GLM in R: Verallgemeinertes lineares Modell & Logistische Regression
⚡ Intelligente Zusammenfassung
Das generalisierte lineare Modell (GLM) in R erweitert die gewöhnliche Regression auf binäre, zählbasierte oder nicht normalverteilte Zielgrößen. In diesem Beispiel wird ein logistisches GLM anhand des Datensatzes zum Erwachseneneinkommen erstellt und hinsichtlich Genauigkeit, Präzision, Trefferquote und ROC-Kurve evaluiert.

Was ist ein verallgemeinertes lineares Modell (GLM) in R?
A Verallgemeinertes lineares Modell (GLM) erweitert die gewöhnliche lineare Regression, sodass die Zielvariable einer anderen Verteilung als der Normalverteilung folgen kann. RSie können eines mit dem eingebauten glm() Funktion aus dem Statistikpaket.
Jedes GLM wird durch drei Komponenten definiert:
- Zufallskomponente: Die Wahrscheinlichkeitsverteilung der Zielvariablen, entnommen aus der Exponentialfamilie (Binomial-, Poisson-, Gamma-, Gauß-Verteilung und andere).
- Systematische Komponente: Der lineare Prädiktor ist die gewichtete Kombination Ihrer erklärenden Variablen.
- Linkfunktion: Die Funktion, die den Mittelwert der Antwortvariablen mit dem linearen Prädiktor verbindet, zum Beispiel die Logit-Linkfunktion für Binärdaten oder die Log-Linkfunktion für Zählwerte.
Diese Struktur macht das Modell „verallgemeinert“. Anstatt ein normalverteiltes Ergebnis zu erzwingen, legt man die korrekte Verteilung durch die Familie Argument und R schätzen die Koeffizienten mittels Maximum-Likelihood-Schätzung. Die logistische Regression ist im Grunde ein GLM mit einer Binomialverteilung und einer Logit-Linkfunktion und stellt daher den natürlichen Ausgangspunkt dar.
Was ist logistische Regression in R?
Die logistische Regression wird verwendet, um eine Klasse, also eine Wahrscheinlichkeit, vorherzusagen. Die logistische Regression kann ein binäres Ergebnis genau vorhersagen.
Stellen Sie sich vor, Sie möchten anhand vieler Merkmale vorhersagen, ob ein Kredit abgelehnt/angenommen wird. Die logistische Regression hat die Form 0/1. y = 0, wenn ein Kredit abgelehnt wird, y = 1, wenn er angenommen wird.
Ein logistisches Regressionsmodell unterscheidet sich vom linearen Regressionsmodell in zweierlei Hinsicht.
- Erstens akzeptiert die logistische Regression nur dichotomische (binäre) Eingaben als abhängige Variable (dh einen Vektor von 0 und 1).
- Zweitens wird das Ergebnis mithilfe einer probabilistischen Verknüpfungsfunktion, der sogenannten Sigmoid (logistische) Funktion aufgrund ihrer S-Form:

Die Ausgabe der Funktion liegt immer zwischen 0 und 1. Sehen Sie sich das Bild unten an
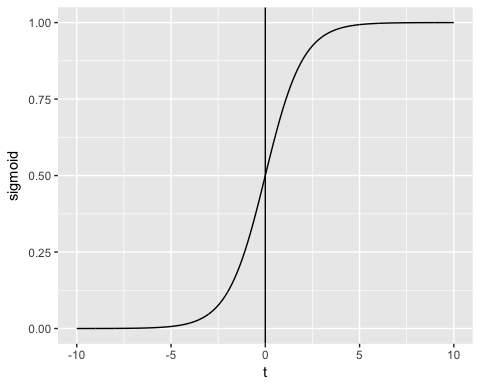
Die Sigmoidfunktion gibt Werte von 0 bis 1 zurück. Für die Klassifizierungsaufgabe benötigen wir eine diskrete Ausgabe von 0 oder 1.
Um einen kontinuierlichen Fluss in einen diskreten Wert umzuwandeln, können wir eine Entscheidungsgrenze von 0.5 festlegen. Alle Werte über diesem Schwellenwert werden als 1 klassifiziert

Nachdem die Link-Funktion nun klar ist, vergleichen Sie das verallgemeinerte Modell mit dem Ihnen bereits bekannten gewöhnlichen linearen Modell.
GLM vs. Lineare Regression: Wesentliche Unterschiede im R²
Bevor Sie Code schreiben, ist es hilfreich zu wissen, wann genau der Standard gilt. lineare Regression Die Funktion lm() ist nicht mehr angemessen und sollte durch glm() ersetzt werden.
| Eigenschaften | Lineare Regression (lm) | Generalisiertes lineares Modell (glm) |
|---|---|---|
| Antwortvariable | Stetig und unbeschränkt | Binär, Anzahl, Anteil oder positive stetige Variable |
| Fehlerverteilung | Normal | Jedes Mitglied der Exponentialfamilie |
| Link-Funktion | Identität (implizit) | Explizit: Logit, Logarithmus, Inverse, Probit |
| Schätzmethode | Gewöhnliche kleinste Quadrate | Maximum-Likelihood-Schätzung (IRLS) |
| Varianzannahme | Konstant über alle Beobachtungen hinweg | Darf vom Mittelwert abhängen |
| Gütemaß | R-Quadrat | AIC und Restabweichung |
| R-Funktion | lm(Formel, Daten) | glm(Formel, Daten, Familie) |
Kurz gesagt: Verwenden Sie `lm()`, wenn das Ergebnis eine normalverteilte Messung ist, und `glm()`, wenn das Ergebnis eine Ja/Nein-Entscheidung ist – eine Aufgabe, die Sie andernfalls auch einem anderen Programm überlassen könnten. Entscheidungsbaum Klassifikator, eine Ereigniszählung oder eine strikt positive Größe, deren Streuung mit ihrem Mittelwert wächst.
Wie man ein verallgemeinertes lineares Modell (GLM) in R erstellt
Nachdem die Theorie geklärt ist, wird im weiteren Verlauf dieses Tutorials ein binomiales GLM vollständig auf einen realen Datensatz angewendet.
Verwenden wir die Erwachsenen Datensatz zur Veranschaulichung der logistischen Regression. Der Datensatz „Erwachsene“ eignet sich hervorragend für die Klassifizierungsaufgabe. Ziel ist es, vorherzusagen, ob das jährliche Einkommen einer Person in US-Dollar 50,000 übersteigt. Der Datensatz umfasst 48,842 Beobachtungen und zehn Variablen.
- Alter: Alter der Person. Numerisch
- Bildung: Bildungsniveau des Einzelnen. Faktor.
- Familienstand: MariGesamtstatus des Individuums. Faktor, z. B. nie verheiratet, verheirateter Lebenspartner, …
- Geschlecht: Geschlecht der Person. Faktor, also männlich oder weiblich
- Einkommen: Target variabel. Einkommen über oder unter 50K. Faktor d. h. >50K, <=50K
unter anderem
library(dplyr) data_adult <-read.csv("https://raw.githubusercontent.com/guru99-edu/R-Programming/master/adult.csv") glimpse(data_adult)
Ausgang:
Observations: 48,842 Variables: 10 $ x <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,... $ age <int> 25, 38, 28, 44, 18, 34, 29, 63, 24, 55, 65, 36, 26... $ workclass <fctr> Private, Private, Local-gov, Private, ?, Private,... $ education <fctr> 11th, HS-grad, Assoc-acdm, Some-college, Some-col... $ educational.num <int> 7, 9, 12, 10, 10, 6, 9, 15, 10, 4, 9, 13, 9, 9, 9,... $ marital.status <fctr> Never-married, Married-civ-spouse, Married-civ-sp... $ race <fctr> Black, White, White, Black, White, White, Black, ... $ gender <fctr> Male, Male, Male, Male, Female, Male, Male, Male,... $ hours.per.week <int> 40, 50, 40, 40, 30, 30, 40, 32, 40, 10, 40, 40, 39... $ income <fctr> <=50K, <=50K, >50K, >50K, <=50K, <=50K, <=50K, >5...
Wir werden wie folgt vorgehen:
- Schritt 1: Kontinuierliche Variablen prüfen
- Schritt 2: Faktorvariablen prüfen
- Schritt 3: Feature-Engineering
- Schritt 4: Zusammenfassende Statistik
- Schritt 5: Trainings-/Testset
- Schritt 6: Erstellen Sie das Modell
- Schritt 7: Bewerten Sie die Leistung des Modells
- Schritt 8: Verbessern Sie das Modell
Ihre Aufgabe besteht darin, vorherzusagen, welche Person einen Umsatz von mehr als 50 erzielen wird.
In diesem Tutorial wird jeder Schritt detailliert beschrieben, um eine Analyse an einem realen Datensatz durchzuführen.
Schritt 1) Überprüfen Sie kontinuierliche Variablen
Im ersten Schritt sehen Sie die Verteilung der kontinuierlichen Variablen.
continuous <-select_if(data_adult, is.numeric) summary(continuous)
Code Erläuterung
- kontinuierlich <- select_if(data_adult, is.numeric): Verwenden Sie die Funktion select_if() aus der dplyr-Bibliothek, um nur die numerischen Spalten auszuwählen
- Zusammenfassung (kontinuierlich): Drucken Sie die zusammenfassende Statistik
Ausgang:
## X age educational.num hours.per.week ## Min. : 1 Min. :17.00 Min. : 1.00 Min. : 1.00 ## 1st Qu.:11509 1st Qu.:28.00 1st Qu.: 9.00 1st Qu.:40.00 ## Median :23017 Median :37.00 Median :10.00 Median :40.00 ## Mean :23017 Mean :38.56 Mean :10.13 Mean :40.95 ## 3rd Qu.:34525 3rd Qu.:47.00 3rd Qu.:13.00 3rd Qu.:45.00 ## Max. :46033 Max. :90.00 Max. :16.00 Max. :99.00
Aus der obigen Tabelle können Sie ersehen, dass die Daten völlig unterschiedliche Skalen aufweisen und dass es bei den Stunden pro Woche große Ausreißer gibt (sehen Sie sich also das letzte Quartil und den Maximalwert an).
Sie können das Problem in den folgenden zwei Schritten lösen:
- Stellen Sie die Verteilung der Stunden pro Woche grafisch dar.
- Standardisieren Sie die kontinuierlichen Variablen
- Plotten Sie die Verteilung
Schauen wir uns die Verteilung der Stunden pro Woche genauer an
# Histogram with kernel density curve library(ggplot2) ggplot(continuous, aes(x = hours.per.week)) + geom_density(alpha = .2, fill = "#FF6666")
Ausgang:

Die Variable hat viele Ausreißer und eine nicht gut definierte Verteilung. Sie können dieses Problem teilweise lösen, indem Sie die oberen 0.01 Prozent der Stunden pro Woche löschen.
Grundlegende Syntax des Quantils:
quantile(variable, percentile) arguments: -variable: Select the variable in the data frame to compute the percentile -percentile: Can be a single value between 0 and 1 or multiple value. If multiple, use this format: `c(A,B,C, ...) - `A`,`B`,`C` and `...` are all integer from 0 to 1.
Wir berechnen das 99. Perzentil der wöchentlichen Arbeitsstunden.
top_one_percent <- quantile(data_adult$hours.per.week, .99)
top_one_percent
Code Erläuterung
- quantile(data_adult$hours.per.week, .99): Berechnet das 99. Perzentil der wöchentlichen Arbeitszeit
Ausgang:
## 99% ## 80
99 Prozent der Bevölkerung arbeiten weniger als 80 Stunden pro Woche.
Sie können die Beobachtungen über diesem Schwellenwert löschen. Sie verwenden den Filter aus dem dplyr Bibliothek.
data_adult_drop <-data_adult %>% filter(hours.per.week<top_one_percent) dim(data_adult_drop)
Ausgang:
## [1] 45537 10
- Standardisieren Sie die kontinuierlichen Variablen
Sie können jede Spalte standardisieren, um die Leistung zu verbessern, da Ihre Daten nicht den gleichen Maßstab haben. Sie können die Funktion mutate_if aus der dplyr-Bibliothek verwenden. Die grundlegende Syntax lautet:
mutate_if(df, condition, funs(function)) arguments: -`df`: Data frame used to compute the function - `condition`: Statement used. Do not use parenthesis - funs(function): Return the function to apply. Do not use parenthesis for the function
Sie können die numerischen Spalten wie folgt standardisieren:
data_adult_rescale <- data_adult_drop %>% mutate_if(is.numeric, funs(as.numeric(scale(.)))) head(data_adult_rescale)
Code Erläuterung
- mutate_if(is.numeric, funs(scale)): Die Bedingung ist nur eine numerische Spalte und die Funktion ist skaliert
Ausgang:
## X age workclass education educational.num ## 1 -1.732680 -1.02325949 Private 11th -1.22106443 ## 2 -1.732605 -0.03969284 Private HS-grad -0.43998868 ## 3 -1.732530 -0.79628257 Local-gov Assoc-acdm 0.73162494 ## 4 -1.732455 0.41426100 Private Some-college -0.04945081 ## 5 -1.732379 -0.34232873 Private 10th -1.61160231 ## 6 -1.732304 1.85178149 Self-emp-not-inc Prof-school 1.90323857 ## marital.status race gender hours.per.week income ## 1 Never-married Black Male -0.03995944 <=50K ## 2 Married-civ-spouse White Male 0.86863037 <=50K ## 3 Married-civ-spouse White Male -0.03995944 >50K ## 4 Married-civ-spouse Black Male -0.03995944 >50K ## 5 Never-married White Male -0.94854924 <=50K ## 6 Married-civ-spouse White Male -0.76683128 >50K
Schritt 2) Überprüfen Sie die Faktorvariablen
Dieser Schritt hat zwei Ziele:
- Überprüfen Sie die Ebene in jeder kategorialen Spalte
- Definieren Sie neue Ebenen
Wir werden diesen Schritt in drei Teile unterteilen:
- Wählen Sie die kategorialen Spalten aus
- Speichern Sie das Balkendiagramm jeder Spalte in einer Liste
- Drucken Sie die Grafiken aus
Wir können die Faktorspalten mit dem folgenden Code auswählen:
# Select categorical column factor <- data.frame(select_if(data_adult_rescale, is.factor)) ncol(factor)
Code Erläuterung
- data.frame(select_if(data_adult, is.factor)): Wir speichern die Faktorspalten in Faktor in einem Datenrahmentyp. Die Bibliothek ggplot2 erfordert ein Datenrahmenobjekt.
Ausgang:
## [1] 6
Der Datensatz enthält 6 kategoriale Variablen
Der zweite Schritt ist anspruchsvoller. Sie möchten für jede Spalte des Datenrahmens „Faktor“ ein Balkendiagramm erstellen. Es ist ratsam, diesen Prozess zu automatisieren, insbesondere bei einer großen Anzahl von Spalten.
library(ggplot2) # Create graph for each column graph <- lapply(names(factor), function(x) ggplot(factor, aes(get(x))) + geom_bar() + theme(axis.text.x = element_text(angle = 90)))
Code Erläuterung
- lapply(): Verwenden Sie die Funktion lapply(), um eine Funktion in allen Spalten des Datensatzes zu übergeben. Sie speichern die Ausgabe in einer Liste
- Funktion(x): Die Funktion wird für jedes x abgearbeitet. Hier sind x die Spalten
- ggplot(factor, aes(get(x))) + geom_bar()+ theme(axis.text.x = element_text(angle = 90)): Erstellen Sie ein Balkendiagramm für jedes x-Element. Hinweis: Um x als Spalte zurückzugeben, müssen Sie es in get() einschließen.
Der letzte Schritt ist relativ einfach. Sie möchten die 6 Grafiken ausdrucken.
# Print the graph
graph
Ausgang:
## [[1]]

## ## [[2]]

## ## [[3]]

## ## [[4]]

## ## [[5]]

## ## [[6]]

Hinweis: Verwenden Sie die Schaltfläche „Weiter“, um zum nächsten Diagramm zu navigieren

Schritt 3) Feature-Engineering
Zwei kategoriale Variablen weisen mehr Ausprägungen auf, als das Modell benötigt. Sie werden diese in breitere, besser definierte Kategorien umgruppieren.
Neufassung der Bildung
Aus der obigen Grafik können Sie ersehen, dass die Variable Bildung 16 Stufen hat. Dies ist erheblich, und einige Ebenen weisen eine relativ geringe Anzahl von Beobachtungen auf. Wenn Sie die Menge an Informationen, die Sie aus dieser Variable erhalten können, verbessern möchten, können Sie sie auf eine höhere Ebene umwandeln. Sie bilden nämlich größere Gruppen mit ähnlichem Bildungsniveau. Beispielsweise wird ein niedriges Bildungsniveau in einen Schulabbruch umgewandelt. Höhere Bildungsstufen werden auf Master umgestellt.
Hier ist das Detail:
| Altes Niveau | Neues level |
|---|---|
| vorschulisch | aussteigen |
| 10. | Aussteiger |
| 11. | Aussteiger |
| 12. | Aussteiger |
| 1.-4 | Aussteiger |
| 5th-6th | Aussteiger |
| 7th-8th | Aussteiger |
| 9. | Aussteiger |
| HS-Grad | HighGrad |
| Einige College | Gemeinschaft |
| Assoc-acdm | Gemeinschaft |
| Assoc-voc | Gemeinschaft |
| Junggesellen | Junggesellen |
| Masters | Masters |
| Prof-Schule | Masters |
| Doktor | PhD |
recast_data <- data_adult_rescale %>% select(-X) %>% mutate(education = factor(ifelse(education == "Preschool" | education == "10th" | education == "11th" | education == "12th" | education == "1st-4th" | education == "5th-6th" | education == "7th-8th" | education == "9th", "dropout", ifelse(education == "HS-grad", "HighGrad", ifelse(education == "Some-college" | education == "Assoc-acdm" | education == "Assoc-voc", "Community", ifelse(education == "Bachelors", "Bachelors", ifelse(education == "Masters" | education == "Prof-school", "Master", "PhD")))))))
Code Erläuterung
- Wir verwenden das Verb mutate aus der dplyr-Bibliothek. Mit der Aussage ifelse verändern wir die Werte der Bildung
In der folgenden Tabelle erstellen Sie eine zusammenfassende Statistik, um zu sehen, wie viele Ausbildungsjahre (Z-Wert) durchschnittlich erforderlich sind, um den Bachelor, Master oder Ph.D. zu erreichen.
recast_data %>% group_by(education) %>% summarize(average_educ_year = mean(educational.num), count = n()) %>% arrange(average_educ_year)
Ausgang:
## # A tibble: 6 x 3 ## education average_educ_year count ## <fctr> <dbl> <int> ## 1 dropout -1.76147258 5712 ## 2 HighGrad -0.43998868 14803 ## 3 Community 0.09561361 13407 ## 4 Bachelors 1.12216282 7720 ## 5 Master 1.60337381 3338 ## 6 PhD 2.29377644 557
Neufassung MariTal-Status
Es ist auch möglich, niedrigere Ebenen für den Familienstand zu erstellen. Im folgenden Code ändern Sie die Ebene wie folgt:
| Altes Niveau | Neues level |
|---|---|
| Nie verheiratet | Nicht verheiratet |
| Verheirateter-Ehepartner-abwesend | Nicht verheiratet |
| Verheirateter AF-Ehepartner | Verheiratet |
| Verheirateter-Lebenspartner | |
| Getrennt | Getrennt |
| Geschieden | |
| Witwen | Witwe |
# Change level marry recast_data <- recast_data %>% mutate(marital.status = factor(ifelse(marital.status == "Never-married" | marital.status == "Married-spouse-absent", "Not_married", ifelse(marital.status == "Married-AF-spouse" | marital.status == "Married-civ-spouse", "Married", ifelse(marital.status == "Separated" | marital.status == "Divorced", "Separated", "Widow")))))
Sie können die Anzahl der Personen innerhalb jeder Gruppe überprüfen.
table(recast_data$marital.status)
Ausgang:
## ## Married Not_married Separated Widow ## 21165 15359 7727 1286
Schritt 4) Zusammenfassende Statistik
Es ist an der Zeit, einige Statistiken zu unseren Zielvariablen zu überprüfen. In der Grafik unten zählen Sie den Prozentsatz der Personen, die aufgrund ihres Geschlechts mehr als 50 verdienen.
# Plot gender income ggplot(recast_data, aes(x = gender, fill = income)) + geom_bar(position = "fill") + theme_classic()
Ausgang:

Prüfen Sie als Nächstes, ob die Herkunft der Person Einfluss auf ihr Einkommen hat.
# Plot origin income ggplot(recast_data, aes(x = race, fill = income)) + geom_bar(position = "fill") + theme_classic() + theme(axis.text.x = element_text(angle = 90))
Ausgang:
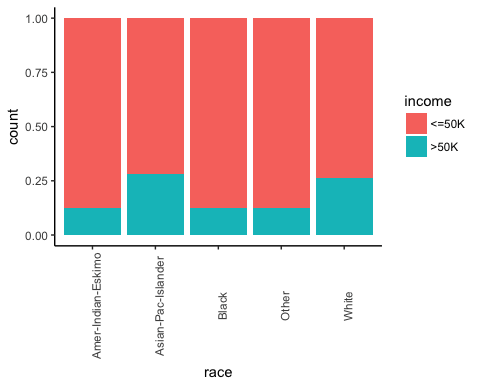
Die Anzahl der Arbeitszeiten nach Geschlecht.
# box plot gender working time ggplot(recast_data, aes(x = gender, y = hours.per.week)) + geom_boxplot() + stat_summary(fun.y = mean, geom = "point", size = 3, color = "steelblue") + theme_classic()
Ausgang:

Der Boxplot bestätigt, dass die Arbeitszeitverteilung auf unterschiedliche Gruppen passt. Im Boxplot gibt es keine homogenen Beobachtungen beider Geschlechter.
Sie können die Dichte der wöchentlichen Arbeitszeit nach Bildungsart überprüfen. Die Verteilungen weisen viele unterschiedliche Ausprägungen auf. Dies lässt sich wahrscheinlich durch die Art der Ausbildung erklären.tract in den USA.
# Plot distribution working time by education ggplot(recast_data, aes(x = hours.per.week)) + geom_density(aes(color = education), alpha = 0.5) + theme_classic()
Code Erläuterung
- ggplot(recast_data, aes( x= hours.per.week)): Ein Dichtediagramm erfordert nur eine Variable
- geom_density(aes(color = education), alpha =0.5): Das geometrische Objekt zur Steuerung der Dichte
Ausgang:

Um Ihre Gedanken zu bestätigen, können Sie eine Einbahnstraße durchführen ANOVA-Test:
anova <- aov(hours.per.week~education, recast_data) summary(anova)
Ausgang:
## Df Sum Sq Mean Sq F value Pr(>F) ## education 5 1552 310.31 321.2 <2e-16 *** ## Residuals 45531 43984 0.97 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Der ANOVA-Test bestätigt den Unterschied im Durchschnitt zwischen den Gruppen.
Nichtlinearität
Bevor Sie das Modell ausführen, können Sie prüfen, ob die Anzahl der geleisteten Arbeitsstunden mit dem Alter zusammenhängt.
library(ggplot2) ggplot(recast_data, aes(x = age, y = hours.per.week)) + geom_point(aes(color = income), size = 0.5) + stat_smooth(method = 'lm', formula = y~poly(x, 2), se = TRUE, aes(color = income)) + theme_classic()
Code Erläuterung
- ggplot(recast_data, aes(x = age, y = hours.per.week)): Legt die Ästhetik des Diagramms fest
- geom_point(aes(color= Einkommen), Größe =0.5): Konstruieren Sie das Punktdiagramm
- stat_smooth(): Fügen Sie die Trendlinie mit den folgenden Argumenten hinzu:
- method='lm': Zeichnen Sie den angepassten Wert auf, wenn der lineare Regression
- Formel = y~poly(x,2): Passen Sie eine polynomielle Regression an
- se = TRUE: Standardfehler hinzufügen
- aes(color= Einkommen): Brechen Sie das Modell nach Einkommen auf
Ausgang:

Kurz gesagt: Sie können Interaktionsterme im Modell testen, um den Nichtlinearitätseffekt zwischen der wöchentlichen Arbeitszeit und anderen Merkmalen zu erfassen. Es ist wichtig zu erkennen, unter welchen Bedingungen sich die Arbeitszeit unterscheidet.
Korrelation
Die nächste Prüfung besteht darin, die Korrelation zwischen den Variablen zu visualisieren. Sie wandeln den Typ der Faktorebene in einen numerischen Typ um, sodass Sie eine Wärmekarte zeichnen können, die den mit der Spearman-Methode berechneten Korrelationskoeffizienten enthält.
library(GGally) # Convert data to numeric corr <- data.frame(lapply(recast_data, as.integer)) # Plot the graphggcorr(corr, method = c("pairwise", "spearman"), nbreaks = 6, hjust = 0.8, label = TRUE, label_size = 3, color = "grey50")
Code Erläuterung
- data.frame(lapply(recast_data,as.integer)): Daten in numerisch konvertieren
- ggcorr() zeichnet die Heatmap mit den folgenden Argumenten:
- Methode: Methode zur Berechnung der Korrelation
- nbreaks = 6: Anzahl der Pausen
- hjust = 0.8: Kontrollposition des Variablennamens im Plot
- label = TRUE: Beschriftungen in der Mitte der Fenster hinzufügen
- label_size = 3: Größenbeschriftungen
- color = „grey50“): Farbe des Etiketts
Ausgang:
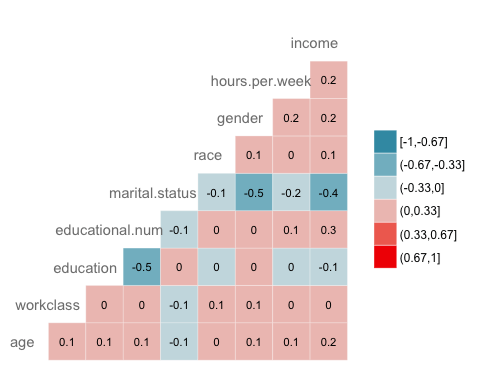
Schritt 5) Trainings-/Testset
Jeder wird beaufsichtigt Maschinelles Lernen Für diese Aufgabe müssen Sie die Daten in einen Trainings- und einen Testdatensatz aufteilen. Sie können die Funktion verwenden, die Sie in den anderen Tutorials zum überwachten Lernen erstellt haben, um einen Trainings-/Testdatensatz zu erstellen.
set.seed(1234) create_train_test <- function(data, size = 0.8, train = TRUE) { n_row = nrow(data) total_row = size * n_row train_sample <- 1: total_row if (train == TRUE) { return (data[train_sample, ]) } else { return (data[-train_sample, ]) } } data_train <- create_train_test(recast_data, 0.8, train = TRUE) data_test <- create_train_test(recast_data, 0.8, train = FALSE) dim(data_train)
Ausgang:
## [1] 36429 9
dim(data_test)
Ausgang:
## [1] 9108 9
Schritt 6) Erstellen Sie das Modell
Um die Leistungsfähigkeit des Algorithmus zu überprüfen, verwendet man die Funktion glm() aus dem Paket stats. Verallgemeinertes lineares Modell ist eine Sammlung von Modellen. Die grundlegende Syntax lautet:
glm(formula, data=data, family=linkfunction() Argument: - formula: Equation used to fit the model- data: dataset used - Family: - binomial: (link = "logit") - gaussian: (link = "identity") - Gamma: (link = "inverse") - inverse.gaussian: (link = "1/mu^2") - poisson: (link = "log") - quasi: (link = "identity", variance = "constant") - quasibinomial: (link = "logit") - quasipoisson: (link = "log")
Sie sind bereit, das Logistikmodell zu schätzen, um das Einkommensniveau auf eine Reihe von Merkmalen aufzuteilen.
formula <- income~. logit <- glm(formula, data = data_train, family = 'binomial') summary(logit)
Code Erläuterung
- Formel <- Einkommen ~ .: Erstellen Sie das passende Modell
- logit <- glm(formula, data = data_train, family = 'binomial'): Passen Sie ein Logistikmodell (family = 'binomial') an die data_train-Daten an.
- summary(logit): Drucken Sie die Zusammenfassung des Modells
Ausgang:
## ## Call: ## glm(formula = formula, family = "binomial", data = data_train) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -2.6456 -0.5858 -0.2609 -0.0651 3.1982 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|) ## (Intercept) 0.07882 0.21726 0.363 0.71675 ## age 0.41119 0.01857 22.146 < 2e-16 *** ## workclassLocal-gov -0.64018 0.09396 -6.813 9.54e-12 *** ## workclassPrivate -0.53542 0.07886 -6.789 1.13e-11 *** ## workclassSelf-emp-inc -0.07733 0.10350 -0.747 0.45499 ## workclassSelf-emp-not-inc -1.09052 0.09140 -11.931 < 2e-16 *** ## workclassState-gov -0.80562 0.10617 -7.588 3.25e-14 *** ## workclassWithout-pay -1.09765 0.86787 -1.265 0.20596 ## educationCommunity -0.44436 0.08267 -5.375 7.66e-08 *** ## educationHighGrad -0.67613 0.11827 -5.717 1.08e-08 *** ## educationMaster 0.35651 0.06780 5.258 1.46e-07 *** ## educationPhD 0.46995 0.15772 2.980 0.00289 ** ## educationdropout -1.04974 0.21280 -4.933 8.10e-07 *** ## educational.num 0.56908 0.07063 8.057 7.84e-16 *** ## marital.statusNot_married -2.50346 0.05113 -48.966 < 2e-16 *** ## marital.statusSeparated -2.16177 0.05425 -39.846 < 2e-16 *** ## marital.statusWidow -2.22707 0.12522 -17.785 < 2e-16 *** ## raceAsian-Pac-Islander 0.08359 0.20344 0.411 0.68117 ## raceBlack 0.07188 0.19330 0.372 0.71001 ## raceOther 0.01370 0.27695 0.049 0.96054 ## raceWhite 0.34830 0.18441 1.889 0.05894 . ## genderMale 0.08596 0.04289 2.004 0.04506 * ## hours.per.week 0.41942 0.01748 23.998 < 2e-16 *** ## ---## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## (Dispersion parameter for binomial family taken to be 1) ## ## Null deviance: 40601 on 36428 degrees of freedom ## Residual deviance: 27041 on 36406 degrees of freedom ## AIC: 27087 ## ## Number of Fisher Scoring iterations: 6
Die Zusammenfassung unseres Modells enthüllt interessante Informationen. Die Leistung einer logistischen Regression wird anhand spezifischer Schlüsselmetriken bewertet.
- AIC (Akaike Information Criteria): Dies ist das Äquivalent von R2 in der logistischen Regression. Es misst die Anpassung, wenn eine Strafe auf die Anzahl der Parameter angewendet wird. Kleiner AIC Werte zeigen an, dass das Modell näher an der Wahrheit liegt.
- Nullabweichung: Passt das Modell nur mit dem Achsenabschnitt an. Der Freiheitsgrad beträgt n-1. Wir können es als Chi-Quadrat-Wert interpretieren (angepasster Wert, der sich vom tatsächlichen Wert der Hypothesenprüfung unterscheidet).
- Restabweichung: Modell mit allen Variablen. Es wird auch als Chi-Quadrat-Hypothesetest interpretiert.
- Anzahl der Fisher-Scoring-Iterationen: Anzahl der Iterationen vor der Konvergenz.
Die Ausgabe der Funktion glm() wird in einer Liste gespeichert. Der folgende Code zeigt alle Elemente, die in der Logit-Variablen verfügbar sind, die wir zur Auswertung der logistischen Regression erstellt haben.
# Die Liste ist sehr lang. Geben Sie nur die ersten drei Elemente aus
lapply(logit, class)[1:3]
Ausgang:
## $coefficients ## [1] "numeric" ## ## $residuals ## [1] "numeric" ## ## $fitted.values ## [1] "numeric"
Jeder Wert kann ex seintracted mit dem $-Zeichen gefolgt vom Namen der Metriken. Zum Beispiel haben Sie das Modell als logit gespeichert. Um z. B.tracBei den AIC-Kriterien verwenden Sie:
logit$aic
Ausgang:
## [1] 27086.65
Schritt 7) Bewerten Sie die Leistung des Modells
Verwirrung Matrix
Das Verwirrung Matrix ist eine bessere Wahl zur Bewertung der Klassifizierungsleistung im Vergleich zu den verschiedenen Metriken, die Sie zuvor gesehen haben. Die allgemeine Idee besteht darin, zu zählen, wie oft Wahre Instanzen als Falsch klassifiziert werden.

Um die Verwirrungsmatrix zu berechnen, benötigen Sie zunächst eine Reihe von Vorhersagen, damit diese mit den tatsächlichen Zielen verglichen werden können.
predict <- predict(logit, data_test, type = 'response') # confusion matrix table_mat <- table(data_test$income, predict > 0.5) table_mat
Code Erläuterung
- Predict(logit,data_test, type = 'response'): Berechnen Sie die Vorhersage für den Testsatz. Legen Sie type = 'response' fest, um die Antwortwahrscheinlichkeit zu berechnen.
- table(data_test$income, Predict > 0.5): Berechnen Sie die Verwirrungsmatrix. Vorhersage > 0.5 bedeutet, dass 1 zurückgegeben wird, wenn die vorhergesagten Wahrscheinlichkeiten über 0.5 liegen, andernfalls 0.
Ausgang:
## ## FALSE TRUE ## <=50K 6310 495 ## >50K 1074 1229
Jede Zeile einer Konfusionsmatrix repräsentiert ein tatsächliches Ziel, während jede Spalte ein vorhergesagtes Ziel darstellt. Die erste Zeile dieser Matrix betrachtet das Einkommen unter 50 (die negative Klasse): 6,310 Beobachtungen wurden korrekt als Personen mit einem Einkommen unter 50 klassifiziert (Wahr-negativ), während 495 fälschlicherweise als über 50 eingestuft wurden (Falsch positivDie zweite Zeile berücksichtigt das Einkommen über 50: 1,229 wurden korrekt identifiziert (Richtig positiv), während 1,074 verpasst wurden (Falsch negativ).
Sie können das Modell berechnen Genauigkeit durch Summieren des wahren Positivs + des wahren Negativs über die Gesamtbeobachtung

accuracy_Test <- sum(diag(table_mat)) / sum(table_mat) accuracy_Test
Code Erläuterung
- sum(diag(table_mat)): Summe der Diagonalen
- sum(table_mat): Summe der Matrix.
Ausgang:
## [1] 0.8277339
Das Modell scheint ein Problem zu haben: Es liefert zu viele falsch negative Ergebnisse. Dies wird als … bezeichnet. Genauigkeitstest-ParadoxonWir haben bereits festgestellt, dass die Genauigkeit das Verhältnis der korrekten Vorhersagen zur Gesamtzahl der Fälle ist. Eine relativ hohe Genauigkeit kann ein nutzloses Modell darstellen. Dies geschieht, wenn eine Klasse dominant ist. Betrachtet man die Konfusionsmatrix, sieht man, dass die meisten Fälle als korrekt negativ klassifiziert wurden. Stellen Sie sich nun vor, das Modell würde jede Beobachtung als negativ klassifizieren (d. h. unter 50). Sie würden immer noch eine Genauigkeit von etwa 75 Prozent (6,805 / 9,108) erreichen. Ihr Modell schneidet zwar besser ab, hat aber Schwierigkeiten, korrekt positive von korrekt negativen Fällen zu unterscheiden.
In einer solchen Situation ist es vorzuziehen, eine präzisere Metrik zu verwenden. Wir können uns Folgendes ansehen:
- Präzision=TP/(TP+FP)
- Rückruf=TP/(TP+FN)
Präzision vs. Rückruf
Präzision untersucht die Genauigkeit der positiven Vorhersage. Erinnern ist das Verhältnis der positiven Instanzen, die vom Klassifikator korrekt erkannt werden;
Sie können zwei Funktionen erstellen, um diese beiden Metriken zu berechnen
- Konstruieren Sie Präzision
precision <- function(matrix) { # True positive tp <- matrix[2, 2] # false positive fp <- matrix[1, 2] return (tp / (tp + fp)) }
Code Erläuterung
- mat[1,1]: Gibt die erste Zelle der ersten Spalte des Datenrahmens zurück, also das wahre Positive
- mat[1,2]; Gibt die erste Zelle der zweiten Spalte des Datenrahmens zurück, also das falsche Positiv
recall <- function(matrix) { # true positive tp <- matrix[2, 2]# false positive fn <- matrix[2, 1] return (tp / (tp + fn)) }
Code Erläuterung
- mat[1,1]: Gibt die erste Zelle der ersten Spalte des Datenrahmens zurück, also das wahre Positive
- mat[2,1]; Gibt die zweite Zelle der ersten Spalte des Datenrahmens zurück, also das falsche Negativ
Sie können Ihre Funktionen testen
prec <- precision(table_mat) prec rec <- recall(table_mat) rec
Ausgang:
## [1] 0.712877 ## [2] 0.5336518
Lesen Sie diese beiden Zahlen aufmerksam. Die Präzision beträgt 0.71. Das bedeutet, dass das Modell in 71 Prozent der Fälle korrekt vorhersagt, dass eine Person über 50 verdient. Die Trefferquote (Recall) liegt bei 0.53. Das Modell erkennt also nur 53 Prozent der Personen, die tatsächlich über 50 verdienen.
Sie können die erstellen ![]() Bewertung basierend auf Präzision und Erinnerung. Der
Bewertung basierend auf Präzision und Erinnerung. Der ![]() ist ein harmonisches Mittel dieser beiden Metriken, was bedeutet, dass den niedrigeren Werten mehr Gewicht beigemessen wird.
ist ein harmonisches Mittel dieser beiden Metriken, was bedeutet, dass den niedrigeren Werten mehr Gewicht beigemessen wird.

f1 <- 2 * ((prec * rec) / (prec + rec)) f1
Ausgang:
## [1] 0.6103799
Kompromiss zwischen Präzision und Rückruf
Es ist unmöglich, gleichzeitig eine hohe Präzision und einen hohen Rückruf zu erreichen.
Wenn wir die Präzision erhöhen, wird die richtige Person besser vorhergesagt, wir würden jedoch viele davon übersehen (geringere Erinnerung). In manchen Situationen bevorzugen wir eine höhere Präzision als einen Rückruf. Es besteht ein konkaver Zusammenhang zwischen Präzision und Erinnerung.
- Stellen Sie sich vor, Sie müssen vorhersagen, ob ein Patient eine Krankheit hat. Sie möchten so präzise wie möglich sein.
- Wenn Sie potenziell betrügerische Personen auf der Straße mithilfe der Gesichtserkennung erkennen müssen, wäre es besser, viele als betrügerisch eingestufte Personen zu erfassen, auch wenn die Präzision gering ist. Die Polizei kann die nicht betrügerische Person freilassen.
Die ROC-Kurve
Das Empfänger Operating-Charakteristik Kurve ist ein weiteres gängiges Werkzeug, das bei der binären Klassifizierung verwendet wird. Sie ist der Präzisions-/Erinnerungskurve sehr ähnlich, aber anstatt Präzision gegen Erinnerung darzustellen, zeigt die ROC-Kurve die wahre positive Rate (d. h. Erinnerung) gegenüber der falsch positiven Rate. Die Falsch-Positiv-Rate ist das Verhältnis der negativen Fälle, die fälschlicherweise als positiv eingestuft werden. Er entspricht eins minus der echten Negativrate. Man spricht auch von der True-Negativ-Rate Spezifität. Daher die ROC-Kurvendiagramme Empfindlichkeit (Rückruf) versus 1-Spezifität
Um die ROC-Kurve zu erstellen, müssen wir ein Paket namens ROCR installieren. Wir finden es im Conda-Verzeichnis. . Sie können den Code eingeben:
conda install -c r r-rocr --yes
Wir können den ROC mit den Funktionen „prediction()“ und „performance()“ darstellen.
library(ROCR) ROCRpred <- prediction(predict, data_test$income) ROCRperf <- performance(ROCRpred, 'tpr', 'fpr') plot(ROCRperf, colorize = TRUE, text.adj = c(-0.2, 1.7))
Code Erläuterung
- Vorhersage (Vorhersage, Datentest $ Einkommen): Die ROCR-Bibliothek muss ein Vorhersageobjekt erstellen, um die Eingabedaten zu transformieren
- performance(ROCRpred, 'tpr','fpr'): Gibt die beiden Kombinationen zurück, die im Diagramm erzeugt werden sollen. Hier werden tpr und fpr konstruiert. Um die Plotgenauigkeit und den Abruf zusammen zu erreichen, verwenden Sie „prec“ und „rec“.
Ausgang:
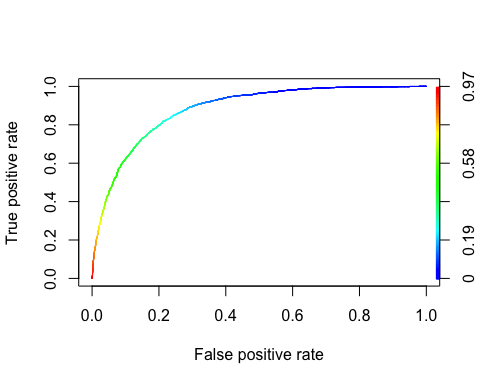
Schritt 8) Verbessern Sie das Modell
Sie können versuchen, dem Modell durch die Interaktion zwischen Nichtlinearität hinzuzufügen
- Alter und Stunden pro Woche
- Geschlecht und Stunden pro Woche.
Anschließend vergleicht man den F1-Wert beider Modelle.
formula_2 <- income~age: hours.per.week + gender: hours.per.week + . logit_2 <- glm(formula_2, data = data_train, family = 'binomial') predict_2 <- predict(logit_2, data_test, type = 'response') table_mat_2 <- table(data_test$income, predict_2 > 0.5) precision_2 <- precision(table_mat_2) recall_2 <- recall(table_mat_2) f1_2 <- 2 * ((precision_2 * recall_2) / (precision_2 + recall_2)) f1_2
Ausgang:
## [1] 0.6109181
Der F1-Score ist etwas höher als der vorherige. Sie können weiter mit den Daten arbeiten und versuchen, den Score zu übertreffen.
Wie man GLM-Koeffizienten und Odds Ratios in R interpretiert
Die in Schritt 6 gedruckte Übersichtstabelle enthält die Koeffizienten für die Log-Quoten Die Skala ist schwer zu erklären, insbesondere für ein nicht-technisches Publikum. Die Umrechnung in Chancenverhältnisse macht das Modell deutlich verständlicher.
Befolgen Sie diese vier Schritte.
- Die Koeffizienten werden exponentiert. Wenden Sie die Funktion exp() auf jede Schätzung an, sodass die Log-Odds zu multiplikativen Odds-Ratios werden.
- Füge ein Konfidenzintervall hinzu. Um das 95-Prozent-Intervall auf derselben Odds-Skala zu erhalten, kann die Funktion confint() in exp() eingebettet werden.
- Vergleiche jeden Wert mit 1. Ein Chancenverhältnis über 1 erhöht die Wahrscheinlichkeit der positiven Klasse, ein Wert unter 1 verringert sie, und ein Wert nahe 1 bedeutet, dass der Prädiktor nur wenig hinzufügt.
- Statistische Signifikanz prüfen. Interpretieren Sie nur Prädiktoren, deren p-Wert in der zusammenfassenden Ausgabe unter dem von Ihnen gewählten Schwellenwert liegt, typischerweise 0.05.
# Convert log-odds coefficients into odds ratios odds_ratio <- exp(coef(logit)) round(odds_ratio, 3) # Odds ratios with 95% confidence intervals exp(cbind(OddsRatio = coef(logit), confint(logit)))
Ausgabe wird gelesen. Der Koeffizient für Stunden pro Woche in unserem Modell beträgt 0.41942. Die Exponentiation ergibt exp(0.41942) = 1.52, was bedeutet, dass eine Erhöhung der wöchentlichen Arbeitszeit um eine Standardabweichung die Wahrscheinlichkeit, mehr als 50 zu verdienen, um etwa das 1.5-Fache erhöht, vorausgesetzt, alle anderen Variablen bleiben konstant.
Negative Koeffizienten funktionieren analog. Der Wert für marital.statusNot_married ist -2.50346, daher ist exp(-2.50346) = 0.08: Unverheiratete Personen haben eine Wahrscheinlichkeit von etwa 8 Prozent, verheiratet zu sein. Da die kontinuierlichen Prädiktoren in Schritt 1 standardisiert wurden, beschreiben Sie die Änderungen in Standardabweichungseinheiten, nicht in absoluten Stunden.
Hinweis für andere Familien: Exponentierte Koeffizienten sind nur dann Odds Ratios, wenn die Binomialverteilung mit Logit-Linkfunktion verwendet wird. Bei der Verteilung „poisson“ und einer Logit-Linkfunktion werden dieselben exp()-Werte stattdessen als Ratenverhältnisse interpretiert.
GLM in R: Kurzübersicht der Funktionen
Bewahren Sie diese Tabelle während des Programmierens neben sich auf. Sie listet alle in den acht obigen Schritten verwendeten Funktionen zusammen mit dem zugehörigen Paket und den erwarteten Argumenten auf.
| Verpackung | Ziel | Funktion | Argument |
|---|---|---|---|
| - | Erstellen Sie einen Trainings-/Testdatensatz | create_train_set() | Daten, Größe, Zug |
| glm | Trainieren Sie ein verallgemeinertes lineares Modell | glm() | Formel, Daten, Familie* |
| glm | Das Modell zusammenfassen | Zusammenfassung() | angepasstes Modell |
| Base | Machen Sie eine Vorhersage | vorhersagen() | angepasstes Modell, Datensatz, Typ = 'Antwort' |
| Base | Erstellen Sie eine Verwirrungsmatrix | Tisch() | y, vorhersagen() |
| Base | Genauigkeitswert erstellen | sum(diag(table())/sum(table() | |
| ROCR | ROC erstellen: Schritt 1 Vorhersage erstellen | Vorhersage() | vorhersagen(), y |
| ROCR | ROC erstellen: Schritt 2 Leistung erstellen | Leistung() | Vorhersage(), 'tpr', 'fpr' |
| ROCR | ROC erstellen: Schritt 3 Diagramm zeichnen | Handlung() | Leistung() |
Die andere GLM Folgende Familien stehen im Rahmen des Familienarguments zur Verfügung:
- Binomial: (Link = „Logit“)
- Gaussian: (link = “identity”)
- Gamma: (Link = „invers“)
- inverse.gaussian: (link = “1/mu^2”)
- Poisson: (Link = „Log“)
- quasi: (link = “identity”, variance = “constant”)
- quasibinomial: (link = “logit”)
- quasipoisson: (link = “log”)