GLM σε R: Γενικευμένο Γραμμικό Μοντέλο & Λογιστική Παλινδρόμηση
⚡ Έξυπνη Σύνοψη
Generalized Linear Model (GLM) in R extends ordinary regression to outcomes that are binary, count based, or non-normal. This walkthrough builds a logistic GLM on the adult income dataset and evaluates it with accuracy, precision, recall, and ROC.

What is a Generalized Linear Model (GLM) in R?
A Generalized Linear Model (GLM) extends ordinary linear regression so the response variable may follow a distribution other than the normal one. In R, you fit one with the built-in glm() function from the stats package.
Every GLM is defined by three components:
- Random component: the probability distribution of the response variable, taken from the exponential family (binomial, Poisson, Gamma, Gaussian, and others).
- Systematic component: the linear predictor, that is the weighted combination of your explanatory variables.
- Λειτουργία συνδέσμου: the function that connects the mean of the response to the linear predictor, for example the logit link for binary data or the log link for counts.
That structure is what makes the model “generalized”. Instead of forcing a normally distributed outcome, you declare the correct distribution through the οικογένεια argument and R estimates the coefficients by maximum likelihood. Logistic regression is simply a GLM with a binomial family and a logit link, so it is the natural starting point.
What is Logistic Regression in R?
Η λογιστική παλινδρόμηση χρησιμοποιείται για την πρόβλεψη μιας κλάσης, δηλαδή μιας πιθανότητας. Η λογιστική παλινδρόμηση μπορεί να προβλέψει με ακρίβεια ένα δυαδικό αποτέλεσμα.
Φανταστείτε ότι θέλετε να προβλέψετε εάν ένα δάνειο απορρίπτεται/αποδέχεται βάσει πολλών χαρακτηριστικών. Η λογιστική παλινδρόμηση είναι της μορφής 0/1. y = 0 εάν ένα δάνειο απορριφθεί, y = 1 εάν γίνει αποδεκτό.
Ένα μοντέλο λογιστικής παλινδρόμησης διαφέρει από το μοντέλο γραμμικής παλινδρόμησης με δύο τρόπους.
- Πρώτα απ 'όλα, η λογιστική παλινδρόμηση δέχεται μόνο διχοτομική (δυαδική) είσοδο ως εξαρτημένη μεταβλητή (δηλ. ένα διάνυσμα 0 και 1).
- Secondly, the outcome is mapped through a probabilistic link function called the σιγμοειδής (logistic) function due to its S-shape:

Η έξοδος της συνάρτησης είναι πάντα μεταξύ 0 και 1. Ελέγξτε την εικόνα παρακάτω
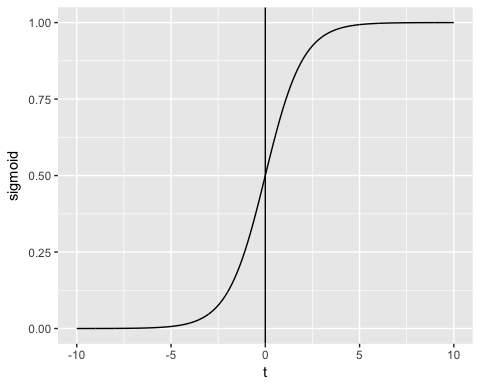
Η σιγμοειδής συνάρτηση επιστρέφει τιμές από 0 έως 1. Για την εργασία ταξινόμησης, χρειαζόμαστε μια διακριτή έξοδο 0 ή 1.
Για να μετατρέψουμε μια συνεχή ροή σε διακριτή τιμή, μπορούμε να ορίσουμε μια απόφαση δεσμευμένη στο 0.5. Όλες οι τιμές πάνω από αυτό το όριο ταξινομούνται ως 1

Now that the link function is clear, compare the generalized model with the ordinary linear model you already know.
GLM vs Linear Regression: Key Differences in R
Before you write any code, it helps to know exactly when the standard γραμμικής παλινδρόμησης function lm() is no longer appropriate and glm() should take its place.
| Κριτήρια | Linear Regression (lm) | Generalized Linear Model (glm) |
|---|---|---|
| Μεταβλητή απόκρισης | Continuous and unbounded | Binary, count, proportion, or positive continuous |
| Error distribution | Normal only | Any exponential family member |
| Λειτουργία σύνδεσης | Identity (implicit) | Explicit: logit, log, inverse, probit |
| Estimation method | Συνηθισμένα ελάχιστα τετράγωνα | Maximum likelihood (IRLS) |
| Υπόθεση διακύμανσης | Constant across observations | Allowed to depend on the mean |
| Goodness-of-fit measure | R-τετράγωνο | AIC and residual deviance |
| Συνάρτηση R | lm(τύπος, δεδομένα) | glm(formula, data, family) |
In short, choose lm() when the outcome is a normally distributed measurement and glm() whenever the outcome is a yes/no decision, a task you could otherwise hand to a δέντρο απόφασης classifier, an event count, or a strictly positive quantity whose spread grows with its mean.
How to Create a Generalized Linear Model (GLM) in R
With the theory settled, the rest of this tutorial applies a binomial GLM end to end on a real dataset.
Ας χρησιμοποιήσουμε το ενήλικας data set to illustrate Logistic regression. The “adult” is a great dataset for the classification task. The objective is to predict whether the annual income of an individual in US dollars will exceed 50,000. The dataset contains 48,842 observations and ten variables:
- ηλικία: ηλικία του ατόμου. Αριθμητικός
- εκπαίδευση: Μορφωτικό επίπεδο του ατόμου. Παράγοντας.
- marital.status: Mariτην κατάσταση του ατόμου. Παράγοντας δηλαδή Ποτέ παντρεμένος, Έγγαμος-πολίτης-σύζυγος,…
- φύλο: Φύλο του ατόμου. Παράγοντας, δηλαδή Αρσενικό ή Θηλυκό
- εισόδημα: Target μεταβλητός. Εισόδημα πάνω ή κάτω από 50 χιλιάδες. Συντελεστής δηλαδή >50K, <=50K
μεταξύ άλλων
library(dplyr) data_adult <-read.csv("https://raw.githubusercontent.com/guru99-edu/R-Programming/master/adult.csv") glimpse(data_adult)
Παραγωγή:
Observations: 48,842 Variables: 10 $ x <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,... $ age <int> 25, 38, 28, 44, 18, 34, 29, 63, 24, 55, 65, 36, 26... $ workclass <fctr> Private, Private, Local-gov, Private, ?, Private,... $ education <fctr> 11th, HS-grad, Assoc-acdm, Some-college, Some-col... $ educational.num <int> 7, 9, 12, 10, 10, 6, 9, 15, 10, 4, 9, 13, 9, 9, 9,... $ marital.status <fctr> Never-married, Married-civ-spouse, Married-civ-sp... $ race <fctr> Black, White, White, Black, White, White, Black, ... $ gender <fctr> Male, Male, Male, Male, Female, Male, Male, Male,... $ hours.per.week <int> 40, 50, 40, 40, 30, 30, 40, 32, 40, 10, 40, 40, 39... $ income <fctr> <=50K, <=50K, >50K, >50K, <=50K, <=50K, <=50K, >5...
Θα προχωρήσουμε ως εξής:
- Βήμα 1: Ελέγξτε τις συνεχείς μεταβλητές
- Βήμα 2: Ελέγξτε τις μεταβλητές συντελεστών
- Βήμα 3: Μηχανική χαρακτηριστικών
- Βήμα 4: Συνοπτική στατιστική
- Βήμα 5: Σετ προπονήσεων/δοκιμών
- Βήμα 6: Κατασκευάστε το μοντέλο
- Βήμα 7: Αξιολογήστε την απόδοση του μοντέλου
- Βήμα 8: Βελτιώστε το μοντέλο
Το καθήκον σας είναι να προβλέψετε ποιο άτομο θα έχει έσοδα μεγαλύτερα από 50 χιλιάδες.
Σε αυτό το σεμινάριο, κάθε βήμα θα είναι λεπτομερές για την εκτέλεση μιας ανάλυσης σε ένα πραγματικό σύνολο δεδομένων.
Βήμα 1) Ελέγξτε τις συνεχείς μεταβλητές
Στο πρώτο βήμα, μπορείτε να δείτε την κατανομή των συνεχών μεταβλητών.
continuous <-select_if(data_adult, is.numeric) summary(continuous)
Code εξήγηση
- συνεχής <- select_if(data_adult, is.numeric): Χρησιμοποιήστε τη συνάρτηση select_if() από τη βιβλιοθήκη dplyr για να επιλέξετε μόνο τις αριθμητικές στήλες
- summary(continuous): Εκτύπωση της συνοπτικής στατιστικής
Παραγωγή:
## X age educational.num hours.per.week ## Min. : 1 Min. :17.00 Min. : 1.00 Min. : 1.00 ## 1st Qu.:11509 1st Qu.:28.00 1st Qu.: 9.00 1st Qu.:40.00 ## Median :23017 Median :37.00 Median :10.00 Median :40.00 ## Mean :23017 Mean :38.56 Mean :10.13 Mean :40.95 ## 3rd Qu.:34525 3rd Qu.:47.00 3rd Qu.:13.00 3rd Qu.:45.00 ## Max. :46033 Max. :90.00 Max. :16.00 Max. :99.00
Από τον παραπάνω πίνακα, μπορείτε να δείτε ότι τα δεδομένα έχουν τελείως διαφορετικές κλίμακες και ότι οι ώρες ανά εβδομάδα έχουν μεγάλες ακραίες τιμές (δηλ. δείτε το τελευταίο τεταρτημόριο και τη μέγιστη τιμή).
Μπορείτε να το αντιμετωπίσετε ακολουθώντας δύο βήματα:
- Plot the distribution of hours.per.week
- Τυποποιήστε τις συνεχείς μεταβλητές
- Σχεδιάστε τη διανομή
Ας δούμε πιο προσεκτικά την κατανομή των ωρών.ανά.εβδομάδα
# Histogram with kernel density curve library(ggplot2) ggplot(continuous, aes(x = hours.per.week)) + geom_density(alpha = .2, fill = "#FF6666")
Παραγωγή:

Η μεταβλητή έχει πολλές ακραίες τιμές και όχι καλά καθορισμένη κατανομή. Μπορείτε να αντιμετωπίσετε εν μέρει αυτό το πρόβλημα διαγράφοντας το κορυφαίο 0.01 τοις εκατό των ωρών ανά εβδομάδα.
Βασική σύνταξη ποσοστού:
quantile(variable, percentile) arguments: -variable: Select the variable in the data frame to compute the percentile -percentile: Can be a single value between 0 and 1 or multiple value. If multiple, use this format: `c(A,B,C, ...) - `A`,`B`,`C` and `...` are all integer from 0 to 1.
We compute the 99th percentile of the weekly working hours.
top_one_percent <- quantile(data_adult$hours.per.week, .99)
top_one_percent
Code εξήγηση
- quantile(data_adult$hours.per.week, .99): Compute the 99th percentile of the weekly working time
Παραγωγή:
## 99% ## 80
Το 99 τοις εκατό του πληθυσμού εργάζεται κάτω από 80 ώρες την εβδομάδα.
Μπορείτε να ρίξετε τις παρατηρήσεις πάνω από αυτό το όριο. Χρησιμοποιείτε το φίλτρο από το dplyr βιβλιοθήκη.
data_adult_drop <-data_adult %>% filter(hours.per.week<top_one_percent) dim(data_adult_drop)
Παραγωγή:
## [1] 45537 10
- Τυποποιήστε τις συνεχείς μεταβλητές
Μπορείτε να τυποποιήσετε κάθε στήλη για να βελτιώσετε την απόδοση επειδή τα δεδομένα σας δεν έχουν την ίδια κλίμακα. Μπορείτε να χρησιμοποιήσετε τη συνάρτηση mutate_if από τη βιβλιοθήκη dplyr. Η βασική σύνταξη είναι:
mutate_if(df, condition, funs(function)) arguments: -`df`: Data frame used to compute the function - `condition`: Statement used. Do not use parenthesis - funs(function): Return the function to apply. Do not use parenthesis for the function
Μπορείτε να τυποποιήσετε τις αριθμητικές στήλες ως εξής:
data_adult_rescale <- data_adult_drop %>% mutate_if(is.numeric, funs(as.numeric(scale(.)))) head(data_adult_rescale)
Code εξήγηση
- mutate_if(is.numeric, funs(scale)): Η συνθήκη είναι μόνο αριθμητική στήλη και η συνάρτηση είναι κλίμακα
Παραγωγή:
## X age workclass education educational.num ## 1 -1.732680 -1.02325949 Private 11th -1.22106443 ## 2 -1.732605 -0.03969284 Private HS-grad -0.43998868 ## 3 -1.732530 -0.79628257 Local-gov Assoc-acdm 0.73162494 ## 4 -1.732455 0.41426100 Private Some-college -0.04945081 ## 5 -1.732379 -0.34232873 Private 10th -1.61160231 ## 6 -1.732304 1.85178149 Self-emp-not-inc Prof-school 1.90323857 ## marital.status race gender hours.per.week income ## 1 Never-married Black Male -0.03995944 <=50K ## 2 Married-civ-spouse White Male 0.86863037 <=50K ## 3 Married-civ-spouse White Male -0.03995944 >50K ## 4 Married-civ-spouse Black Male -0.03995944 >50K ## 5 Never-married White Male -0.94854924 <=50K ## 6 Married-civ-spouse White Male -0.76683128 >50K
Βήμα 2) Ελέγξτε τις μεταβλητές παράγοντα
Αυτό το βήμα έχει δύο στόχους:
- Ελέγξτε το επίπεδο σε κάθε στήλη κατηγορίας
- Ορίστε νέα επίπεδα
Θα χωρίσουμε αυτό το βήμα σε τρία μέρη:
- Επιλέξτε τις κατηγορικές στήλες
- Αποθηκεύστε το γράφημα ράβδων κάθε στήλης σε μια λίστα
- Εκτυπώστε τα γραφήματα
Μπορούμε να επιλέξουμε τις στήλες συντελεστών με τον παρακάτω κωδικό:
# Select categorical column factor <- data.frame(select_if(data_adult_rescale, is.factor)) ncol(factor)
Code εξήγηση
- data.frame(select_if(data_adult, is.factor)): Αποθηκεύουμε τις στήλες συντελεστών σε παράγοντα σε έναν τύπο πλαισίου δεδομένων. Η βιβλιοθήκη ggplot2 απαιτεί ένα αντικείμενο πλαισίου δεδομένων.
Παραγωγή:
## [1] 6
Το σύνολο δεδομένων περιέχει 6 κατηγορικές μεταβλητές
The second step is more demanding. You want to plot a bar chart for each column in the data frame factor. It is more convenient to automatize the process, especially in situation there are lots of columns.
library(ggplot2) # Create graph for each column graph <- lapply(names(factor), function(x) ggplot(factor, aes(get(x))) + geom_bar() + theme(axis.text.x = element_text(angle = 90)))
Code εξήγηση
- lapply(): Χρησιμοποιήστε τη συνάρτηση lapply() για να μεταβιβάσετε μια συνάρτηση σε όλες τις στήλες του συνόλου δεδομένων. Αποθηκεύετε την έξοδο σε μια λίστα
- συνάρτηση(x): Η συνάρτηση θα υποβληθεί σε επεξεργασία για κάθε x. Εδώ x είναι οι στήλες
- ggplot(factor, aes(get(x))) + geom_bar()+ theme(axis.text.x = element_text(angle = 90)): Δημιουργήστε ένα γράφημα χαρακτήρων ράβδων για κάθε στοιχείο x. Σημείωση, για να επιστρέψετε το x ως στήλη, πρέπει να το συμπεριλάβετε στο get()
Το τελευταίο βήμα είναι σχετικά εύκολο. Θέλετε να εκτυπώσετε τα 6 γραφήματα.
# Print the graph
graph
Παραγωγή:
## [[1]]

## ## [[2]]

## ## [[3]]

## ## [[4]]

## ## [[5]]

## ## [[6]]

Σημείωση: Χρησιμοποιήστε το κουμπί επόμενο για να πλοηγηθείτε στο επόμενο γράφημα

Βήμα 3) Μηχανική χαρακτηριστικών
Two categorical variables carry more levels than the model needs. You will regroup them into broader, better-populated categories.
Αναδιατύπωση της εκπαίδευσης
Από το παραπάνω γράφημα, μπορείτε να δείτε ότι η μεταβλητή εκπαίδευση έχει 16 επίπεδα. Αυτό είναι σημαντικό και ορισμένα επίπεδα έχουν σχετικά χαμηλό αριθμό παρατηρήσεων. Εάν θέλετε να βελτιώσετε τον όγκο των πληροφοριών που μπορείτε να λάβετε από αυτήν τη μεταβλητή, μπορείτε να την αναδιατυπώσετε σε υψηλότερο επίπεδο. Δηλαδή, δημιουργείτε μεγαλύτερες ομάδες με παρόμοιο επίπεδο εκπαίδευσης. Για παράδειγμα, το χαμηλό επίπεδο εκπαίδευσης θα μετατραπεί σε εγκατάλειψη. Τα ανώτερα επίπεδα εκπαίδευσης θα αλλάξουν σε master.
Εδώ είναι η λεπτομέρεια:
| Παλιό επίπεδο | Νέο επίπεδο |
|---|---|
| Προσχολικός | εγκατάλειψη |
| 10 | Απόσυρση |
| 11 | Απόσυρση |
| 12 | Απόσυρση |
| 1η-4η | Απόσυρση |
| 5th-6th | Απόσυρση |
| 7th-8th | Απόσυρση |
| 9 | Απόσυρση |
| HS-Grad | HighGrad |
| Κάποιο Κολέγιο | Κοινότητα |
| Αναπλ | Κοινότητα |
| Αναπλ | Κοινότητα |
| Bachelors | Bachelors |
| Masters | Masters |
| Καθηγητής-σχολείο | Masters |
| Διδακτορικό | PhD |
recast_data <- data_adult_rescale %>% select(-X) %>% mutate(education = factor(ifelse(education == "Preschool" | education == "10th" | education == "11th" | education == "12th" | education == "1st-4th" | education == "5th-6th" | education == "7th-8th" | education == "9th", "dropout", ifelse(education == "HS-grad", "HighGrad", ifelse(education == "Some-college" | education == "Assoc-acdm" | education == "Assoc-voc", "Community", ifelse(education == "Bachelors", "Bachelors", ifelse(education == "Masters" | education == "Prof-school", "Master", "PhD")))))))
Code εξήγηση
- Χρησιμοποιούμε το ρήμα mutate από τη βιβλιοθήκη dplyr. Αλλάζουμε τις αξίες της εκπαίδευσης με τη δήλωση ifelse
Στον παρακάτω πίνακα, δημιουργείτε ένα συνοπτικό στατιστικό στοιχείο για να δείτε, κατά μέσο όρο, πόσα χρόνια εκπαίδευσης (τιμή z) χρειάζονται για να φτάσετε στο πτυχίο Bachelor, Master ή PhD.
recast_data %>% group_by(education) %>% summarize(average_educ_year = mean(educational.num), count = n()) %>% arrange(average_educ_year)
Παραγωγή:
## # A tibble: 6 x 3 ## education average_educ_year count ## <fctr> <dbl> <int> ## 1 dropout -1.76147258 5712 ## 2 HighGrad -0.43998868 14803 ## 3 Community 0.09561361 13407 ## 4 Bachelors 1.12216282 7720 ## 5 Master 1.60337381 3338 ## 6 PhD 2.29377644 557
Ανάπλαση Marital-status
Είναι επίσης δυνατό να δημιουργηθούν χαμηλότερα επίπεδα για την οικογενειακή κατάσταση. Στον παρακάτω κώδικα αλλάζετε το επίπεδο ως εξής:
| Παλιό επίπεδο | Νέο επίπεδο |
|---|---|
| Δεν παντρεύτηκε ποτέ | Μη-παντρεμένος |
| Έγγαμος-σύζυγος-απών | Μη-παντρεμένος |
| Έγγαμος-AF-σύζυγος | Παντρεμένος |
| Παντρεμένος-civ-σύζυγος | |
| Χωρισμένος | Χωρισμένος |
| Διαζευγμένος | |
| Χήρες | Χήρα |
# Change level marry recast_data <- recast_data %>% mutate(marital.status = factor(ifelse(marital.status == "Never-married" | marital.status == "Married-spouse-absent", "Not_married", ifelse(marital.status == "Married-AF-spouse" | marital.status == "Married-civ-spouse", "Married", ifelse(marital.status == "Separated" | marital.status == "Divorced", "Separated", "Widow")))))
Μπορείτε να ελέγξετε τον αριθμό των ατόμων σε κάθε ομάδα.
table(recast_data$marital.status)
Παραγωγή:
## ## Married Not_married Separated Widow ## 21165 15359 7727 1286
Βήμα 4) Συνοπτική Στατιστική
Είναι καιρός να ελέγξουμε μερικά στατιστικά στοιχεία σχετικά με τις μεταβλητές-στόχους μας. Στο παρακάτω γράφημα, μετράτε το ποσοστό των ατόμων που κερδίζουν περισσότερα από 50 χιλιάδες, δεδομένου του φύλου τους.
# Plot gender income ggplot(recast_data, aes(x = gender, fill = income)) + geom_bar(position = "fill") + theme_classic()
Παραγωγή:

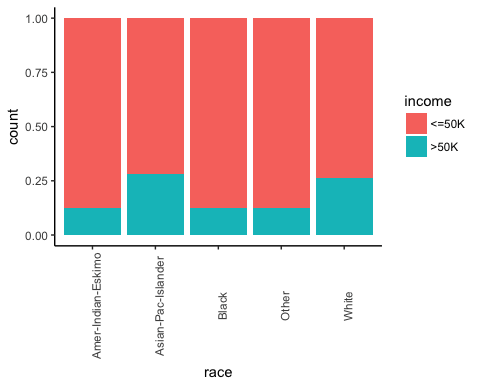
Στη συνέχεια, ελέγξτε αν η καταγωγή του ατόμου επηρεάζει τα κέρδη του.
# Plot origin income ggplot(recast_data, aes(x = race, fill = income)) + geom_bar(position = "fill") + theme_classic() + theme(axis.text.x = element_text(angle = 90))
Παραγωγή:
Ο αριθμός των ωρών εργασίας ανά φύλο.
# box plot gender working time ggplot(recast_data, aes(x = gender, y = hours.per.week)) + geom_boxplot() + stat_summary(fun.y = mean, geom = "point", size = 3, color = "steelblue") + theme_classic()
Παραγωγή:

Το διάγραμμα πλαισίου επιβεβαιώνει ότι η κατανομή του χρόνου εργασίας ταιριάζει σε διαφορετικές ομάδες. Στην πλοκή, και τα δύο φύλα δεν έχουν ομοιογενείς παρατηρήσεις.
Μπορείτε να ελέγξετε την πυκνότητα του εβδομαδιαίου χρόνου εργασίας ανά τύπο εκπαίδευσης. Οι κατανομές έχουν πολλές ξεχωριστές επιλογές. Αυτό πιθανώς μπορεί να εξηγηθεί από τον τύπο τηςtracτ στις ΗΠΑ.
# Plot distribution working time by education ggplot(recast_data, aes(x = hours.per.week)) + geom_density(aes(color = education), alpha = 0.5) + theme_classic()
Code εξήγηση
- ggplot(recast_data, aes( x= hours.per.week)): Μια γραφική παράσταση πυκνότητας απαιτεί μόνο μία μεταβλητή
- geom_density(aes(color = Education), alpha =0.5): Το γεωμετρικό αντικείμενο για τον έλεγχο της πυκνότητας
Παραγωγή:

Για να επιβεβαιώσετε τις σκέψεις σας, μπορείτε να κάνετε μονόδρομο Δοκιμή ANOVA:
anova <- aov(hours.per.week~education, recast_data) summary(anova)
Παραγωγή:
## Df Sum Sq Mean Sq F value Pr(>F) ## education 5 1552 310.31 321.2 <2e-16 *** ## Residuals 45531 43984 0.97 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Το τεστ ANOVA επιβεβαιώνει τη διαφορά του μέσου όρου μεταξύ των ομάδων.
Μη γραμμικότητα
Πριν εκτελέσετε το μοντέλο, μπορείτε να δείτε εάν ο αριθμός των ωρών εργασίας σχετίζεται με την ηλικία.
library(ggplot2) ggplot(recast_data, aes(x = age, y = hours.per.week)) + geom_point(aes(color = income), size = 0.5) + stat_smooth(method = 'lm', formula = y~poly(x, 2), se = TRUE, aes(color = income)) + theme_classic()
Code εξήγηση
- ggplot(recast_data, aes(x = ηλικία, y = hours.per.week)): Ορίστε την αισθητική του γραφήματος
- geom_point(aes(color= εισόδημα), size =0.5): Κατασκευάστε το διάγραμμα με τελείες
- stat_smooth(): Προσθέστε τη γραμμή τάσης με τα ακόλουθα ορίσματα:
- μέθοδος='lm': Σχεδιάστε την προσαρμοσμένη τιμή εάν η γραμμικής παλινδρόμησης
- τύπος = y~poly(x,2): Προσαρμόστε μια πολυωνυμική παλινδρόμηση
- se = TRUE: Προσθέστε το τυπικό σφάλμα
- aes(χρώμα= εισόδημα): Σπάστε το μοντέλο ανά εισόδημα
Παραγωγή:

Με λίγα λόγια, μπορείτε να δοκιμάσετε τους όρους αλληλεπίδρασης στο μοντέλο για να διαπιστώσετε το φαινόμενο μη γραμμικότητας μεταξύ του εβδομαδιαίου χρόνου εργασίας και άλλων χαρακτηριστικών. Είναι σημαντικό να εντοπιστεί υπό ποιες συνθήκες διαφέρει ο χρόνος εργασίας.
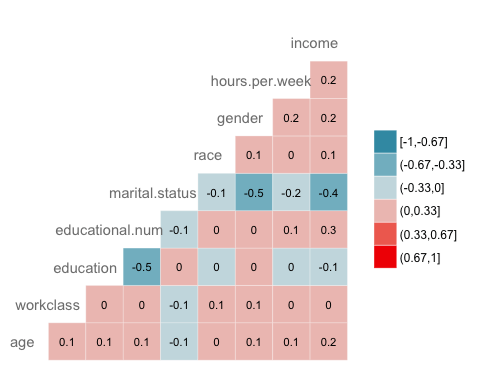
Συσχέτιση
Ο επόμενος έλεγχος είναι η οπτικοποίηση της συσχέτισης μεταξύ των μεταβλητών. Μετατρέπετε τον τύπο επιπέδου παράγοντα σε αριθμητικό, ώστε να μπορείτε να σχεδιάσετε έναν θερμικό χάρτη που περιέχει τον συντελεστή συσχέτισης που υπολογίζεται με τη μέθοδο Spearman.
library(GGally) # Convert data to numeric corr <- data.frame(lapply(recast_data, as.integer)) # Plot the graphggcorr(corr, method = c("pairwise", "spearman"), nbreaks = 6, hjust = 0.8, label = TRUE, label_size = 3, color = "grey50")
Code εξήγηση
- data.frame(lapply(recast_data,as.integer)): Μετατροπή δεδομένων σε αριθμητικό
- ggcorr() σχεδιάστε τον χάρτη θερμότητας με τα ακόλουθα ορίσματα:
- μέθοδος: Μέθοδος υπολογισμού της συσχέτισης
- nbreaks = 6: Αριθμός διαλείμματος
- hjust = 0.8: Θέση ελέγχου του ονόματος της μεταβλητής στο διάγραμμα
- label = TRUE: Προσθέστε ετικέτες στο κέντρο των παραθύρων
- label_size = 3: Ετικέτες μεγέθους
- color = “grey50”): Χρώμα της ετικέτας
Παραγωγή:
Βήμα 5) Σετ προπονήσεων/δοκιμών
Οποιαδήποτε εποπτευόμενη μάθηση μηχανής task requires you to split the data between a train set and a test set. You can use the “function” you created in the other supervised learning tutorials to create a train/test set.
set.seed(1234) create_train_test <- function(data, size = 0.8, train = TRUE) { n_row = nrow(data) total_row = size * n_row train_sample <- 1: total_row if (train == TRUE) { return (data[train_sample, ]) } else { return (data[-train_sample, ]) } } data_train <- create_train_test(recast_data, 0.8, train = TRUE) data_test <- create_train_test(recast_data, 0.8, train = FALSE) dim(data_train)
Παραγωγή:
## [1] 36429 9
dim(data_test)
Παραγωγή:
## [1] 9108 9
Βήμα 6) Κατασκευάστε το μοντέλο
To see how the algorithm performs, you use the glm() function from the stats package. The Γενικευμένο γραμμικό μοντέλο είναι μια συλλογή μοντέλων. Η βασική σύνταξη είναι:
glm(formula, data=data, family=linkfunction() Argument: - formula: Equation used to fit the model- data: dataset used - Family: - binomial: (link = "logit") - gaussian: (link = "identity") - Gamma: (link = "inverse") - inverse.gaussian: (link = "1/mu^2") - poisson: (link = "log") - quasi: (link = "identity", variance = "constant") - quasibinomial: (link = "logit") - quasipoisson: (link = "log")
Είστε έτοιμοι να υπολογίσετε το λογιστικό μοντέλο για να χωρίσετε το επίπεδο εισοδήματος μεταξύ ενός συνόλου χαρακτηριστικών.
formula <- income~. logit <- glm(formula, data = data_train, family = 'binomial') summary(logit)
Code εξήγηση
- τύπος <- εισόδημα ~ .: Δημιουργήστε το μοντέλο που ταιριάζει
- logit <- glm(τύπος, δεδομένα = data_train, οικογένεια = 'διωνυμικό'): Προσαρμόστε ένα λογιστικό μοντέλο (οικογένεια = 'διωνυμικό') με τα δεδομένα data_train.
- summary(logit): Εκτυπώστε την περίληψη του μοντέλου
Παραγωγή:
## ## Call: ## glm(formula = formula, family = "binomial", data = data_train) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -2.6456 -0.5858 -0.2609 -0.0651 3.1982 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|) ## (Intercept) 0.07882 0.21726 0.363 0.71675 ## age 0.41119 0.01857 22.146 < 2e-16 *** ## workclassLocal-gov -0.64018 0.09396 -6.813 9.54e-12 *** ## workclassPrivate -0.53542 0.07886 -6.789 1.13e-11 *** ## workclassSelf-emp-inc -0.07733 0.10350 -0.747 0.45499 ## workclassSelf-emp-not-inc -1.09052 0.09140 -11.931 < 2e-16 *** ## workclassState-gov -0.80562 0.10617 -7.588 3.25e-14 *** ## workclassWithout-pay -1.09765 0.86787 -1.265 0.20596 ## educationCommunity -0.44436 0.08267 -5.375 7.66e-08 *** ## educationHighGrad -0.67613 0.11827 -5.717 1.08e-08 *** ## educationMaster 0.35651 0.06780 5.258 1.46e-07 *** ## educationPhD 0.46995 0.15772 2.980 0.00289 ** ## educationdropout -1.04974 0.21280 -4.933 8.10e-07 *** ## educational.num 0.56908 0.07063 8.057 7.84e-16 *** ## marital.statusNot_married -2.50346 0.05113 -48.966 < 2e-16 *** ## marital.statusSeparated -2.16177 0.05425 -39.846 < 2e-16 *** ## marital.statusWidow -2.22707 0.12522 -17.785 < 2e-16 *** ## raceAsian-Pac-Islander 0.08359 0.20344 0.411 0.68117 ## raceBlack 0.07188 0.19330 0.372 0.71001 ## raceOther 0.01370 0.27695 0.049 0.96054 ## raceWhite 0.34830 0.18441 1.889 0.05894 . ## genderMale 0.08596 0.04289 2.004 0.04506 * ## hours.per.week 0.41942 0.01748 23.998 < 2e-16 *** ## ---## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## (Dispersion parameter for binomial family taken to be 1) ## ## Null deviance: 40601 on 36428 degrees of freedom ## Residual deviance: 27041 on 36406 degrees of freedom ## AIC: 27087 ## ## Number of Fisher Scoring iterations: 6
Η περίληψη του μοντέλου μας αποκαλύπτει ενδιαφέρουσες πληροφορίες. Η απόδοση μιας λογιστικής παλινδρόμησης αξιολογείται με συγκεκριμένες βασικές μετρήσεις.
- AIC (Akaike Information Criteria): Αυτό είναι το ισοδύναμο του R2 σε λογιστική παλινδρόμηση. Μετρά την προσαρμογή όταν εφαρμόζεται ποινή στον αριθμό των παραμέτρων. Μικρότερος AIC Οι τιμές δείχνουν ότι το μοντέλο είναι πιο κοντά στην αλήθεια.
- Μηδενική απόκλιση: Ταιριάζει στο μοντέλο μόνο με την τομή. Ο βαθμός ελευθερίας είναι n-1. Μπορούμε να το ερμηνεύσουμε ως τιμή Chi-square (προσαρμοσμένη τιμή διαφορετική από τον έλεγχο της πραγματικής υπόθεσης τιμής).
- Residual Deviance: Μοντέλο με όλες τις μεταβλητές. Ερμηνεύεται επίσης ως δοκιμή υποθέσεων Chi-square.
- Αριθμός επαναλήψεων βαθμολογίας Fisher: Αριθμός επαναλήψεων πριν από τη σύγκλιση.
Η έξοδος της συνάρτησης glm() αποθηκεύεται σε μια λίστα. Ο παρακάτω κώδικας δείχνει όλα τα στοιχεία που είναι διαθέσιμα στη μεταβλητή logit που κατασκευάσαμε για την αξιολόγηση της λογιστικής παλινδρόμησης.
# Η λίστα είναι πολύ μεγάλη, εκτυπώστε μόνο τα τρία πρώτα στοιχεία
lapply(logit, class)[1:3]
Παραγωγή:
## $coefficients ## [1] "numeric" ## ## $residuals ## [1] "numeric" ## ## $fitted.values ## [1] "numeric"
Κάθε τιμή μπορεί να είναι π.χ.tracμε το σύμβολο $ ακολουθούμενο από το όνομα των μετρήσεων. Για παράδειγμα, αποθηκεύσατε το μοντέλο ως logit. Για παράδειγμαtracμε τα κριτήρια AIC, χρησιμοποιείτε:
logit$aic
Παραγωγή:
## [1] 27086.65
Βήμα 7) Αξιολογήστε την απόδοση του μοντέλου
Πίνακας σύγχυσης
The μήτρα σύγχυσης είναι μια καλύτερη επιλογή για την αξιολόγηση της απόδοσης της ταξινόμησης σε σύγκριση με τις διαφορετικές μετρήσεις που είδατε πριν. Η γενική ιδέα είναι να μετράμε πόσες φορές τα True instances ταξινομούνται ως False.

Για να υπολογίσετε τον πίνακα σύγχυσης, πρέπει πρώτα να έχετε ένα σύνολο προβλέψεων ώστε να μπορούν να συγκριθούν με τους πραγματικούς στόχους.
predict <- predict(logit, data_test, type = 'response') # confusion matrix table_mat <- table(data_test$income, predict > 0.5) table_mat
Code εξήγηση
- predict(logit,data_test, type = 'response'): Υπολογίστε την πρόβλεψη στο σύνολο δοκιμής. Ορίστε τον τύπο = 'απόκριση' για να υπολογίσετε την πιθανότητα απόκρισης.
- πίνακας(data_test$income, predict > 0.5): Υπολογίστε τον πίνακα σύγχυσης. προβλέψει > 0.5 σημαίνει ότι επιστρέφει 1 εάν οι προβλεπόμενες πιθανότητες είναι πάνω από 0.5, αλλιώς 0.
Παραγωγή:
## ## FALSE TRUE ## <=50K 6310 495 ## >50K 1074 1229
Each row in a confusion matrix represents an actual target, while each column represents a predicted target. The first row of this matrix considers the income lower than 50k (the negative class): 6,310 observations were correctly classified as individuals with income lower than 50k (Αληθινό αρνητικό), while 495 were wrongly classified as above 50k (Λάθος θετική). The second row considers the income above 50k: 1,229 were correctly identified (Αληθινό θετικό), ενώ 1,074 χάθηκαν (Εσφαλμένο αρνητικό).
Μπορείτε να υπολογίσετε το μοντέλο ακρίβεια αθροίζοντας το αληθινό θετικό + αληθινό αρνητικό στη συνολική παρατήρηση

accuracy_Test <- sum(diag(table_mat)) / sum(table_mat) accuracy_Test
Code εξήγηση
- sum(diag(table_mat)): Άθροισμα της διαγωνίου
- sum(table_mat): Άθροισμα του πίνακα.
Παραγωγή:
## [1] 0.8277339
The model appears to suffer from one problem: it produces too many false negatives. This is called the παράδοξο δοκιμής ακρίβειας. We stated that the accuracy is the ratio of correct predictions to the total number of cases. We can have relatively high accuracy but a useless model. It happens when there is a dominant class. If you look back at the confusion matrix, you can see most of the cases are classified as true negative. Imagine now, the model classified every observation as negative (i.e. lower than 50k). You would still obtain an accuracy of about 75 percent (6,805 / 9,108). Your model performs better but struggles to distinguish the true positive with the true negative.
Σε μια τέτοια περίπτωση, είναι προτιμότερο να έχουμε μια πιο συνοπτική μέτρηση. Μπορούμε να δούμε:
- Ακρίβεια=TP/(TP+FP)
- Ανάκληση=TP/(TP+FN)
Ακρίβεια εναντίον ανάκλησης
Ακρίβεια εξετάζει την ακρίβεια της θετικής πρόβλεψης. Ανάκληση είναι ο λόγος των θετικών περιπτώσεων που ανιχνεύονται σωστά από τον ταξινομητή.
Μπορείτε να δημιουργήσετε δύο συναρτήσεις για να υπολογίσετε αυτές τις δύο μετρήσεις
- Ακρίβεια κατασκευής
precision <- function(matrix) { # True positive tp <- matrix[2, 2] # false positive fp <- matrix[1, 2] return (tp / (tp + fp)) }
Code εξήγηση
- mat[1,1]: Επιστρέψτε το πρώτο κελί της πρώτης στήλης του πλαισίου δεδομένων, δηλαδή το αληθινό θετικό
- ματ[1,2]; Επιστρέψτε το πρώτο κελί της δεύτερης στήλης του πλαισίου δεδομένων, δηλαδή το ψευδώς θετικό
recall <- function(matrix) { # true positive tp <- matrix[2, 2]# false positive fn <- matrix[2, 1] return (tp / (tp + fn)) }
Code εξήγηση
- mat[1,1]: Επιστρέψτε το πρώτο κελί της πρώτης στήλης του πλαισίου δεδομένων, δηλαδή το αληθινό θετικό
- mat[2,1]; Επιστρέψτε το δεύτερο κελί της πρώτης στήλης του πλαισίου δεδομένων, δηλαδή το ψευδώς αρνητικό
Μπορείτε να δοκιμάσετε τις λειτουργίες σας
prec <- precision(table_mat) prec rec <- recall(table_mat) rec
Παραγωγή:
## [1] 0.712877 ## [2] 0.5336518
Read these two numbers carefully. Precision is 0.71, so when the model says an individual earns above 50k, it is correct in 71 percent of the cases. Recall is 0.53, so the model only detects 53 percent of the individuals who truly earn above 50k.
Μπορείτε να δημιουργήσετε το ![]() βαθμολογία με βάση την ακρίβεια και την ανάκληση. ο
βαθμολογία με βάση την ακρίβεια και την ανάκληση. ο ![]() είναι ένας αρμονικός μέσος όρος αυτών των δύο μετρήσεων, που σημαίνει ότι δίνει μεγαλύτερη βαρύτητα στις χαμηλότερες τιμές.
είναι ένας αρμονικός μέσος όρος αυτών των δύο μετρήσεων, που σημαίνει ότι δίνει μεγαλύτερη βαρύτητα στις χαμηλότερες τιμές.

f1 <- 2 * ((prec * rec) / (prec + rec)) f1
Παραγωγή:
## [1] 0.6103799
Ανταλλαγή Ακρίβειας και Ανάκλησης
Είναι αδύνατο να έχουμε τόσο υψηλή ακρίβεια όσο και υψηλή ανάκληση.
Εάν αυξήσουμε την ακρίβεια, το σωστό άτομο θα προβλεφθεί καλύτερα, αλλά θα χάναμε πολλά από αυτά (χαμηλότερη ανάκληση). Σε ορισμένες περιπτώσεις, προτιμάμε μεγαλύτερη ακρίβεια από την ανάκληση. Υπάρχει μια κοίλη σχέση μεταξύ ακρίβειας και ανάκλησης.
- Φανταστείτε, πρέπει να προβλέψετε εάν ένας ασθενής έχει ασθένεια. Θέλετε να είστε όσο πιο ακριβείς γίνεται.
- Εάν χρειάζεται να εντοπίσετε πιθανούς απατεώνες στο δρόμο μέσω της αναγνώρισης προσώπου, θα ήταν καλύτερο να πιάσετε πολλά άτομα που χαρακτηρίζονται ως δόλιες, παρόλο που η ακρίβεια είναι χαμηλή. Η αστυνομία θα μπορέσει να απελευθερώσει τον μη δόλιο.
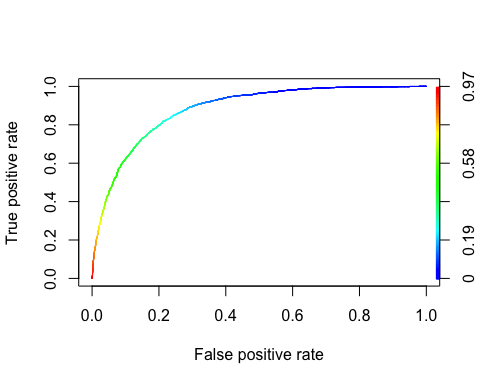
Η καμπύλη ROC
The Δέκτης Operating Χαρακτηριστικό Η καμπύλη είναι ένα άλλο κοινό εργαλείο που χρησιμοποιείται με τη δυαδική ταξινόμηση. Μοιάζει πολύ με την καμπύλη ακριβείας/ανάκλησης, αλλά αντί να σχεδιάζεται η ακρίβεια έναντι της ανάκλησης, η καμπύλη ROC εμφανίζει τον πραγματικό θετικό ρυθμό (δηλαδή, ανάκληση) έναντι του ψευδώς θετικού ποσοστού. Το ποσοστό ψευδώς θετικών είναι ο λόγος των αρνητικών περιπτώσεων που ταξινομούνται εσφαλμένα ως θετικές. Είναι ίσο με ένα μείον το πραγματικό αρνητικό ποσοστό. Ο πραγματικός αρνητικός ρυθμός ονομάζεται επίσης εξειδίκευση. Εξ ου και η καμπύλη ROC ευαισθησία (ανάκληση) έναντι 1-ειδικότητας
To plot the ROC curve, we need to install a package called ROCR. We can find in the conda βιβλιοθήκη. Μπορείτε να πληκτρολογήσετε τον κωδικό:
conda install -c r r-rocr --yes
Μπορούμε να σχεδιάσουμε το ROC με τις συναρτήσεις prediction() και performance().
library(ROCR) ROCRpred <- prediction(predict, data_test$income) ROCRperf <- performance(ROCRpred, 'tpr', 'fpr') plot(ROCRperf, colorize = TRUE, text.adj = c(-0.2, 1.7))
Code εξήγηση
- prediction(predict, data_test$income): Η βιβλιοθήκη ROCR πρέπει να δημιουργήσει ένα αντικείμενο πρόβλεψης για να μετασχηματίσει τα δεδομένα εισόδου
- performance(ROCRpred, 'tpr','fpr'): Επιστρέψτε τους δύο συνδυασμούς για παραγωγή στο γράφημα. Εδώ κατασκευάζονται τα tpr και fpr. Συνολική ακρίβεια σχεδίασης και ανάκληση μαζί, χρησιμοποιήστε "prec", "rec".
Παραγωγή:
Βήμα 8) Βελτιώστε το μοντέλο
Μπορείτε να προσπαθήσετε να προσθέσετε μη γραμμικότητα στο μοντέλο με την αλληλεπίδραση μεταξύ
- ηλικία και ώρες.ανά.εβδομάδα
- φύλο και ώρες.ανά.εβδομάδα.
You then compare the F1 score of both models.
formula_2 <- income~age: hours.per.week + gender: hours.per.week + . logit_2 <- glm(formula_2, data = data_train, family = 'binomial') predict_2 <- predict(logit_2, data_test, type = 'response') table_mat_2 <- table(data_test$income, predict_2 > 0.5) precision_2 <- precision(table_mat_2) recall_2 <- recall(table_mat_2) f1_2 <- 2 * ((precision_2 * recall_2) / (precision_2 + recall_2)) f1_2
Παραγωγή:
## [1] 0.6109181
The F1 score is slightly higher than the previous one. You can keep working on the data a try to beat the score.
How to Interpret GLM Coefficients and Odds Ratios in R
The summary table printed in Step 6 reports coefficients on the log-πιθανότητες scale, which is difficult to explain to a non-technical audience. Converting them into odds ratios makes the model far easier to communicate.
Follow these four steps.
- Exponentiate the coefficients. Apply exp() to every estimate so the log-odds become multiplicative odds ratios.
- Add a confidence interval. Wrap confint() in exp() to obtain the 95 percent interval on the same odds scale.
- Compare each value against 1. An odds ratio above 1 increases the probability of the positive class, a value below 1 decreases it, and a value close to 1 means the predictor adds little.
- Check statistical significance. Only interpret predictors whose p-value in the summary output is below your chosen threshold, typically 0.05.
# Convert log-odds coefficients into odds ratios odds_ratio <- exp(coef(logit)) round(odds_ratio, 3) # Odds ratios with 95% confidence intervals exp(cbind(OddsRatio = coef(logit), confint(logit)))
Reading the output. The coefficient for hours.per.week in our model is 0.41942. Exponentiating it gives exp(0.41942) = 1.52, which means that a one standard deviation increase in weekly working hours multiplies the odds of earning above 50k by roughly 1.5, holding every other variable constant.
Negative coefficients work the same way. marital.statusNot_married is -2.50346, so exp(-2.50346) = 0.08: unmarried individuals hold about 8 percent of the odds of a married individual. Because the continuous predictors were standardized in Step 1, describe changes in standard deviation units, not raw hours.
Note for other families: exponentiated coefficients are odds ratios only under the binomial family with a logit link. With family = “poisson” and a log link, the same exp() values are read as rate ratios instead.
GLM in R: Quick Function Reference
Keep this table beside you while you code. It lists every function used in the eight steps above, together with the package that supplies it and the arguments it expects.
| Πακέτο | Σκοπός | Λειτουργία | Διαφωνία |
|---|---|---|---|
| - | Δημιουργία συνόλου δεδομένων τρένου/δοκιμών | create_train_set() | δεδομένα, μέγεθος, τρένο |
| γλαμ | Εκπαιδεύστε ένα Γενικευμένο Γραμμικό Μοντέλο | glm() | τύπος, δεδομένα, οικογένεια* |
| γλαμ | Συνοψίστε το μοντέλο | περίληψη() | προσαρμοσμένο μοντέλο |
| βάση | Κάντε πρόβλεψη | προλέγω() | προσαρμοσμένο μοντέλο, σύνολο δεδομένων, τύπος = 'ανταπόκριση' |
| βάση | Δημιουργήστε μια μήτρα σύγχυσης | τραπέζι() | y, προβλέψτε() |
| βάση | Δημιουργήστε βαθμολογία ακρίβειας | sum(diag(πίνακας())/sum(πίνακας() | |
| ROCR | Δημιουργία ROC: Βήμα 1 Δημιουργήστε πρόβλεψη | προφητεία() | predict(), y |
| ROCR | Δημιουργία ROC: Βήμα 2 Δημιουργήστε απόδοση | εκτέλεση() | prediction(), 'tpr', 'fpr' |
| ROCR | Δημιουργία ROC: Βήμα 3 Σχεδιάστε το γράφημα | οικόπεδο() | εκτέλεση() |
Το άλλο GLM families available through the family argument are:
- binomial: (link = “logit”)
- gaussian: (link = “identity”)
- Gamma: (link = “inverse”)
- inverse.gaussian: (link = “1/mu^2”)
- poisson: (link = “log”)
- quasi: (link = “identity”, variance = “constant”)
- quasibinomial: (link = “logit”)
- quasipoisson: (link = “log”)