu. Se on yksinkertainen ja kustannustehokas työkalu kaikenlaisten tietojen analysointiin standardin mukaisesti. SQL ja olemassa olevat BI-työkalut. Se mahdollistaa myös monimutkaisten kyselyjen suorittamisen strukturoidun datan petatavuilla.
https://aws.amazon.com/redshift/?nc2=h_m1
Tässä on täydellinen luettelo hyödyllisistä tietovarastotyökalut.
ETL-prosessin parhaat käytännöt
Seuraavat ovat ETL-prosessin vaiheiden parhaat käytännöt:
- Älä koskaan yritä puhdistaa kaikkia tietoja:
Jokainen organisaatio haluaisi puhdistaa kaiken datan, mutta useimmat niistä eivät ole valmiita maksamaan odottamisesta tai eivät ole valmiita odottamaan. Kaiken puhdistaminen veisi yksinkertaisesti liian kauan, joten on parempi olla yrittämättä puhdistaa kaikkea dataa. - Tasapainon puhdistus liiketoiminnan prioriteettien kanssa:
Vaikka sinun tulisi välttää kaikkien tietojen ylipuhdistamista, varmista, että kriittiset ja vaikuttavat kentät puhdistetaan luotettavuuden takaamiseksi. Keskity puhdistamaan tietoja, jotka vaikuttavat suoraan liiketoimintapäätöksiin ja raportoinnin tarkkuuteen. - Määritä tietojen puhdistamisen kustannukset:
Ennen kuin puhdistat kaikki likaiset tiedot, sinun on tärkeää määrittää jokaisen likaisen tietoelementin puhdistuskustannukset. - Voit nopeuttaa kyselyn käsittelyä käyttämällä apunäkymiä ja -hakemistoja:
Tallenna yhteenvetotiedot levynauhoille säästääksesi tallennuskustannuksia. Lisäksi vaaditaan kompromissi tallennettavan tiedon määrän ja sen yksityiskohtaisen käytön välillä. Kompromissi tietojen tarkkuuden tasolla tallennuskustannusten vähentämiseksi.