Scikit-Learni õpetus: kuidas installida ja Scikit-Learn näiteid
⚡ Nutikas kokkuvõte
Scikit-learn on avatud lähtekoodiga Python teek, mis hõlmab eeltöötlust, klassifitseerimist, regressiooni, klastrite moodustamist ja mudelivalikut ühe ühtse hindajaliidese taga, mis hoiab kogu masinõppe töövoo lühikese, loetava ja reprodutseeritava toorandmetest kuni punktiarvestuseni.

Mis on Scikit-learn?
Scikit-õppida on avatud lähtekoodiga Python raamatukogu jaoks masinõpeSee toetab väljakujunenud algoritme nagu KNN, gradiendi võimendamine, juhuslik mets ja SVM ning on üles ehitatud ... peale. tuim ja SciPy. Scikit-learni kasutatakse laialdaselt nii Kaggle'i võistlustel kui ka tuntud tehnoloogiaettevõtetes. See hõlmab eeltöötlust, dimensioonide vähendamist, klassifitseerimist, regressiooni, klasterdamist ja mudelivalikut.
Scikit-learnil on parim dokumentatsioon avatud lähtekoodiga teekide seas. See pakub isegi interaktiivset kalkulaatori diagrammi, Õige kalkulaatori valimine, mis juhatab teid andmestiku suurusest proovimist väärt algoritmide nimekirjani.
Allolev joonis illustreerib Scikit-learni toimimist.
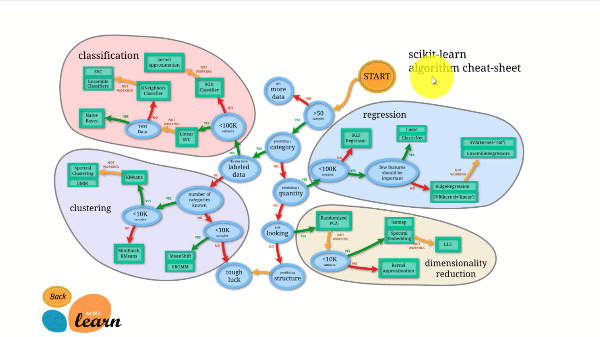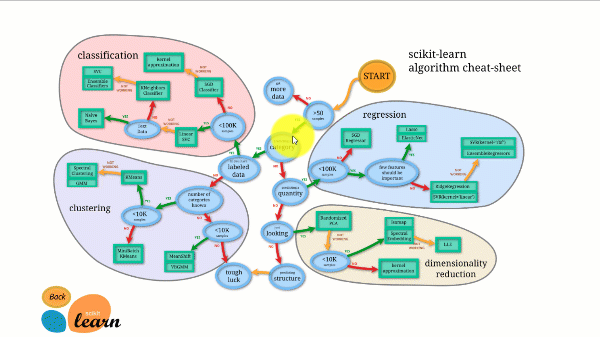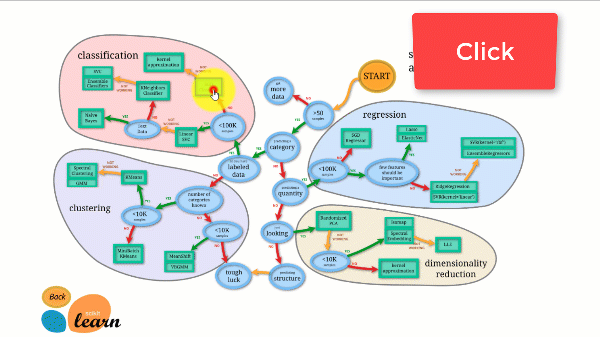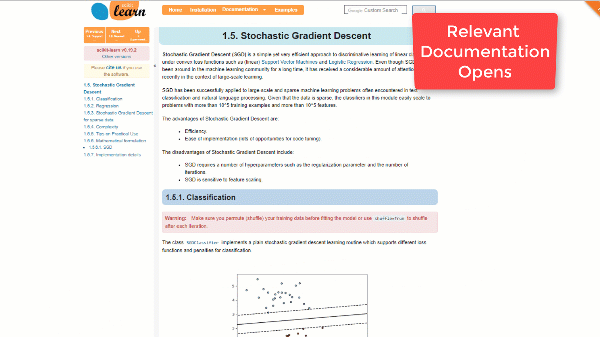
Scikit-learni pole keeruline kasutada ja see annab suurepäraseid tulemusi. See aga treenib protsessori peal: töö toimub paralleelselt erinevate tuumade vahel argumendi n_jobs abil, mitte graafikaprotsessori peal. Süvaõppe algoritmi käitamine sellega on võimalik, kuid harva optimaalne, eriti kui te juba teate, kuidas seda kasutada. TensorFlow.
Kuidas Scikit-learn alla laadida ja installida
Nüüd selles Python Scikit-learni õpetuses saate teada, kuidas Scikit-learni alla laadida ja installida:
1. variant: AWS
Scikit-learni saab kasutada AWS-i kaudu. Dockeri kujutis, millele on eelinstallitud scikit-learn, säästab täielikult seadistustöö.
Arendaja versiooni installimiseks käivitage allolev käsk sees Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
2. variant: Mac või Windows kasutades Anacondat
Anaconda paigaldamise kohta leiate teavet aadressilt Kuidas TensorFlow'i alla laadida ja installida.
Selle juhendi kirjutamise ajal olid scikiti arendajad välja andnud arendusversiooni, mis parandas tolleaegses väljaandes esinenud probleeme, seega kasutavad allolevad sammud seda arendaja versiooni. Tänapäeva uuel masinal sisaldab praegune stabiilne versioon juba kõiki siin kasutatud transformaatoreid ja pip install -U scikit-learn on piisav.
Kuidas installida scikit-learn Conda keskkonnaga
Kui installisite scikit-learni Conda keskkonnaga, järgige versioonile 0.20 värskendamiseks alltoodud samme.
1. samm) Aktiveerige tensorflow keskkond
source activate hello-tf
2. samm) Eemaldage scikit-learn käsuga conda
conda remove scikit-learn
3. samm) Installige arendaja versioon
Paigaldage scikit-learni arendaja versioon koos vajalike teekidega.
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
MÄRKUS: Windows kasutajad vajavad Microsoft Visuaalne C++ 14. Sa saad selle kätte siin.
Scikit-Learni näide masinõppega
See Scikiti õpetus on jagatud kaheks osaks:
- Masinõpe koos scikit-learniga
- Kuidas usaldada oma mudelit LIME'i
Esimeses osas kirjeldatakse, kuidas ehitada torujuhet, luua mudelit ja häälestada hüperparameetreid, teises osas aga käsitletakse mudeli tõlgendamist.
Samm 1) Importige andmed
Selle Scikiti õppematerjali ajal kasutate täiskasvanute rahvaloenduse andmekogumit.
Allolevas koodis loetakse fail otse UCI masinõppe hoidlast, seega pole käsitsi allalaadimist vaja. Kui olete huvitatud kirjeldavast statistikast, tasub vaadata tööriistu Dive ja Overview. Vaadake see õpetus et saada lisateavet sukeldumise ja ülevaate kohta.
Andmestiku impordite pandade abil. Pange tähele, et peate pidevad muutujad teisendama ujukomavormingusse.
See andmestik sisaldab kaheksat kategoorilist muutujat, mis on loetletud CATE_FEATURES:
- tööklass
- haridus
- abielu-
- okupatsioon
- suhe
- rass
- sugu
- kodumaa
See sisaldab ka kuut pidevat muutujat, mis on loetletud CONTI_FEATURES:
- vanus
- fnlwgt
- hariduse_nr
- kapitalikasum
- kapitali_kahjum
- tundi_nädal
Loendid täidetakse siin käsitsi, et teil oleks selgem ettekujutus, millised veerud on mängus. Kiirem viis kategooriliste või pidevate veergude loendi koostamiseks on:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
Siin on kood andmete importimiseks:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
Frame'i describe() kutsumine tagastab kuue pideva veeru kokkuvõtliku statistika:
| vanus | fnlwgt | hariduse_nr | kapitalikasum | kapitali_kahjum | tundi_nädal | |
|---|---|---|---|---|---|---|
| loe | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| keskmine | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| minutit | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Saate kontrollida native_country tunnuse unikaalsete väärtuste arvu. Ainult üks leibkond on pärit Hollandist. See leibkond ei too mingit infot ja annab treeningu ajal vea.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Selle mitteinformatiivse rea saate andmestikust välja jätta:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Järgmisena salvestate pidevate funktsioonide asukoha loendisse. Te vajate seda torujuhtme ehitamiseks järgmises etapis.
Allolev kood käib üle kõigi CONTI_FEATURES loendi veerunimede, loeb iga asukoha (st selle veerunumbri) ja lisab selle loendile nimega conti_features.
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
Järgmine plokk teeb sama tööd kategooriliste muutujate jaoks.
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Nüüd vaadake andmestikku ennast. Iga kategooriline tunnus on string ja mudelile ei saa sisestada stringväärtust, seega tuleb andmestikku teisendada näivmuutujatega.
df_train.head(5)
Tegelikult vajate iga funktsiooni iga rühma jaoks ühte veergu. Esmalt käivitage allolev kood, et arvutada vajalike veergude koguarv.
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
Nagu eespool näidatud, sisaldab kogu andmestik 101 gruppi. Ainult tööklassi funktsioonil on üheksa gruppi. Gruppide nimesid saab loetleda alloleva koodiga; unique() tagastab iga kategoorilise tunnuse erinevad väärtused.
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Seega sisaldab treeningandmestik 101 + 6 veergu: üks kuum rühm pluss kuus pidevat tunnust.
Scikit-learn saab konverteerimise eest hoolitseda kahes etapis:
- Teisenda string ID-ks. State-gov saab ID 1, Self-emp-not-inc saab ID 2 ja nii edasi. LabelEncoder teeb selle sinu eest ära.
- Transponeeri iga ID uude veergu. Andmestikul on 101 rühma ID-d, seega on iga kategoorilise tunnuste rühma jaoks 101 veergu. Scikit-learn pakub selle toimingu jaoks OneHotEncoderit.
2. samm) Looge rongi/katsekomplekt
Nüüd, kui andmestik on valmis, jagage see 80/20: 80 protsenti treeningkomplekti ja 20 protsenti testkomplekti jaoks.
Võite kasutada funktsiooni train_test_split. Esimene argument on funktsioonide andmeraamistik ja teine on silt. Testikomplekti suuruse saate määrata funktsiooniga test_size.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
3. samm) Ehitage torujuhe
See torujuhe lihtsustab mudeli varustamist järjepidevate andmetega. Idee seisneb toorandmete edastamises läbi ühe objekti, mis teostab kõik toimingud järjekorras.
Selle andmestiku abil peate standardiseerima pidevad muutujad ja teisendama kategoorilised muutujad. Torujuhtmes saab teha mis tahes toiminguid: puuduvad väärtused saab asendada keskmise või mediaaniga ja luua uusi muutujaid.
Teil on valida, kas panna kaks protsessi kõvakodeeringusse või luua torujuhe. Kõvakodeerimine võib lekkida testiandmeid sobitatud statistikasse ja tekitada aja jooksul vastuolusid, seega on torujuhe parem variant.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Enne logistilise klassifikaatori sisestamist teostab torujuhe kaks toimingut:
- Standardiseeri muutuja: StandardScaler()
- Teisenda kategoorilised funktsioonid: OneHotEncoder(sparse=False)
Mõlemad sammud sooritatakse funktsiooniga make_column_transformer. Selle juhendi kirjutamise ajal ei olnud seda funktsiooni scikit-learni avaldatud versioonis (0.19) veel, mistõttu kasutati arendaja versiooni; see on olnud kaasas igas stabiilses versioonis alates versioonist 0.20.
make_column_transformer on lihtne: deklareerid, milliseid veerge teisendada ja millist teisendust rakendada. Edastatavate pidevate tunnuste standardiseerimiseks:
- conti_features, StandardScaler() make_column_transformeri sees
- conti_features: pidevate veergude loend
- StandardScaler: standardiseerib need veerud
Make_column_transformer sees olev OneHotEncoder objekt kodeerib sildid automaatselt.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Versiooni märkus: Kaks argumenti ülaltoodud plokis on edasi liikunud. Praegused versioonid eeldavad, et trafo on esimene ja veerud on teine ning hõre nimetati ümber hõre_väljund scikit-learn 1.2-s ja eemaldatud versioonis 1.4, seega uuem kood loeb OneHotEncoder(hõre_väljund=Väär).
Konveieri toimimist saab testida funktsiooniga fit_transform. Väljund peaks olema kujul 26048, 107.
preprocess.fit_transform(X_train).shape
(26048, 107)
Andmete teisendaja on valmis. Loote torujuhtme käsuga make_pipeline ja kui andmed on teisendatud, sisestate need logistilisele regressioonile.
model = make_pipeline(
preprocess,
LogisticRegression())
Mudeli treenimine scikit-learniga on seega lihtne: kutsu torujuhtmel välja sobivus. Täpsuse saab välja printida meetodi score abil.
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Lõpuks saate klasse ennustada funktsiooniga predict_proba, mis tagastab iga klassi tõenäosuse. Pange tähele, et kahe tõenäosuse summa on üks.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
4. samm) Meie torujuhtme kasutamine ruudustikuotsingus
Hüperparameetrite ehk mudeli struktuuri fikseerivate väärtuste häälestamine võib olla tüütu ja kurnav.
Üks viis mudeli hindamiseks oleks muuta treeningkomplekti suurust ja mõõta tulemuslikkust, korrates harjutust kümme korda, et näha skoori hajuvust. See on palju käsitsi tööd.
Selle asemel pakub scikit-learn funktsioone, mis teostavad teie eest parameetrite häälestamist ja ristvalideerimist.
Ristvalideerimine
Ristvalideerimine tähendab, et treenimise ajal jagatakse treeningkomplekt n korda osadeks ja mudelit hinnatakse n korda. Kui cv on seatud väärtusele 10, treenitakse ja hinnatakse mudelit kümme korda. Igas voorus treenib klassifikaator üheksa juhuslikult valitud osaga ja kümnes osa jäetakse hindamiseks alles.
Võrgu otsing
Igal klassifikaatoril on hüperparameetrid, mida häälestada. Saate proovida väärtusi ükshaaval või määrata parameetrite ruudustiku. scikit-learni dokumentatsioon loetleb kõik parameetrid, mida logistiline klassifikaator aktsepteerib. Kiire treenimise tagamiseks häälestatakse selles näites ainult C-parameetrit, mis kontrollib regulariseerimist. See peab olema positiivne ja väike väärtus annab regulariseerijale suurema kaalu.
Kasutate GridSearchCV objekti, mis võtab häälestamiseks hüperparameetrite sõnastiku. Loetlege iga hüperparameeter ja seejärel väärtused, mida soovite proovida. C häälestamiseks kirjutate:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — parameetri nimele eelneb klassifikaatori nimi väiketähtedega ja kaks alakriipsu.
Mudel proovib nelja erinevat väärtust: 0.001, 0.01, 0.1 ja 1. Seda treenitakse 10 voldiga, st cv = 10.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
Nüüd saate mudelit treenida GridSearchCV abil parameetritega grid ja cv.
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
Väljund:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
Versiooni märkus: the,en iid Selles väljundis nähtav argument aegus scikit-learn versioonis 0.22 ja eemaldati versioonis 0.24, seega tuleks see praegustes versioonides GridSearchCV-kõnest lihtsalt eemaldada.
Parimatele parameetritele juurdepääsuks kasutate funktsiooni best_params_.
grid_clf.best_params_
Väljund:
{'logisticregression__C': 1.0}
Pärast mudeli treenimist nelja erineva regulariseerimisväärtusega annab optimaalne parameeter järgmise tulemuse:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
parim logistiline regressioon võrguotsingust: 0.850891
Prognoositud tõenäosustele juurdepääsemiseks toimige järgmiselt.
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
XGBoost mudel koos scikit-learniga
Proovige nüüd ühte turu tugevaimat klassifikaatorit. XGBoost on juhusliku metsa gradienti võimendav täiustus. Selle teoreetiline taust jääb käesoleva töö raamidest välja. Python Scikiti õpetus, aga pea meeles, et XGBoost on võitnud palju Kaggle'i võistlusi. Keskmise suurusega andmestikul võib see toimida sama hästi kui süvaõppe algoritm või isegi paremini.
Klassifikaatori treenimine on keeruline, kuna see pakub suurt hulka parameetreid. Muidugi saate nende valimiseks kasutada GridSearchCV-d.
Parem variant on siin RandomizedSearchCV. GridSearchCV muutub aeglaseks, kui ruudustik on suur, sest otsinguruum kasvab iga lisatud parameetriga. RandomizedSearchCV valib selle asemel iga hüperparameetri väärtused juhuslikult igal iteratsioonil, seega 1,000 iteratsiooni hindavad 1,000 kombinatsiooni. Muidu töötab see sarnaselt GridSearchCV-ga.
Peate importima xgboosti. Kui teeki pole installitud, käivitage käsk „pip3 install xgboost“ või installige see seestpoolt. Jupyter märkmik, millel on:
use import sys
!{sys.executable} -m pip install xgboost
Seejärel importige klassifikaator ja kaks otsingu abilist:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Järgmine samm selles Scikitis Python õpetus on häälestatavate parameetrite määramine. XGBoosti ametlik dokumentatsioon loetleb need kõik. Selle huvides Python Sklearni õpetuses valid ainult kaks hüperparameetrit, millel mõlemal on kaks väärtust, sest XGBoosti treenimine võtab kaua aega ja iga lisavõrgupunkt pikendab ooteaega.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Seejärel loote uue torujuhtme, kasutades XGBoost klassifikaatorit ja 600 hindajat. n_estimators on ise häälestatav ja kõrge väärtus võib viia üle sobitamiseni. Võite proovida ka teisi väärtusi, kuid pidage meeles, et see võib võtta tunde. Kõik teised parameetrid säilitavad oma vaikeväärtused.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Ristvalideerimist saab parandada Stratified K-Foldsi ristvalidaatoriga. Arvutuse kiirendamiseks kasutatakse siin ainult kolme voltimist, mis küll kvaliteedi arvelt langeb; paremate tulemuste saavutamiseks suurendage seda oma arvutis 5 või 10-ni. Mudelit treenitakse nelja iteratsiooni jooksul.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Juhuslik otsing on valmis, seega saate mudelit treenida.
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Nagu näete, on XGBoost tulemus varasem logistiline regressioon parem.
print("Best parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Looge scikit-learnis MLPClassifieriga DNN
Lõpuks saate närvivõrku treenida scikit-learni enda abil. Meetod on sama mis iga teise klassifikaatori puhul ja hindaja on MLPClassifier.
from sklearn.neural_network import MLPClassifier
Allolev võrk on defineeritud järgmiselt:
- Aadama lahendaja
- ReLU aktiveerimisfunktsioon
- Alfa = 0.0001
- Partii suurus 150
- Kaks peidetud kihti vastavalt 200 ja 100 neuroniga
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Mudeli täiustamiseks saate muuta kihtide arvu.
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN-i regressiooniskoor: 0.821253
LIME: usaldage oma mudelit
Nüüd, kui teil on hea mudel, vajate viisi selle usaldamiseks. Masinõppe algoritme, eriti juhuslikke metsi ja närvivõrke, tuntakse musta kasti mudelitena: need töötavad, aga keegi ei saa aru, miks.
Kolm teadlast ehitasid tööriista, mis näitab, kuidas arvuti ennustuseni jõuab. Nende artikkel on "Miks ma peaksin sind usaldama?"ja nende avaldatud algoritmi nimetatakse lokaalselt tõlgendatavateks mudelagnostilistest selgitusteks (LIME).
Võtame näiteks. Mõnikord ei tea sa, kas masinõppe ennustust saab usaldada. Arst ei saa diagnoosi aktsepteerida ainult sellepärast, et selle pani arvuti, ja enne mudeli tootmisse võtmist pead teadma, kas see on usaldusväärne.
Kujutage ette, et suudate näha, miks mõni klassifikaator ennustuse tegi, isegi nii keeruliste mudelite puhul nagu närvivõrgud, juhuslikud metsad või suvalise kerneliga SVM-id. Ennustuse usaldamine muutub palju lihtsamaks, kui selle taga olevad põhjused on nähtavad, ja sama lihtne on otsustada, millal mudelit ei tohiks usaldada. LIME ütleb teile, millised omadused ajendasid klassifikaatori otsust.
Andmete ettevalmistamine
LIME'i käivitamiseks on vaja muuta paari asja. PythonEsmalt paigalda terminali lime käsuga "pip install lime".
Lime kasutab mudeli lokaalseks ligikaudseks arvutamiseks LimeTabularExplainer objekti. See objekt nõuab:
- andmestik tuim formaat
- Funktsioonide nimi: funktsioonide_nimed
- Klasside nimed: klassi_nimed
- Kategooriliste tunnuste veeru indeks: categorical_features
- Iga kategoorilise tunnuse rühma nimi: categorical_names
Loo NumPy rongikomplekt
Saate df_train'i pandadest NumPy-ks väga lihtsalt kopeerida ja teisendada.
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
Hankige klassi nimi
Sildile pääseb ligi funktsiooni unique() kaudu. Peaksite nägema järgmist:
- '<=50 XNUMX'
- '>50 XNUMX'
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
Kategooriliste tunnuste veergude indekseerimine
Kasuta iga rühma nime saamiseks varem õpitud meetodit. Kodeeri silt LabelEncoderiga ja korda toimingut iga kategoorilise tunnuse puhul.
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Nüüd, kui andmestik on valmis, saate luua allpool Scikiti õppenäidetes näidatud erinevad andmestikud. Andmed teisendatakse siin väljaspool torujuhet, et vältida vigu LIME-iga: LimeTabularExplainerile edastatav treeningkomplekt peab olema stringideta NumPy massiiv ja ülaltoodud meetod on selle juba loonud.
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
Saate luua torujuhtme XGBoosti leitud optimaalsete parameetritega.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
Saate hoiatuse. See selgitab, et te ei pea enne konveierit sildikoodrit looma. Kui te ei kasuta LIME-i, sobib selle Scikit-learni masinõppe õpetuse esimeses osas kirjeldatud meetod. Vastasel juhul kasutage seda lähenemisviisi: looge kõigepealt kodeeritud andmestik ja seejärel rakendage konveieri sees ühekordset kodeerijat.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Enne LIME'i töölepanekut loo NumPy massiiv, mis sisaldab valesti klassifitseeritud ridade tunnuseid. Seda nimekirja saad hiljem kasutada, et saada aimu, mis klassifikaatorit eksiteele viis.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
Seejärel loote lambda-funktsiooni, mis hangib mudelist uute andmete ennustuse. Seda läheb teil varsti vaja.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Sa teisendad pandade andmeraami NumPy massiiviks.
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
Nüüd vali testkomplektist juhuslik leibkond ja vaata nii ennustust kui ka seda, kuidas arvuti selleni jõudis.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Mudeli taga oleva arutluskäigu uurimiseks saate kasutada selgitajat koos explain_instance'iga. Selle kuvatav diagramm on näidatud allpool.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klassifikaator ennustas selle leibkonna kohta õigesti: sissetulek on tõepoolest üle 50 000.
Esimene asi, mida märkida, on see, et klassifikaator pole endas eriti kindel. See ennustab sissetulekut üle 50 000 64% tõenäosusega ning see 64% sõltub kapitalikasvust ja perekonnaseisust. Sinine värv annab positiivsele klassile negatiivse panuse ja oranž joon positiivse panuse.
Klassifikaator kõhkleb, kuna selle leibkonna kapitalikasv on null, samas kui kapitalikasv on tavaliselt hea rikkuse ennustaja. Samuti töötab leibkond vähem kui 40 tundi nädalas. Vanus, amet ja sugu mõjutavad kõik positiivselt.
Kui perekonnaseis oleks vallaline, oleks klassifikaator ennustanud sissetulekut alla 50 000 (0.64 – 0.18 = 0.46).
Nüüd proovige teist leibkonda, sellist, mis klassifitseeriti valesti. Selle selgitav tabel järgneb koodile.
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klassifikaator ennustas sissetulekuks alla 50 000, mis on vale. See leibkond on ebatavaline: sellel ei ole ei kapitalikasumit ega kapitalikahjumit, inimene on lahutatud, umbes 60-aastane ja haritud, st haridusnumber > 12. Järgides üldist mustrit, paigutas klassifikaator leibkonna alla 50 000.
Mängi LIME-iga ise ja märkad klassifikaatoris palju nürisid vigu. Teegi autori GitHubi repositooriumis on piltide ja teksti klassifitseerimise kohta lisadokumentatsiooni.
Scikit-learni käskude juhend
Allpool on loend kasulikest käskudest, mis kehtivad scikit-learni versioonile 0.20 ja uuematele.
| Ülesanne | Funktsioon või klass |
|---|---|
| Loo rongi/testi andmestik | train_test_split |
| Ehitage torujuhe | |
| Valige veerud ja rakendage teisendus | veeru_transformaatori loomine |
| Ümberkujundamise tüüp | |
| Standardiseeri | StandardScaler |
| Min-max skaleerimine | MinMaxScaler |
| Normaliseeri | Normalisaator |
| Puuduvate väärtuste sisestamine | Lihtne sisestaja |
| Teisenda kategooriliseks | OneHotEncoder |
| Andmete sobitamine ja teisendamine | sobi_teisendus |
| Tehke torujuhe | make_pipeline |
| Põhimudel | |
| Logistiline regressioon | Logistiline regressioon |
| XGBoost | XGB klassifikaator |
| Närvivõrk | MLPC klassifikaator |
| Võrgu otsing | GridSearchCV |
| Juhuslik otsing | Juhuslik otsing CV |