XPath ein Selenium: Lernprogramm

Worin ist XPath enthalten? Selenium?
XPath ein Selenium ist ein XML-Pfad, der für die Navigation durch die HTML-Struktur der Seite verwendet wird. Es handelt sich um eine Syntax oder Sprache zum Auffinden beliebiger Elemente auf einer Webseite mithilfe eines XML-Pfadausdrucks. XPath kann sowohl für HTML- als auch für XML-Dokumente verwendet werden, um mithilfe der HTML-DOM-Struktur die Position eines beliebigen Elements auf einer Webseite zu ermitteln.
In Selenium Bei der Automatisierung wird, falls die Elemente nicht mit allgemeinen Selektoren wie id, class, name usw. gefunden werden, XPath verwendet, um ein Element auf der Webseite zu finden.
In diesem Tutorial lernen wir XPath und verschiedene XPath-Ausdrücke kennen, um komplexe oder dynamische Elemente zu finden, deren Attribute sich beim Aktualisieren oder bei anderen Vorgängen dynamisch ändern.
XPath-Syntax
XPath enthält den Pfad des Elements, das sich auf der Webseite befindet. Die Standard-XPath-Syntax zum Erstellen von XPath lautet.
Xpath=//tagname[@attribute='value']
Das grundlegende Format von XPath in Selenium wird unten anhand eines Screenshots erläutert.
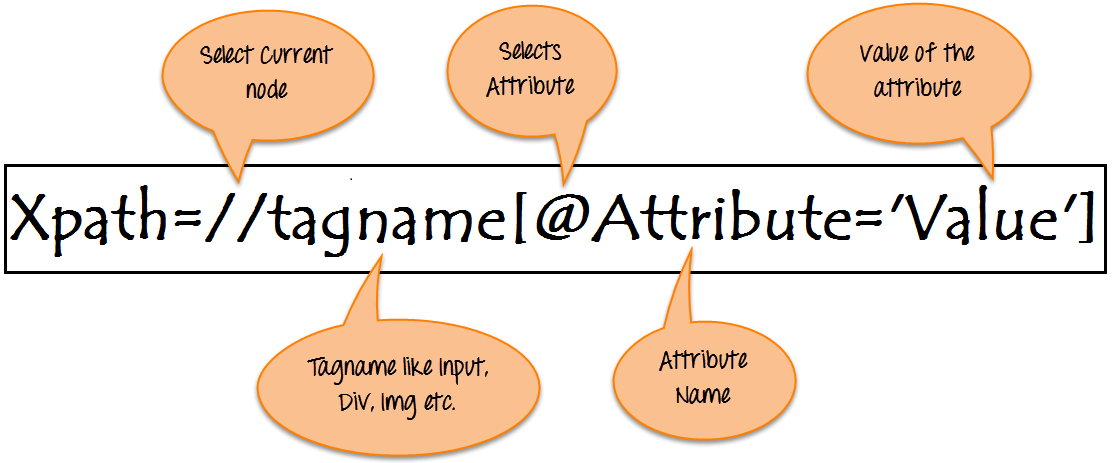
- // : Aktuellen Knoten auswählen.
- Verlinke den Namen: Tagname des jeweiligen Knotens.
- @: Attribut auswählen.
- Attribut: Attributname des Knotens.
- Wert: Wert des Attributs.
Um das Element auf Webseiten genau zu finden, gibt es verschiedene Arten von Locators:
| XPath-Locator | Finden Sie verschiedene Elemente auf der Webseite |
|---|---|
| ID | Um das Element anhand der ID des Elements zu finden |
| Klassenname | Um das Element anhand des Klassennamens des Elements zu finden |
| Name | Um das Element anhand des Namens zu finden |
| Link Text | Um das Element anhand des Textes des Links zu finden |
| XPath | XPath ist erforderlich, um das dynamische Element zu finden und zwischen verschiedenen Elementen der Webseite zu wechseln |
| CSS-Pfad | Der CSS-Pfad findet auch Elemente ohne Namen, Klasse oder ID. |
Arten von X-Pfaden
Es gibt zwei Arten von XPath:
1) Absoluter XPath
2) Relativer XPath
Absoluter XPath
Dies ist der direkte Weg, das Element zu finden, aber der Nachteil des absoluten XPath besteht darin, dass dieser XPath fehlschlägt, wenn Änderungen am Pfad des Elements vorgenommen werden.
Das Hauptmerkmal von XPath ist, dass es mit einem einzelnen Schrägstrich (/) beginnt, was bedeutet, dass Sie das Element vom Wurzelknoten aus auswählen können.
Unten sehen Sie das Beispiel eines absoluten Xpath-Ausdrucks des im folgenden Bildschirm gezeigten Elements.
HINWEIS: Sie können die folgende XPath-Übung auf diesem https://demo.guru99.com/test/selenium-xpath.html
Klicken Sie auf werden auf dieser Seite erläutert wenn das Video nicht zugänglich ist
Absoluter XPath:
/html/body/div[2]/div[1]/div/h4[1]/b/html[1]/body[1]/div[2]/div[1]/div[1]/h4[1]/b[1]

Relativer XPath
Relativer XPath beginnt in der Mitte der HTML-DOM-Struktur. Es beginnt mit einem doppelten Schrägstrich (//). Es kann Elemente überall auf der Webseite suchen, d. h. Sie müssen keinen langen XPath schreiben und können in der Mitte der HTML-DOM-Struktur beginnen. Relativer XPath ist immer vorzuziehen, da es sich nicht um einen vollständigen Pfad vom Stammelement handelt.
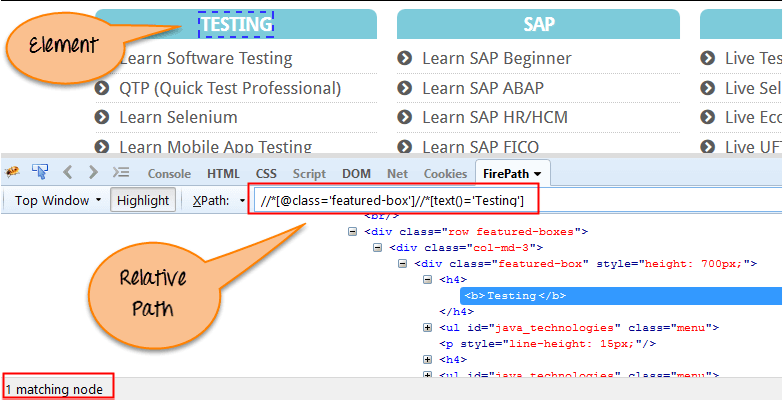
Unten sehen Sie das Beispiel eines relativen XPath-Ausdrucks desselben Elements, das im folgenden Bildschirm gezeigt wird. Dies ist das gängige Format, das zum Suchen von Elementen mit XPath verwendet wird.
Klicken Sie auf werden auf dieser Seite erläutert wenn das Video nicht zugänglich ist
Relative XPath: //div[@class='featured-box cloumnsize1']//h4[1]//b[1]
Was sind XPath-Achsen?
XPath-Achsen durchsuchen verschiedene Knoten im XML-Dokument vom aktuellen Kontextknoten aus. XPath-Achsen sind Methoden zum Auffinden dynamischer Elemente, die mit normalen XPath-Methoden ohne ID, Klassennamen, Namen usw. nicht gefunden werden können. XPath in Selenium enthält mehrere Methoden wie „Contains“, „AND“, „Absolute XPath“ und „Relative XPath“, um dynamische Elemente basierend auf verschiedenen Attributen und Bedingungen zu identifizieren und zu lokalisieren.
Achsenmethoden werden verwendet, um Elemente zu finden, die sich beim Aktualisieren oder bei anderen Vorgängen dynamisch ändern. Es gibt einige Achsenmethoden, die häufig in Selenium Webtreiber wie Kind, Elternteil, Vorfahre, Geschwister, Vorgänger, Selbst usw.
So schreiben Sie dynamischen XPath hinein Selenium WebTreiber
1) Grundlegender XPath
XPath-Ausdrücke wählen Knoten oder Knotenlisten auf der Grundlage von Attributen wie aus ID, Name, Klassennameusw. aus dem XML-Dokument, wie unten dargestellt.
Xpath=//input[@name='uid']
Hier ist ein Link, um auf die Seite zuzugreifen https://demo.guru99.com/test/selenium-xpath.html

Einige weitere grundlegende XPath-Ausdrücke:
Xpath=//input[@type='text'] Xpath=//label[@id='message23'] Xpath=//input[@value='RESET'] Xpath=//*[@class='barone'] Xpath=//a[@href='https://demo.guru99.com/'] Xpath=//img[@src='//guru99.com/images/home/java.png']
2) Enthält()
Contains() ist eine Methode, die im XPath-Ausdruck verwendet wird. Es wird verwendet, wenn sich der Wert eines Attributs dynamisch ändert, beispielsweise Anmeldeinformationen.
Die Funktion „Einschließen“ bietet die Möglichkeit, das Element mit Teiltext zu finden, wie im folgenden XPath-Beispiel gezeigt.
In diesem Beispiel haben wir versucht, das Element zu identifizieren, indem wir einfach einen Teiltextwert des Attributs verwendeten. Im folgenden XPath-Ausdruck wird der Teilwert „sub“ anstelle der Schaltfläche „Senden“ verwendet. Es ist zu beobachten, dass das Element erfolgreich gefunden wurde.
Der vollständige Wert von „Type“ ist „submit“, es wird jedoch nur der Teilwert „sub“ verwendet.
Xpath=//*[contains(@type,'sub')]
Der vollständige Wert von „name“ ist „btnLogin“, es wird jedoch nur der Teilwert „btn“ verwendet.
Xpath=//*[contains(@name,'btn')]
Im obigen Ausdruck haben wir „name“ als Attribut und „btn“ als Teilwert verwendet, wie im folgenden Screenshot gezeigt. Dadurch werden zwei Elemente (LOGIN & RESET) gefunden, da ihr Attribut „name“ mit „btn“ beginnt.

Ebenso haben wir im folgenden Ausdruck die „id“ als Attribut und „message“ als Teilwert verwendet. Dadurch werden zwei Elemente gefunden („Benutzer-ID darf nicht leer sein“ und „Passwort darf nicht leer sein“), da das Attribut „id“ mit „Nachricht“ beginnt.
Xpath=//*[contains(@id,'message')]

Im folgenden Ausdruck haben wir den „Text“ des Links als Attribut und „hier“ als Teilwert verwendet, wie im folgenden Screenshot gezeigt. Dadurch wird der Link („hier“) gefunden, da der Text „hier“ angezeigt wird.
Xpath=//*[contains(text(),'here')]
Xpath=//*[contains(@href,'guru99.com')]

3) Verwendung von ODER und UND
Im OR-Ausdruck werden zwei Bedingungen verwendet, nämlich ob die erste Bedingung ODER die zweite Bedingung wahr sein soll. Dies gilt auch, wenn eine der Bedingungen zutrifft oder möglicherweise beide. Bedeutet, dass eine beliebige Bedingung wahr sein muss, um das Element zu finden.
Im folgenden XPath-Ausdruck werden die Elemente identifiziert, deren einzelne oder beide Bedingungen wahr sind.
Xpath=//*[@type='submit' or @name='btnReset']
Hervorhebung beider Elemente: „LOGIN“-Element mit dem Attribut „type“ und „RESET“-Element mit dem Attribut „name“.

Im AND-Ausdruck werden zwei Bedingungen verwendet. Beide Bedingungen müssen wahr sein, um das Element zu finden. Das Element kann nicht gefunden werden, wenn eine Bedingung falsch ist.
Xpath=//input[@type='submit' and @name='btnLogin']
Im folgenden Ausdruck wird das Element „LOGIN“ hervorgehoben, da es sowohl das Attribut „Typ“ als auch „Name“ hat.

4) Xpath beginnt mit
XPath beginnt mit() ist eine Funktion, die zum Suchen von Webelementen verwendet wird, deren Attributwert sich beim Aktualisieren oder durch andere dynamische Vorgänge auf der Webseite ändert. Bei dieser Methode wird der Anfangstext des Attributs abgeglichen, um das Element zu finden, dessen Attributwert sich dynamisch ändert. Sie können auch Elemente finden, deren Attributwert statisch ist (sich nicht ändert).
Beispiel: Angenommen, die ID eines bestimmten Elements ändert sich dynamisch wie folgt:
Id=“ message12″
Id=“ message345″
Id=“ message8769″
und so weiter.. aber der ursprüngliche Text ist derselbe. In diesem Fall verwenden wir den Start-with-Ausdruck.
Im folgenden Ausdruck gibt es zwei Elemente mit einer ID, die mit „Nachricht“ beginnt (z. B. „Benutzer-ID darf nicht leer sein“ und „Passwort darf nicht leer sein“). Im folgenden Beispiel findet XPath diejenigen Elemente, deren „ID“ mit „Nachricht“ beginnt.
Xpath=//label[starts-with(@id,'message')]

5) XPath Text()-Funktion
Das XPath text()-Funktion ist eine integrierte Funktion des Selenium-Webtreibers, die zum Lokalisieren von Elementen basierend auf dem Text eines Webelements verwendet wird. Sie hilft dabei, die genauen Textelemente zu finden und lokalisiert die Elemente innerhalb der Menge der Textknoten. Die zu lokalisierenden Elemente sollten in Zeichenfolgenform vorliegen.
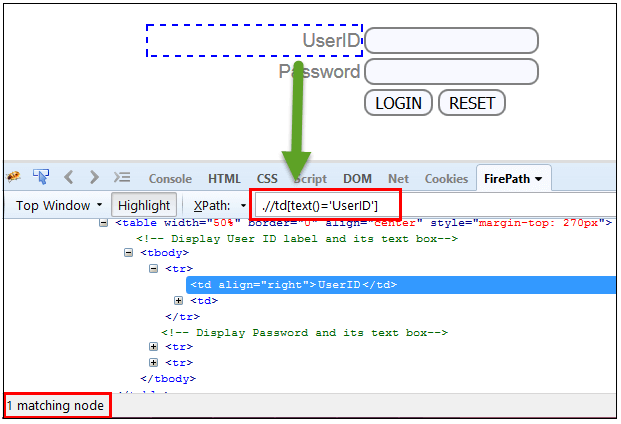
In diesem Ausdruck finden wir mit der Textfunktion das Element mit der genauen Textübereinstimmung, wie unten gezeigt. In unserem Fall finden wir das Element mit dem Text „UserID“.
Xpath=//td[text()='UserID']
XPath-Achsenmethoden
Diese XPath-Achsenmethoden werden verwendet, um komplexe oder dynamische Elemente zu finden. Im Folgenden sehen wir uns einige dieser Methoden an.
Zur Veranschaulichung dieser XPath-Achsenmethode werden wir Folgendes verwenden: GuruDemo-Website der 99 Bank.
1) Folgen
Wählt alle Elemente im Dokument des aktuellen Knotens aus () [Das UserID-Eingabefeld ist der aktuelle Knoten], wie im folgenden Bildschirm gezeigt.
Xpath=//*[@type='text']//following::input

Es gibt 3 „Eingabe“-Knoten, die mithilfe der „folgenden“ Achsen übereinstimmen: Passwort, Login und Reset-Button. Wenn Sie sich auf ein bestimmtes Element konzentrieren möchten, können Sie die folgende XPath-Methode verwenden:
Xpath=//*[@type='text']//following::input[1]
Sie können den XPath entsprechend der Anforderung ändern, indem Sie [1],[2]…………usw. eingeben.
Mit der Eingabe „1“ findet der folgende Screenshot den bestimmten Knoten, der das Eingabefeldelement „Passwort“ ist.

2) Vorfahr
Die Vorfahren-Achse wählt alle Vorfahren-Elemente (Großeltern, Eltern usw.) des aktuellen Knotens aus, wie im folgenden Bildschirm gezeigt.
Im folgenden Ausdruck finden wir das Vorfahrenelement des aktuellen Knotens („ENTERPRISE TESTING“-Knoten).
Xpath=//*[text()='Enterprise Testing']//ancestor::div

Es gibt 13 „div“-Knoten, die mithilfe der „Vorfahren“-Achse übereinstimmen. Wenn Sie sich auf ein bestimmtes Element konzentrieren möchten, können Sie den folgenden XPath verwenden, in dem Sie die Nummer 1, 2 entsprechend Ihren Anforderungen ändern:
Xpath=//*[text()='Enterprise Testing']//ancestor::div[1]
Sie können den XPath entsprechend der Anforderung ändern, indem Sie [1], [2]………… usw. eingeben.
3) Kind
Wählt alle untergeordneten Elemente des aktuellen Knotens aus (Java), wie im folgenden Bildschirm gezeigt.
Xpath=//*[@id='java_technologies']//child::li

Es gibt 71 „li“-Knoten, die mithilfe der „untergeordneten“ Achse übereinstimmen. Wenn Sie sich auf ein bestimmtes Element konzentrieren möchten, können Sie den folgenden XPath verwenden:
Xpath=//*[@id='java_technologies']//child::li[1]
Sie können den xpath je nach Anforderung ändern, indem Sie [1],[2]…………usw. eingeben.
4) Vorhergehend
Wählen Sie alle Knoten aus, die vor dem aktuellen Knoten liegen, wie im folgenden Bildschirm gezeigt.
Im folgenden Ausdruck werden alle Eingabeelemente vor der Schaltfläche „LOGIN“ identifiziert Benutzeridentifikation und Passwort Eingabeelement.
Xpath=//*[@type='submit']//preceding::input
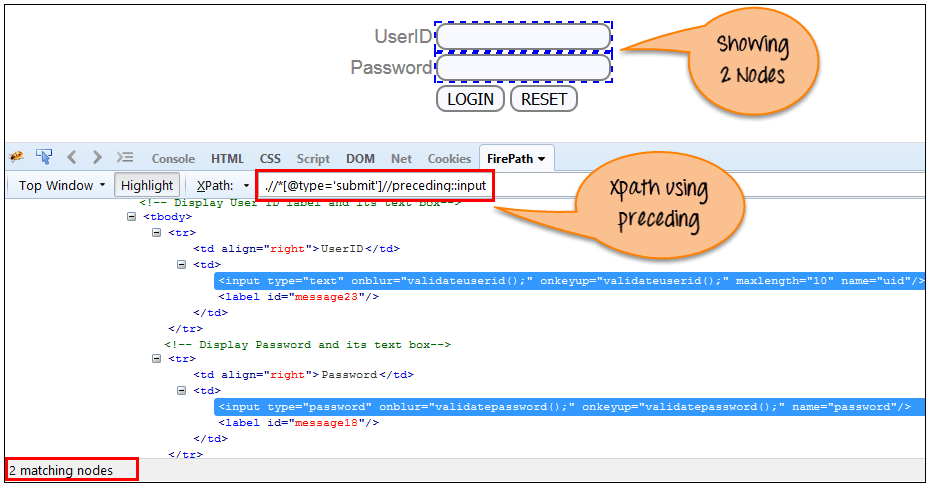
Es gibt zwei „Eingabe“-Knoten, die mithilfe der „vorhergehenden“ Achse übereinstimmen. Wenn Sie sich auf ein bestimmtes Element konzentrieren möchten, können Sie den folgenden XPath verwenden:
Xpath=//*[@type='submit']//preceding::input[1]
Sie können den xpath je nach Anforderung ändern, indem Sie [1],[2]…………usw. eingeben.
5) Nächstes Geschwister
Wählen Sie die folgenden Geschwister des Kontextknotens aus. Geschwister befinden sich auf derselben Ebene wie der aktuelle Knoten, wie im folgenden Bildschirm gezeigt. Das Element wird nach dem aktuellen Knoten gefunden.
xpath=//*[@type='submit']//following-sibling::input

Ein Eingabeknoten wird mithilfe der „folgenden Geschwister“-Achse abgeglichen.
6) Eltern
Wählt den übergeordneten Knoten des aktuellen Knotens aus, wie im folgenden Bildschirm gezeigt.
Xpath=//*[@id='rt-feature']//parent::div

Es gibt 65 „div“-Knoten, die mithilfe der „parent“-Achse übereinstimmen. Wenn Sie sich auf ein bestimmtes Element konzentrieren möchten, können Sie den folgenden XPath verwenden:
Xpath=//*[@id='rt-feature']//parent::div[1]
Sie können den XPath entsprechend der Anforderung ändern, indem Sie [1],[2]…………usw. eingeben.
7) Selbst
Wählt den aktuellen Knoten oder „selbst“ aus, was den Knoten selbst angibt, wie im folgenden Bildschirm gezeigt.

Ein Knotenabgleich mithilfe der „Selbst“-Achse. Es findet immer nur einen Knoten, da dieser ein Selbstelement darstellt.
Xpath =//*[@type='password']//self::input
8) Nachkomme
Wählt die Nachkommen des aktuellen Knotens aus, wie im folgenden Bildschirm gezeigt.
Im folgenden Ausdruck werden alle Elementnachkommen des aktuellen Elements (Rahmenelement „Hauptkörper umgeben“) identifiziert, d. h. unterhalb des Knotens (untergeordneter Knoten, Enkelknoten usw.).
Xpath=//*[@id='rt-feature']//descendant::a
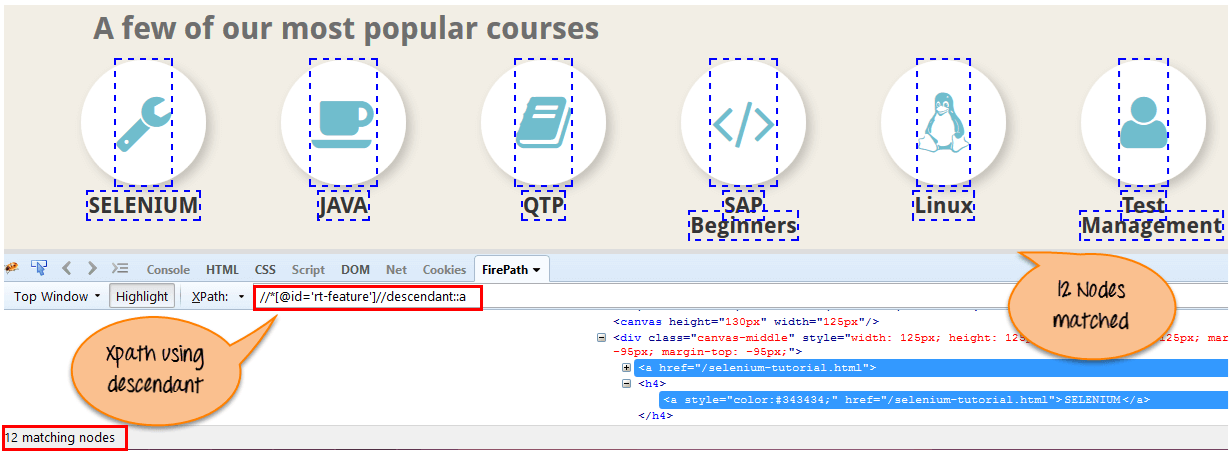
Es gibt 12 „Link“-Knoten, die mithilfe der „Abkömmlings“-Achse übereinstimmen. Wenn Sie sich auf ein bestimmtes Element konzentrieren möchten, können Sie den folgenden XPath verwenden:
Xpath=//*[@id='rt-feature']//descendant::a[1]
Sie können den XPath entsprechend der Anforderung ändern, indem Sie [1],[2]…………usw. eingeben.
Häufig gestellte Fragen
Zusammenfassung
XPath ist erforderlich, um ein Element auf der Webseite zu finden und eine Operation mit diesem bestimmten Element durchzuführen.
- Es gibt zwei Arten von Selenium XPath:
- Absoluter XPath
- Relativer XPath
- XPath-Achsen sind die Methoden, die verwendet werden, um dynamische Elemente zu finden, die sonst mit der normalen XPath-Methode nicht gefunden werden können
- Der XPath-Ausdruck wählt Knoten oder Knotenlisten auf der Grundlage von Attributen wie ID, Name, Klassenname usw. aus dem XML-Dokument aus.
Überprüfen Sie auch: - Selenium Tutorial für Anfänger: Erlernen Sie WebDriver in 7 Tagen