¿Qué es Hadoop? Introducción, ArchiTectura, Ecosistema, Componentes
¿Qué es Hadoop?
Apache Hadoop es un marco de software de código abierto que se utiliza para desarrollar aplicaciones de procesamiento de datos que se ejecutan en un entorno informático distribuido.
Las aplicaciones creadas con HADOOP se ejecutan en grandes conjuntos de datos distribuidos en clústeres de computadoras comunes. Las computadoras comunes son económicas y están ampliamente disponibles. Su principal utilidad es lograr una mayor potencia computacional a bajo costo.
De manera similar a los datos que residen en un sistema de archivos local de un sistema de computadora personal, en Hadoop, los datos residen en un sistema de archivos distribuido que se denomina Sistema de archivos distribuidos de Hadoop. El modelo de procesamiento se basa en 'Localidad de datos' concepto en el que la lógica computacional se envía a los nodos del clúster (servidor) que contienen datos. Esta lógica computacional no es más que una versión compilada de un programa escrito en un lenguaje de alto nivel como Java. Un programa de este tipo procesa datos almacenados en Hadoop HDFS.
¿Sabes? El grupo de computadoras consta de un conjunto de múltiples unidades de procesamiento (disco de almacenamiento + procesador) que están conectadas entre sí y actúan como un solo sistema.
Ecosistema y componentes de Hadoop
El siguiente diagrama muestra varios componentes del ecosistema Hadoop:

Apache Hadoop consta de dos subproyectos:
- Reducción de mapas de Hadoop: MapReduce es un modelo computacional y un marco de software para escribir aplicaciones que se ejecutan en Hadoop. Estos programas MapReduce son capaces de procesar enormes cantidades de datos en paralelo en grandes grupos de nodos computacionales.
- HDFS (Sistema de archivos distribuidos de Hadoop): HDFS se encarga de la parte de almacenamiento de las aplicaciones Hadoop. Las aplicaciones MapReduce consumen datos de HDFS. HDFS crea múltiples réplicas de bloques de datos y las distribuye en nodos informáticos de un clúster. Esta distribución permite cálculos confiables y extremadamente rápidos.
Aunque Hadoop es mejor conocido por MapReduce y su sistema de archivos distribuido, HDFS, el término también se usa para una familia de proyectos relacionados que caen bajo el paraguas de la computación distribuida y el procesamiento de datos a gran escala. Otros proyectos relacionados con Hadoop en APACHE incluir son Colmena, HBase, Mahout, Sqoop, Flume y ZooKeeper.
Hadoop Architectura
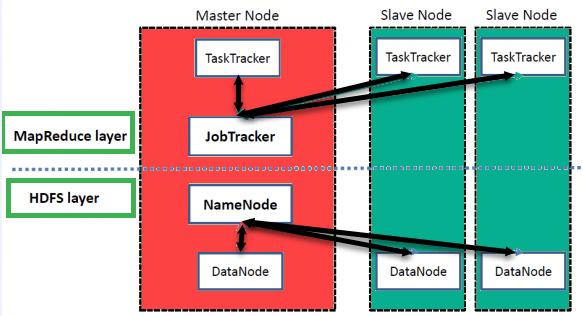
Hadoop tiene un maestro-esclavo ArchiTecnología para almacenamiento de datos y procesamiento de datos distribuidos utilizando MapReduce y métodos HDFS.
NombreNodo:
NameNode representó todos los archivos y directorios que se utilizan en el espacio de nombres
Nodo de datos:
DataNode le ayuda a gestionar el estado de un nodo HDFS y le permite interactuar con los bloques
Nodo maestro:
El nodo maestro le permite realizar procesamiento paralelo de datos utilizando Hadoop MapReduce.
Nodo esclavo:
Los nodos esclavos son máquinas adicionales en el clúster de Hadoop que permiten almacenar datos para realizar cálculos complejos. Además, todos los nodos esclavos vienen con una tarea. Tracker y un DataNode. Esto permite sincronizar los procesos con el NameNode y el Job. Tracker respectivamente.
En Hadoop, el sistema maestro o esclavo se puede configurar en la nube o en las instalaciones
Características de 'Hadoop'
• Adecuado para análisis de Big Data
Como los macrodatos tienden a ser distribuidos y no estructurados por naturaleza, los clústeres HADOOP son los más adecuados para el análisis de macrodatos. Dado que es la lógica de procesamiento (no los datos reales) la que fluye hacia los nodos informáticos, se consume menos ancho de banda de red. Este concepto se denomina concepto de localidad de datos lo que ayuda a aumentar la eficiencia de las aplicaciones basadas en Hadoop.
• Escalabilidad
Los clústeres HADOOP se pueden escalar fácilmente hasta cualquier punto agregando nodos de clúster adicionales, lo que permite el crecimiento de Big Data. Además, el escalamiento no requiere modificaciones en la lógica de la aplicación.
• Tolerancia a fallos
El ecosistema HADOOP tiene una disposición para replicar los datos de entrada en otros nodos del clúster. De esa manera, en caso de que falle un nodo del clúster, el procesamiento de datos puede continuar utilizando los datos almacenados en otro nodo del clúster.
Topología de red en Hadoop
La topología (disposición) de la red afecta el rendimiento del clúster Hadoop cuando el tamaño del mismo aumenta. Además del rendimiento, también es necesario preocuparse por la alta disponibilidad y el manejo de fallas. Para lograr esto, Hadoop utiliza la topología de red en la formación de clústeres.

Por lo general, el ancho de banda de la red es un factor importante a tener en cuenta al formar cualquier red. Sin embargo, dado que medir el ancho de banda puede resultar difícil, en Hadoop, una red se representa como un árbol y la distancia entre los nodos de este árbol (número de saltos) se considera un factor importante en la formación del clúster de Hadoop. Aquí, la distancia entre dos nodos es igual a la suma de su distancia a su ancestro común más cercano.
El clúster de Hadoop consta de un centro de datos, el bastidor y el nodo que realmente ejecuta los trabajos. Aquí, el centro de datos consta de bastidores y el bastidor consta de nodos. El ancho de banda de la red disponible para los procesos varía según la ubicación de los procesos. Es decir, el ancho de banda disponible disminuye a medida que nos alejamos de-
- Procesos en el mismo nodo.
- Diferentes nodos en el mismo rack
- Nodos en distintos racks de un mismo centro de datos
- Nodos en diferentes centros de datos