GLM en R: Modelo lineal generalizado y regresión logística
⚡ Resumen inteligente
El modelo lineal generalizado (GLM) en R extiende la regresión convencional a resultados binarios, basados en recuentos o con distribuciones no normales. Este tutorial construye un GLM logístico con el conjunto de datos de ingresos de adultos y lo evalúa en términos de exactitud, precisión, exhaustividad y curva ROC.

¿Qué es un modelo lineal generalizado (GLM) en R?
A Modelo lineal generalizado (GLM) Extiende la regresión lineal ordinaria para que la variable de respuesta pueda seguir una distribución distinta a la normal. R, usted instala uno con el incorporado glm() función del paquete stats.
Cada GLM se define por tres componentes:
- Componente aleatorio: la distribución de probabilidad de la variable de respuesta, tomada de la familia exponencial (binomial, Poisson, Gamma, Gaussiana y otras).
- Componente sistemático: El predictor lineal es la combinación ponderada de sus variables explicativas.
- Función de enlace: la función que conecta la media de la respuesta con el predictor lineal, por ejemplo, el enlace logit para datos binarios o el enlace log para recuentos.
Esa estructura es lo que hace que el modelo sea “generalizado”. En lugar de forzar un resultado con distribución normal, se declara la distribución correcta a través de la . El argumento y R estiman los coeficientes por máxima verosimilitud. La regresión logística es simplemente un GLM con una familia binomial y una función de enlace logit, por lo que es el punto de partida natural.
¿Qué es la regresión logística en R?
La regresión logística se utiliza para predecir una clase, es decir, una probabilidad. La regresión logística puede predecir con precisión un resultado binario.
Imagine que desea predecir si se deniega o acepta un préstamo en función de muchos atributos. La regresión logística es de la forma 0/1. y = 0 si se rechaza un préstamo, y = 1 si se acepta.
Un modelo de regresión logística se diferencia del modelo de regresión lineal en dos formas.
- En primer lugar, la regresión logística acepta sólo datos dicotómicos (binarios) como variable dependiente (es decir, un vector de 0 y 1).
- En segundo lugar, el resultado se representa mediante una función de enlace probabilística llamada sigmoideo función (logística) debido a su forma de S:

La salida de la función siempre está entre 0 y 1. Consulte la imagen a continuación
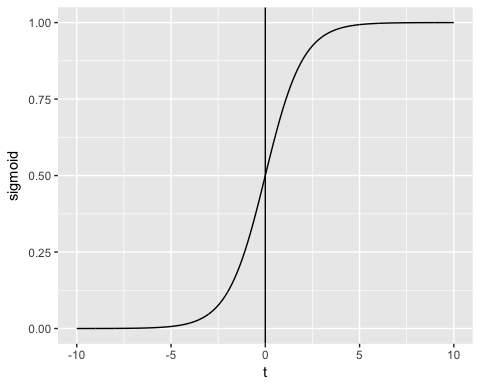
La función sigmoidea devuelve valores de 0 a 1. Para la tarea de clasificación, necesitamos una salida discreta de 0 o 1.
Para convertir un flujo continuo en un valor discreto, podemos establecer un límite de decisión en 0.5. Todos los valores por encima de este umbral se clasifican como 1

Ahora que la función de enlace está clara, compare el modelo generalizado con el modelo lineal ordinario que ya conoce.
GLM frente a regresión lineal: diferencias clave en R
Antes de escribir cualquier código, es útil saber exactamente cuándo el estándar regresión lineal La función lm() ya no es apropiada y glm() debería ocupar su lugar.
| Criterios | Regresión lineal (lm) | Modelo lineal generalizado (glm) |
|---|---|---|
| variable de respuesta | Continuo e ilimitado | Binario, de conteo, de proporción o continuo positivo |
| Distribución de errores | Normal solamente | Cualquier miembro de la familia exponencial |
| Función de enlace | Identidad (implícita) | Explícito: logit, log, inverso, probit |
| Método de estimación | Mínimos cuadrados ordinarios | Máxima verosimilitud (IRLS) |
| Supuesto de varianza | Constante en todas las observaciones | Permitido depender de la media |
| Medida de bondad de ajuste | R-cuadrado | AIC y desviación residual |
| Función R | lm(fórmula, datos) | glm(fórmula, datos, familia) |
En resumen, elija lm() cuando el resultado sea una medición con distribución normal y glm() siempre que el resultado sea una decisión de sí/no, una tarea que de otro modo podría delegar a un árbol de decisión clasificador, un recuento de eventos o una cantidad estrictamente positiva cuya dispersión crece con su media.
Cómo crear un modelo lineal generalizado (GLM) en R
Una vez establecida la teoría, el resto de este tutorial aplica un modelo lineal generalizado binomial de principio a fin a un conjunto de datos reales.
Usemos el adulto Conjunto de datos para ilustrar la regresión logística. El conjunto de datos "adulto" es ideal para la tarea de clasificación. El objetivo es predecir si el ingreso anual de una persona en dólares estadounidenses superará los 50 000. El conjunto de datos contiene 48 842 observaciones y diez variables:
- edad: edad del individuo. Numérico
- educación: Nivel educativo del individuo. Factor.
- Estado civil: Mariestatus tal del individuo. Factor, es decir, nunca casado, casado-cónyuge civil,…
- género: Género del individuo. Factor, es decir, masculino o femenino
- ingreso: Target variable. Ingresos superiores o inferiores a 50K. Factor, es decir >50K, <=50K
Entre otros
library(dplyr) data_adult <-read.csv("https://raw.githubusercontent.com/guru99-edu/R-Programming/master/adult.csv") glimpse(data_adult)
Salida:
Observations: 48,842 Variables: 10 $ x <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,... $ age <int> 25, 38, 28, 44, 18, 34, 29, 63, 24, 55, 65, 36, 26... $ workclass <fctr> Private, Private, Local-gov, Private, ?, Private,... $ education <fctr> 11th, HS-grad, Assoc-acdm, Some-college, Some-col... $ educational.num <int> 7, 9, 12, 10, 10, 6, 9, 15, 10, 4, 9, 13, 9, 9, 9,... $ marital.status <fctr> Never-married, Married-civ-spouse, Married-civ-sp... $ race <fctr> Black, White, White, Black, White, White, Black, ... $ gender <fctr> Male, Male, Male, Male, Female, Male, Male, Male,... $ hours.per.week <int> 40, 50, 40, 40, 30, 30, 40, 32, 40, 10, 40, 40, 39... $ income <fctr> <=50K, <=50K, >50K, >50K, <=50K, <=50K, <=50K, >5...
Procederemos de la siguiente manera:
- Paso 1: Verifique las variables continuas
- Paso 2: verificar las variables de los factores
- Paso 3: ingeniería de funciones
- Paso 4: resumen estadístico
- Paso 5: Conjunto de entrenamiento/prueba
- Paso 6: construye el modelo
- Paso 7: evaluar el rendimiento del modelo
- Paso 8: mejorar el modelo
Su tarea es predecir qué individuo tendrá unos ingresos superiores a 50.
En este tutorial, se detallará cada paso para realizar un análisis en un conjunto de datos real.
Paso 1) Verificar variables continuas
En el primer paso, puedes ver la distribución de las variables continuas.
continuous <-select_if(data_adult, is.numeric) summary(continuous)
Code Explicación
- continuo <- select_if(data_adult, is.numeric): use la función select_if() de la biblioteca dplyr para seleccionar solo las columnas numéricas
- resumen (continuo): imprime la estadística resumida
Salida:
## X age educational.num hours.per.week ## Min. : 1 Min. :17.00 Min. : 1.00 Min. : 1.00 ## 1st Qu.:11509 1st Qu.:28.00 1st Qu.: 9.00 1st Qu.:40.00 ## Median :23017 Median :37.00 Median :10.00 Median :40.00 ## Mean :23017 Mean :38.56 Mean :10.13 Mean :40.95 ## 3rd Qu.:34525 3rd Qu.:47.00 3rd Qu.:13.00 3rd Qu.:45.00 ## Max. :46033 Max. :90.00 Max. :16.00 Max. :99.00
De la tabla anterior, se puede ver que los datos tienen escalas totalmente diferentes y hours.per.weeks tiene valores atípicos grandes (es decir, observe el último cuartil y el valor máximo).
Puedes solucionarlo siguiendo dos pasos:
- Representa gráficamente la distribución de horas por semana.
- Estandarizar las variables continuas.
- Trazar la distribución
Veamos más de cerca la distribución de horas por semana.
# Histogram with kernel density curve library(ggplot2) ggplot(continuous, aes(x = hours.per.week)) + geom_density(alpha = .2, fill = "#FF6666")
Salida:

La variable tiene muchos valores atípicos y una distribución no bien definida. Puedes solucionar parcialmente este problema eliminando el 0.01 por ciento superior de las horas por semana.
Sintaxis básica de cuantil:
quantile(variable, percentile) arguments: -variable: Select the variable in the data frame to compute the percentile -percentile: Can be a single value between 0 and 1 or multiple value. If multiple, use this format: `c(A,B,C, ...) - `A`,`B`,`C` and `...` are all integer from 0 to 1.
Calculamos el percentil 99 de las horas de trabajo semanales.
top_one_percent <- quantile(data_adult$hours.per.week, .99)
top_one_percent
Code Explicación
- quantile(data_adult$hours.per.week, .99): Calcula el percentil 99 del tiempo de trabajo semanal.
Salida:
## 99% ## 80
El 99 por ciento de la población trabaja menos de 80 horas semanales.
Puede dejar las observaciones por encima de este umbral. Usas el filtro del dplyr biblioteca.
data_adult_drop <-data_adult %>% filter(hours.per.week<top_one_percent) dim(data_adult_drop)
Salida:
## [1] 45537 10
- Estandarizar las variables continuas.
Puedes estandarizar cada columna para mejorar el rendimiento porque tus datos no tienen la misma escala. Puede utilizar la función mutate_if de la biblioteca dplyr. La sintaxis básica es:
mutate_if(df, condition, funs(function)) arguments: -`df`: Data frame used to compute the function - `condition`: Statement used. Do not use parenthesis - funs(function): Return the function to apply. Do not use parenthesis for the function
Puede estandarizar las columnas numéricas de la siguiente manera:
data_adult_rescale <- data_adult_drop %>% mutate_if(is.numeric, funs(as.numeric(scale(.)))) head(data_adult_rescale)
Code Explicación
- mutate_if(is.numeric, funs(scale)): la condición es solo una columna numérica y la función es escala
Salida:
## X age workclass education educational.num ## 1 -1.732680 -1.02325949 Private 11th -1.22106443 ## 2 -1.732605 -0.03969284 Private HS-grad -0.43998868 ## 3 -1.732530 -0.79628257 Local-gov Assoc-acdm 0.73162494 ## 4 -1.732455 0.41426100 Private Some-college -0.04945081 ## 5 -1.732379 -0.34232873 Private 10th -1.61160231 ## 6 -1.732304 1.85178149 Self-emp-not-inc Prof-school 1.90323857 ## marital.status race gender hours.per.week income ## 1 Never-married Black Male -0.03995944 <=50K ## 2 Married-civ-spouse White Male 0.86863037 <=50K ## 3 Married-civ-spouse White Male -0.03995944 >50K ## 4 Married-civ-spouse Black Male -0.03995944 >50K ## 5 Never-married White Male -0.94854924 <=50K ## 6 Married-civ-spouse White Male -0.76683128 >50K
Paso 2) Verificar las variables de los factores
Este paso tiene dos objetivos:
- Consulta el nivel en cada columna categórica.
- Definir nuevos niveles
Dividiremos este paso en tres partes:
- Seleccione las columnas categóricas
- Almacene el gráfico de barras de cada columna en una lista
- imprimir los gráficos
Podemos seleccionar las columnas de factores con el siguiente código:
# Select categorical column factor <- data.frame(select_if(data_adult_rescale, is.factor)) ncol(factor)
Code Explicación
- data.frame(select_if(data_adult, is.factor)): almacenamos las columnas de factores en factor en un tipo de marco de datos. La biblioteca ggplot2 requiere un objeto de marco de datos.
Salida:
## [1] 6
El conjunto de datos contiene 6 variables categóricas.
El segundo paso es más exigente. Consiste en crear un gráfico de barras para cada columna del marco de datos factor. Es más conveniente automatizar el proceso, sobre todo cuando hay muchas columnas.
library(ggplot2) # Create graph for each column graph <- lapply(names(factor), function(x) ggplot(factor, aes(get(x))) + geom_bar() + theme(axis.text.x = element_text(angle = 90)))
Code Explicación
- lapply(): Utilice la función lapply() para pasar una función en todas las columnas del conjunto de datos. Almacenas la salida en una lista.
- función(x): La función se procesará para cada x. Aquí x son las columnas.
- ggplot(factor, aes(get(x))) + geom_bar()+ theme(axis.text.x = element_text(angle = 90)): crea un gráfico de caracteres de barras para cada elemento x. Tenga en cuenta que para devolver x como columna, debe incluirla dentro de get()
El último paso es relativamente fácil. Quieres imprimir los 6 gráficos.
# Print the graph
graph
Salida:
## [[1]]

## ## [[2]]

## ## [[3]]

## ## [[4]]

## ## [[5]]

## ## [[6]]

Nota: Utilice el botón siguiente para navegar al siguiente gráfico.

Paso 3) Ingeniería de funciones
Dos variables categóricas tienen más niveles de los que necesita el modelo. Deberás reagruparlas en categorías más amplias y mejor definidas.
Educación refundida
En el gráfico anterior se puede ver que la variable educación tiene 16 niveles. Esto es sustancial y algunos niveles tienen un número relativamente bajo de observaciones. Si desea mejorar la cantidad de información que puede obtener de esta variable, puede reformularla a un nivel superior. Es decir, creas grupos más grandes con un nivel de educación similar. Por ejemplo, un bajo nivel de educación se convertirá en abandono escolar. Los niveles superiores de educación se cambiarán a maestría.
Aquí está el detalle:
| Antiguo nivel | Nuevo nivel |
|---|---|
| Preescolar | Dropout |
| 10 | Punteras |
| 11 | Punteras |
| 12 | Punteras |
| 1st-4th | Punteras |
| 5mo-6vo | Punteras |
| 7mo-8vo | Punteras |
| 9 | Punteras |
| Graduado HS | alto grado |
| Alguna educación superior | Comunidad |
| asoc-acdm | Comunidad |
| Voc-Asociado | Comunidad |
| Solteros | Solteros |
| Masters | Masters |
| escuela profesional | Masters |
| Doctorado | Doctorado |
recast_data <- data_adult_rescale %>% select(-X) %>% mutate(education = factor(ifelse(education == "Preschool" | education == "10th" | education == "11th" | education == "12th" | education == "1st-4th" | education == "5th-6th" | education == "7th-8th" | education == "9th", "dropout", ifelse(education == "HS-grad", "HighGrad", ifelse(education == "Some-college" | education == "Assoc-acdm" | education == "Assoc-voc", "Community", ifelse(education == "Bachelors", "Bachelors", ifelse(education == "Masters" | education == "Prof-school", "Master", "PhD")))))))
Code Explicación
- Usamos el verbo mutar de la biblioteca dplyr. Cambiamos los valores de la educación con la afirmación ifelse
En la siguiente tabla, crea una estadística resumida para ver, en promedio, cuántos años de educación (valor z) se necesitan para alcanzar la licenciatura, la maestría o el doctorado.
recast_data %>% group_by(education) %>% summarize(average_educ_year = mean(educational.num), count = n()) %>% arrange(average_educ_year)
Salida:
## # A tibble: 6 x 3 ## education average_educ_year count ## <fctr> <dbl> <int> ## 1 dropout -1.76147258 5712 ## 2 HighGrad -0.43998868 14803 ## 3 Community 0.09561361 13407 ## 4 Bachelors 1.12216282 7720 ## 5 Master 1.60337381 3338 ## 6 PhD 2.29377644 557
Nuevo reparto de papeles Mariestado-tal
También es posible crear niveles inferiores para el estado civil. En el código siguiente, cambia el nivel de la siguiente manera:
| Antiguo nivel | Nuevo nivel |
|---|---|
| Nunca casado | No casado |
| cónyuge-casado-ausente | No casado |
| Cónyuge-AF-casado | Casado |
| Cónyuge-civil-casado | |
| Separado | Separado |
| Divorciado | |
| Viudas | Viuda |
# Change level marry recast_data <- recast_data %>% mutate(marital.status = factor(ifelse(marital.status == "Never-married" | marital.status == "Married-spouse-absent", "Not_married", ifelse(marital.status == "Married-AF-spouse" | marital.status == "Married-civ-spouse", "Married", ifelse(marital.status == "Separated" | marital.status == "Divorced", "Separated", "Widow")))))
Puede consultar el número de personas dentro de cada grupo.
table(recast_data$marital.status)
Salida:
## ## Married Not_married Separated Widow ## 21165 15359 7727 1286
Paso 4) Estadística resumida
Es hora de comprobar algunas estadísticas sobre nuestras variables objetivo. En el siguiente gráfico, se cuenta el porcentaje de personas que ganan más de 50 XNUMX según su género.
# Plot gender income ggplot(recast_data, aes(x = gender, fill = income)) + geom_bar(position = "fill") + theme_classic()
Salida:

A continuación, verifique si el origen del individuo afecta sus ingresos.
# Plot origin income ggplot(recast_data, aes(x = race, fill = income)) + geom_bar(position = "fill") + theme_classic() + theme(axis.text.x = element_text(angle = 90))
Salida:
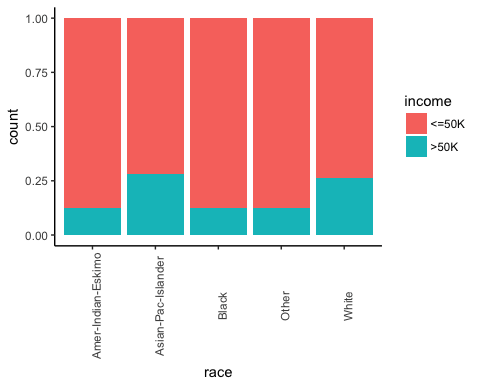
Número de horas trabajadas por género.
# box plot gender working time ggplot(recast_data, aes(x = gender, y = hours.per.week)) + geom_boxplot() + stat_summary(fun.y = mean, geom = "point", size = 3, color = "steelblue") + theme_classic()
Salida:

El diagrama de caja confirma que la distribución del tiempo de trabajo se ajusta a diferentes grupos. En el diagrama de caja, ambos géneros no tienen observaciones homogéneas.
Puedes comprobar la densidad del tiempo de trabajo semanal por tipo de educación. Las distribuciones tienen muchos picos distintos. Probablemente se pueda explicar por el tipo de contract en los EE. UU.
# Plot distribution working time by education ggplot(recast_data, aes(x = hours.per.week)) + geom_density(aes(color = education), alpha = 0.5) + theme_classic()
Code Explicación
- ggplot(recast_data, aes( x= hours.per.week)): Un gráfico de densidad solo requiere una variable
- geom_density(aes(color = educación), alfa =0.5): El objeto geométrico para controlar la densidad
Salida:

Para confirmar sus pensamientos, puede realizar una prueba unidireccional. Prueba ANOVA:
anova <- aov(hours.per.week~education, recast_data) summary(anova)
Salida:
## Df Sum Sq Mean Sq F value Pr(>F) ## education 5 1552 310.31 321.2 <2e-16 *** ## Residuals 45531 43984 0.97 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
La prueba ANOVA confirma la diferencia de promedios entre los grupos.
No linealidad
Antes de ejecutar el modelo, puedes ver si el número de horas trabajadas está relacionado con la edad.
library(ggplot2) ggplot(recast_data, aes(x = age, y = hours.per.week)) + geom_point(aes(color = income), size = 0.5) + stat_smooth(method = 'lm', formula = y~poly(x, 2), se = TRUE, aes(color = income)) + theme_classic()
Code Explicación
- ggplot(recast_data, aes(x = age, y = hours.per.week)): establece la estética del gráfico
- geom_point(aes(color= ingresos), tamaño =0.5): construye el diagrama de puntos
- stat_smooth(): agrega la línea de tendencia con los siguientes argumentos:
- método = 'lm': Traza el valor ajustado si el regresión lineal
- fórmula = y~poly(x,2): Ajustar una regresión polinómica
- se = VERDADERO: Agrega el error estándar
- aes(color= ingresos): divide el modelo por ingresos
Salida:

En pocas palabras, puede probar los términos de interacción en el modelo para detectar el efecto de no linealidad entre el tiempo de trabajo semanal y otras características. Es importante detectar en qué condiciones difiere el tiempo de trabajo.
La correlación
La siguiente comprobación es visualizar la correlación entre las variables. El tipo de nivel de factor se convierte en numérico para poder trazar un mapa de calor que contenga el coeficiente de correlación calculado con el método de Spearman.
library(GGally) # Convert data to numeric corr <- data.frame(lapply(recast_data, as.integer)) # Plot the graphggcorr(corr, method = c("pairwise", "spearman"), nbreaks = 6, hjust = 0.8, label = TRUE, label_size = 3, color = "grey50")
Code Explicación
- data.frame(lapply(recast_data,as.integer)): convierte datos a numéricos
- ggcorr() traza el mapa de calor con los siguientes argumentos:
- método: Método para calcular la correlación
- nbreaks = 6: Número de descansos
- hjust = 0.8: posición de control del nombre de la variable en el gráfico
- etiqueta = VERDADERO: Agrega etiquetas en el centro de las ventanas
- label_size = 3: etiquetas de tamaño
- color = “grey50”): Color de la etiqueta
Salida:
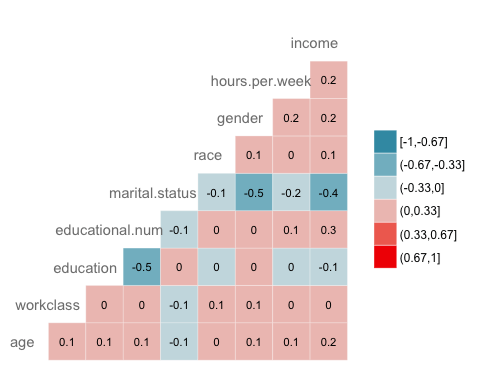
Paso 5) Conjunto de entrenamiento/prueba
Cualquier supervisado aprendizaje automático Esta tarea requiere que dividas los datos entre un conjunto de entrenamiento y un conjunto de prueba. Puedes usar la función que creaste en los otros tutoriales de aprendizaje supervisado para crear un conjunto de entrenamiento/prueba.
set.seed(1234) create_train_test <- function(data, size = 0.8, train = TRUE) { n_row = nrow(data) total_row = size * n_row train_sample <- 1: total_row if (train == TRUE) { return (data[train_sample, ]) } else { return (data[-train_sample, ]) } } data_train <- create_train_test(recast_data, 0.8, train = TRUE) data_test <- create_train_test(recast_data, 0.8, train = FALSE) dim(data_train)
Salida:
## [1] 36429 9
dim(data_test)
Salida:
## [1] 9108 9
Paso 6) Construye el modelo
Para ver cómo se desempeña el algoritmo, se utiliza la función glm() del paquete stats. Modelo lineal generalizado es una colección de modelos. La sintaxis básica es:
glm(formula, data=data, family=linkfunction() Argument: - formula: Equation used to fit the model- data: dataset used - Family: - binomial: (link = "logit") - gaussian: (link = "identity") - Gamma: (link = "inverse") - inverse.gaussian: (link = "1/mu^2") - poisson: (link = "log") - quasi: (link = "identity", variance = "constant") - quasibinomial: (link = "logit") - quasipoisson: (link = "log")
Está listo para estimar el modelo logístico para dividir el nivel de ingresos entre un conjunto de características.
formula <- income~. logit <- glm(formula, data = data_train, family = 'binomial') summary(logit)
Code Explicación
- fórmula <- ingresos ~.: Crea el modelo para que se ajuste
- logit <- glm(fórmula, datos = data_train, familia = 'binomial'): ajusta un modelo logístico (familia = 'binomial') con los datos de data_train.
- resumen (logit): imprime el resumen del modelo
Salida:
## ## Call: ## glm(formula = formula, family = "binomial", data = data_train) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -2.6456 -0.5858 -0.2609 -0.0651 3.1982 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|) ## (Intercept) 0.07882 0.21726 0.363 0.71675 ## age 0.41119 0.01857 22.146 < 2e-16 *** ## workclassLocal-gov -0.64018 0.09396 -6.813 9.54e-12 *** ## workclassPrivate -0.53542 0.07886 -6.789 1.13e-11 *** ## workclassSelf-emp-inc -0.07733 0.10350 -0.747 0.45499 ## workclassSelf-emp-not-inc -1.09052 0.09140 -11.931 < 2e-16 *** ## workclassState-gov -0.80562 0.10617 -7.588 3.25e-14 *** ## workclassWithout-pay -1.09765 0.86787 -1.265 0.20596 ## educationCommunity -0.44436 0.08267 -5.375 7.66e-08 *** ## educationHighGrad -0.67613 0.11827 -5.717 1.08e-08 *** ## educationMaster 0.35651 0.06780 5.258 1.46e-07 *** ## educationPhD 0.46995 0.15772 2.980 0.00289 ** ## educationdropout -1.04974 0.21280 -4.933 8.10e-07 *** ## educational.num 0.56908 0.07063 8.057 7.84e-16 *** ## marital.statusNot_married -2.50346 0.05113 -48.966 < 2e-16 *** ## marital.statusSeparated -2.16177 0.05425 -39.846 < 2e-16 *** ## marital.statusWidow -2.22707 0.12522 -17.785 < 2e-16 *** ## raceAsian-Pac-Islander 0.08359 0.20344 0.411 0.68117 ## raceBlack 0.07188 0.19330 0.372 0.71001 ## raceOther 0.01370 0.27695 0.049 0.96054 ## raceWhite 0.34830 0.18441 1.889 0.05894 . ## genderMale 0.08596 0.04289 2.004 0.04506 * ## hours.per.week 0.41942 0.01748 23.998 < 2e-16 *** ## ---## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## (Dispersion parameter for binomial family taken to be 1) ## ## Null deviance: 40601 on 36428 degrees of freedom ## Residual deviance: 27041 on 36406 degrees of freedom ## AIC: 27087 ## ## Number of Fisher Scoring iterations: 6
El resumen de nuestro modelo revela información interesante. El rendimiento de una regresión logística se evalúa con métricas clave específicas.
- AIC (Criterios de información de Akaike): Es el equivalente a R2 en regresión logística. Mide el ajuste cuando se aplica una penalización al número de parámetros. Menor AIC Los valores indican que el modelo está más cerca de la verdad.
- Desviación nula: se ajusta al modelo solo con la intersección. El grado de libertad es n-1. Podemos interpretarlo como un valor de Chi-cuadrado (valor ajustado diferente del valor real de la prueba de hipótesis).
- Desviación Residual: Modelo con todas las variables. También se interpreta como una prueba de hipótesis de Chi-cuadrado.
- Número de iteraciones de Fisher Scoring: número de iteraciones antes de converger.
La salida de la función glm() se almacena en una lista. El siguiente código muestra todos los elementos disponibles en la variable logit que construimos para evaluar la regresión logística.
# La lista es muy larga, imprime solo los primeros tres elementos
lapply(logit, class)[1:3]
Salida:
## $coefficients ## [1] "numeric" ## ## $residuals ## [1] "numeric" ## ## $fitted.values ## [1] "numeric"
Cada valor puede ser extraccon el signo $ seguido del nombre de las métricas. Por ejemplo, almacenaste el modelo como logit. Para extracEn los criterios AIC, se utiliza:
logit$aic
Salida:
## [1] 27086.65
Paso 7) Evaluar el desempeño del modelo.
Matriz de confusión
El matriz de confusión es una mejor opción para evaluar el rendimiento de la clasificación en comparación con las diferentes métricas que vio antes. La idea general es contar el número de veces que las instancias Verdaderas se clasifican como Falsas.

Para calcular la matriz de confusión, primero es necesario tener un conjunto de predicciones para poder compararlas con los objetivos reales.
predict <- predict(logit, data_test, type = 'response') # confusion matrix table_mat <- table(data_test$income, predict > 0.5) table_mat
Code Explicación
- predict(logit,data_test, type = 'response'): calcula la predicción en el conjunto de prueba. Establezca tipo = 'respuesta' para calcular la probabilidad de respuesta.
- tabla(data_test$ingresos, predecir > 0.5): Calcula la matriz de confusión. predecir > 0.5 significa que devuelve 1 si las probabilidades predichas son superiores a 0.5; en caso contrario, 0.
Salida:
## ## FALSE TRUE ## <=50K 6310 495 ## >50K 1074 1229
Cada fila de una matriz de confusión representa un objetivo real, mientras que cada columna representa un objetivo predicho. La primera fila de esta matriz considera los ingresos inferiores a 50k (la clase negativa): 6,310 observaciones se clasificaron correctamente como individuos con ingresos inferiores a 50k (Verdadero-negativo), mientras que 495 fueron clasificados erróneamente como superiores a 50k (Falso positivo). La segunda fila considera los ingresos superiores a 50: 1,229 fueron identificados correctamente (Verdadero positivo), mientras que 1,074 quedaron sin registrar (Falso negativo).
Puedes calcular el modelo. la exactitud sumando el verdadero positivo + el verdadero negativo sobre la observación total

accuracy_Test <- sum(diag(table_mat)) / sum(table_mat) accuracy_Test
Code Explicación
- sum(diag(table_mat)): Suma de la diagonal
- sum(table_mat): Suma de la matriz.
Salida:
## [1] 0.8277339
El modelo parece sufrir un problema: produce demasiados falsos negativos. Esto se llama paradoja de la prueba de precisiónAfirmamos que la precisión es la proporción de predicciones correctas respecto al número total de casos. Podemos tener una precisión relativamente alta, pero un modelo inútil. Esto ocurre cuando hay una clase dominante. Si revisamos la matriz de confusión, podemos ver que la mayoría de los casos se clasifican como verdaderos negativos. Imaginemos ahora que el modelo clasificara cada observación como negativa (es decir, inferior a 50). Aun así, obtendríamos una precisión de aproximadamente el 75 % (6,805 / 9,108). Nuestro modelo funciona mejor, pero tiene dificultades para distinguir los verdaderos positivos de los verdaderos negativos.
En tal situación, es preferible tener una métrica más concisa. Podemos mirar:
- Precisión=TP/(TP+FP)
- Recuperar=TP/(TP+FN)
Precisión vs recuperación
Precisión analiza la precisión de la predicción positiva. Recordar es la proporción de instancias positivas que el clasificador detecta correctamente;
Puedes construir dos funciones para calcular estas dos métricas.
- Precisión de construcción
precision <- function(matrix) { # True positive tp <- matrix[2, 2] # false positive fp <- matrix[1, 2] return (tp / (tp + fp)) }
Code Explicación
- mat[1,1]: Devuelve la primera celda de la primera columna del marco de datos, es decir, el verdadero positivo
- estera[1,2]; Devuelve la primera celda de la segunda columna del marco de datos, es decir, el falso positivo.
recall <- function(matrix) { # true positive tp <- matrix[2, 2]# false positive fn <- matrix[2, 1] return (tp / (tp + fn)) }
Code Explicación
- mat[1,1]: Devuelve la primera celda de la primera columna del marco de datos, es decir, el verdadero positivo
- estera[2,1]; Devuelve la segunda celda de la primera columna del marco de datos, es decir, el falso negativo.
Puedes probar tus funciones.
prec <- precision(table_mat) prec rec <- recall(table_mat) rec
Salida:
## [1] 0.712877 ## [2] 0.5336518
Lea atentamente estas dos cifras. La precisión es de 0.71, por lo que cuando el modelo indica que una persona gana más de 50, acierta en el 71 % de los casos. La exhaustividad es de 0.53, por lo que el modelo solo detecta al 53 % de las personas que realmente ganan más de 50.
Puede crear el ![]() Puntuación basada en la precisión y el recuerdo. El
Puntuación basada en la precisión y el recuerdo. El ![]() es una media armónica de estas dos métricas, lo que significa que da más peso a los valores más bajos.
es una media armónica de estas dos métricas, lo que significa que da más peso a los valores más bajos.

f1 <- 2 * ((prec * rec) / (prec + rec)) f1
Salida:
## [1] 0.6103799
Compensación entre precisión y recuperación
Es imposible tener al mismo tiempo una alta precisión y una alta recuperación.
Si aumentamos la precisión, se predecirá mejor el individuo correcto, pero perderíamos muchos de ellos (menor recuerdo). En algunas situaciones, preferimos una mayor precisión que la recuperación. Existe una relación cóncava entre precisión y recuperación.
- Imagínese, necesita predecir si un paciente tiene una enfermedad. Quieres ser lo más preciso posible.
- Si necesitas detectar posibles personas fraudulentas en la calle mediante el reconocimiento facial, sería mejor detectar a muchas personas etiquetadas como fraudulentas aunque la precisión sea baja. La policía podrá liberar al individuo no fraudulento.
La curva ROC
El Receptor Operacaracterística de tintura La curva es otra herramienta común utilizada con la clasificación binaria. Es muy similar a la curva de precisión/recuperación, pero en lugar de representar gráficamente la precisión versus la recuperación, la curva ROC muestra la tasa de verdaderos positivos (es decir, recuperación) frente a la tasa de falsos positivos. La tasa de falsos positivos es la proporción de casos negativos que se clasifican incorrectamente como positivos. Es igual a uno menos la tasa negativa verdadera. La tasa negativa verdadera también se llama especificidad. Por lo tanto, los gráficos de la curva ROC sensibilidad (recuerdo) versus 1-especificidad
Para trazar la curva ROC, necesitamos instalar un paquete llamado ROCR. Podemos encontrarlo en conda . Puedes escribir el código:
conda install -c r r-rocr --yes
Podemos trazar la República de China con las funciones de predicción() y rendimiento().
library(ROCR) ROCRpred <- prediction(predict, data_test$income) ROCRperf <- performance(ROCRpred, 'tpr', 'fpr') plot(ROCRperf, colorize = TRUE, text.adj = c(-0.2, 1.7))
Code Explicación
- predicción (predecir, prueba_datos $ ingresos): la biblioteca ROCR necesita crear un objeto de predicción para transformar los datos de entrada
- rendimiento (ROCRpred, 'tpr', 'fpr'): devuelve las dos combinaciones para producir en el gráfico. Aquí se construyen tpr y fpr. Para trazar la precisión y recuperar juntos, use "prec", "rec".
Salida:
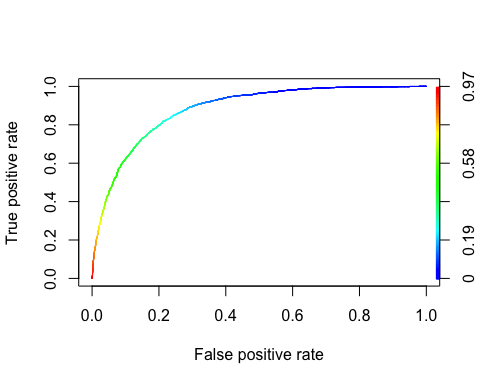
Paso 8) Mejorar el modelo
Puedes intentar agregar no linealidad al modelo con la interacción entre
- Edad y horas por semana
- género y horas por semana.
A continuación, se compara la puntuación F1 de ambos modelos.
formula_2 <- income~age: hours.per.week + gender: hours.per.week + . logit_2 <- glm(formula_2, data = data_train, family = 'binomial') predict_2 <- predict(logit_2, data_test, type = 'response') table_mat_2 <- table(data_test$income, predict_2 > 0.5) precision_2 <- precision(table_mat_2) recall_2 <- recall(table_mat_2) f1_2 <- 2 * ((precision_2 * recall_2) / (precision_2 + recall_2)) f1_2
Salida:
## [1] 0.6109181
La puntuación de F1 es ligeramente superior a la anterior. Puedes seguir trabajando con los datos e intentar superarla.
Cómo interpretar los coeficientes y las razones de probabilidades de los modelos lineales generalizados (GLM) en R.
La tabla resumen impresa en el paso 6 informa los coeficientes en el registro de probabilidades escala, que es difícil de explicar a un público no técnico. Convertirlas en razones de probabilidad hace que el modelo sea mucho más fácil de comunicar.
Sigue estos cuatro pasos.
- Elevar los coeficientes a la potencia exponencial. Aplique exp() a cada estimación para que los logaritmos de las probabilidades se conviertan en razones de probabilidades multiplicativas.
- Añade un intervalo de confianza. Envuelva la función confint() dentro de exp() para obtener el intervalo del 95 por ciento en la misma escala de probabilidades.
- Compara cada valor con 1. Un cociente de probabilidades superior a 1 aumenta la probabilidad de la clase positiva, un valor inferior a 1 la disminuye y un valor cercano a 1 significa que el predictor aporta poco.
- Comprobar la significación estadística. Interprete únicamente los predictores cuyo valor p en el resumen de resultados sea inferior al umbral elegido, normalmente 0.05.
# Convert log-odds coefficients into odds ratios odds_ratio <- exp(coef(logit)) round(odds_ratio, 3) # Odds ratios with 95% confidence intervals exp(cbind(OddsRatio = coef(logit), confint(logit)))
Leyendo la salida. El coeficiente de horas por semana en nuestro modelo es 0.41942. Al exponenciarlo, obtenemos exp(0.41942) = 1.52, lo que significa que un aumento de una desviación estándar en las horas de trabajo semanales multiplica las probabilidades de ganar más de 50 por aproximadamente 1.5, manteniendo constantes todas las demás variables.
Los coeficientes negativos funcionan de la misma manera. marital.statusNot_married es -2.50346, por lo que exp(-2.50346) = 0.08: las personas solteras tienen aproximadamente el 8 por ciento de las probabilidades de una persona casada. Dado que los predictores continuos se estandarizaron en el Paso 1, describa los cambios en unidades de desviación estándar, no en horas brutas.
Nota para otras familias: Los coeficientes exponenciados son razones de probabilidades únicamente bajo la familia binomial con una función de enlace logit. Con family = “poisson” y una función de enlace logarítmica, los mismos valores de exp() se interpretan como razones de tasas.
GLM en R: Referencia rápida de funciones
Ten esta tabla a mano mientras programas. En ella se enumeran todas las funciones utilizadas en los ocho pasos anteriores, junto con el paquete que las proporciona y los argumentos que esperan.
| PREMIUM | Objetivo | Función | Argumento |
|---|---|---|---|
| – | Crear conjunto de datos de entrenamiento/prueba | crear_tren_set() | datos, tamaño, tren |
| glm | Entrenar un modelo lineal generalizado | glm() | fórmula, datos, familia* |
| glm | Resumir el modelo | resumen() | modelo ajustado |
| bases | Hacer predicción | predecir() | modelo ajustado, conjunto de datos, tipo = 'respuesta' |
| bases | Crea una matriz de confusión | mesa() | y, predecir() |
| bases | Crear puntuación de precisión | suma(diag(tabla())/suma(tabla() | |
| ROCR | Crear ROC: Paso 1 Crear predicción | predicción() | predecir(), y |
| ROCR | Crear ROC: Paso 2 Crear rendimiento | actuación() | predicción(), 'tpr', 'fpr' |
| ROCR | Crear ROC: Paso 3 Trazar gráfico | trama() | actuación() |
El otro GLM Las familias disponibles a través del argumento familiar son:
- binomial: (link = “logit”)
- Gaussiana: (link = “identidad”)
- Gamma: (link = “inversa”)
- inverso.gaussiano: (link = “1/mu^2”)
- Poisson: (link = “log”)
- cuasi: (link = “identidad”, varianza = “constante”)
- cuasibinomial: (link = “logit”)
- quasipoisson: (link = “log”)