DBMS-Normalisierung: 1NF-, 2NF-, 3NF-Datenbankbeispiel

Normalisierung auf den Punkt gebracht
Normalisierung ist der Prozess der Strukturierung einer Datenbank, um Redundanz zu reduzieren und die Konsistenz zu verbessern. Vereinfacht ausgedrückt werden dabei große, unübersichtliche Tabellen in kleinere, übersichtlichere Tabellen aufgeteilt. Dadurch wird sichergestellt, dass die Daten logisch gespeichert werden. Datenbanken sind effizient, leicht zu warten und frei von Duplikaten oder Fehlern.
Was ist Datenbanknormalisierung?
Datenbanknormalisierung ist eine Datenbankentwurfstechnik, die Datenredundanz reduziert und unerwünschte Merkmale wie Einfüge-, Aktualisierungs- und Löschanomalien eliminiert. Normalisierungsregeln teilen größere Tabellen in kleinere Tabellen auf und verknüpfen diese mithilfe von Beziehungen. Der Zweck der Normalisierung in SQL besteht darin, redundante (sich wiederholende) Daten zu eliminieren und sicherzustellen, dass Daten logisch gespeichert werden.
Der Erfinder der relationales Modell Edgar Codd schlug mit der Einführung der Ersten Normalform die Theorie der Normalisierung von Daten vor und erweiterte die Theorie mit der Zweiten und Dritten Normalform weiter. Later Er schloss sich Raymond F. Boyce an, um die Theorie der Boyce-Codd-Normalform zu entwickeln.
Warum brauchen wir Normalisierung?
Ohne Normalisierung werden Datenbanken schnell inkonsistent und redundant. Probleme wie Einfügungsanomalien (unvollständige Datensätze können nicht hinzugefügt werden), Update-Anomalien (Änderungen an einer Stelle spiegeln sich nicht überall wider) und Löschanomalien (Beim Entfernen von Daten werden versehentlich wertvolle Informationen gelöscht) treten häufig auf. Durch die Normalisierung werden diese Probleme vermieden, die Datenintegrität sichergestellt, Duplikate reduziert und die Datenbankverwaltung vereinfacht.
Welche Arten von Normalformen gibt es in DBMS?
Hier ist eine Liste der Normalformen in SQL:
- 1NF (Erste Normalform): Stellt sicher, dass die Datenbanktabelle so organisiert ist, dass jede Spalte atomare (unteilbare) Werte enthält und jeder Datensatz eindeutig ist. Dadurch werden sich wiederholende Gruppen vermieden und die Daten werden in Tabellen und Spalten strukturiert.
- 2NF (Zweite Normalform): Baut auf 1NF auf: Wir müssen redundante Daten aus einer Tabelle entfernen, die auf mehrere Zeilen angewendet wird. und platzieren Sie sie in separaten Tabellen. Es erfordert, dass alle Nichtschlüsselattribute auf dem Primärschlüssel voll funktionsfähig sind.
- 3NF (Dritte Normalform): Erweitert 2NF, indem sichergestellt wird, dass alle Nichtschlüsselattribute nicht nur auf dem Primärschlüssel voll funktionsfähig, sondern auch unabhängig voneinander sind. Dadurch wird die transitive Abhängigkeit beseitigt.
- BCNF (Boyce-Codd-Normalform): Eine Weiterentwicklung von 3NF, die Anomalien behebt, die von 3NF nicht behandelt werden. Es erfordert, dass jede Determinante ein Kandidatenschlüssel ist, was eine noch strengere Einhaltung der Normalisierungsregeln gewährleistet.
- 4NF (Vierte Normalform): Behandelt mehrwertige Abhängigkeiten. Dadurch wird sichergestellt, dass es in einem Datensatz nicht mehrere unabhängige, mehrwertige Fakten zu einer Entität gibt.
- 5NF (Fünfte Normalform): Auch als „Projection-Join Normal Form“ (PJNF) bekannt, bezieht es sich auf die Rekonstruktion von Informationen aus kleineren, unterschiedlich angeordneten Datenstücken.
- 6NF (Sechste Normalform): Theoretisch und nicht umfassend umgesetzt. Es befasst sich mit zeitlichen Daten (Verwaltung von Änderungen im Laufe der Zeit), indem Tabellen weiter zerlegt werden, um alle nicht-zeitlichen Redundanzen zu beseitigen.
Die Theorie der Datennormalisierung in MySQL Server wird noch weiterentwickelt. Diskussionen gibt es zum Beispiel schon am 6th Normalform. In den meisten praktischen Anwendungen erreicht die Normalisierung jedoch ihre beste Leistung in 3rd Normalform. Die Entwicklung der Normalisierung in SQL-Theorien wird unten dargestellt:
.png)
Datenbanknormalisierung mit Beispielen
Datenbank Beispiel für eine Normalisierung lässt sich anhand einer Fallstudie leicht nachvollziehen. Angenommen, eine Videobibliothek verwaltet eine Datenbank mit ausgeliehenen Filmen. Ohne jegliche Normalisierung in der Datenbank werden alle Informationen wie unten gezeigt in einer Tabelle gespeichert. Lassen Sie uns die Normalisierungsdatenbank anhand eines Normalisierungsbeispiels mit Lösung verstehen:

Hier sehen Sie Die Spalte „Ausgeliehene Filme“ enthält mehrere Werte. Kommen wir nun zu den ersten Normalformen:
Erste Normalform (1NF)
- Jede Tabellenzelle sollte einen einzelnen Wert enthalten.
- Jeder Datensatz muss eindeutig sein.
Die obige Tabelle in 1NF-
1NF-Beispiel

Bevor wir fortfahren, lassen Sie uns ein paar Dinge verstehen:
Was ist ein SCHLÜSSEL in SQL?
A SCHLÜSSEL in SQL ist ein Wert, der zur eindeutigen Identifizierung von Datensätzen in einer Tabelle verwendet wird. Ein SQL-SCHLÜSSEL ist eine einzelne Spalte oder eine Kombination mehrerer Spalten, die zur eindeutigen Identifizierung von Zeilen oder Tupeln in der Tabelle verwendet werden. Der SQL-Schlüssel wird zum Identifizieren doppelter Informationen verwendet und hilft außerdem dabei, eine Beziehung zwischen mehreren Tabellen in der Datenbank herzustellen.
Hinweis: Spalten in einer Tabelle, die NICHT zur eindeutigen Identifizierung eines Datensatzes verwendet werden, werden als Nicht-Schlüsselspalten bezeichnet.
Was ist ein Primärschlüssel?

Ein Primärwert ist ein einzelner Spaltenwert, der zur eindeutigen Identifizierung eines Datenbankeintrags verwendet wird.
Es verfügt über folgende Eigenschaften
- A Primärschlüssel kann nicht Null sein
- Ein Primärschlüsselwert muss eindeutig sein
- Die Primärschlüsselwerte sollten selten geändert werden
- Beim Einfügen eines neuen Datensatzes muss dem Primärschlüssel ein Wert zugewiesen werden.
Was ist ein zusammengesetzter Schlüssel?
Ein zusammengesetzter Schlüssel ist ein aus mehreren Spalten bestehender Primärschlüssel, der zur eindeutigen Identifizierung eines Datensatzes dient
In unserer Datenbank haben wir zwei Personen mit demselben Namen, Robert Phil, die jedoch an verschiedenen Orten leben.

Daher benötigen wir sowohl den vollständigen Namen als auch die Adresse, um einen Datensatz eindeutig zu identifizieren. Das ist ein zusammengesetzter Schlüssel.
Kommen wir zur zweiten Normalform 2NF
Zweite Normalform (2NF)
- Regel 1 – Seien Sie in 1NF
- Regel 2 - Einspaltiger Primärschlüssel, der funktional nicht von einer Teilmenge der Kandidatenschlüsselbeziehung abhängig ist
Es ist klar, dass wir nicht weiterkommen können, um unsere einfache Datenbank in 2 zu erstellennd Normalisierungsform, es sei denn, wir partitionieren die obige Tabelle.


Wir haben unsere 1NF-Tabelle in zwei Tabellen aufgeteilt, nämlich Tabelle 1 und Tabelle 2. Tabelle 1 enthält Mitgliedsinformationen. Tabelle 2 enthält Informationen zu ausgeliehenen Filmen.
Wir haben eine neue Spalte namens Membership_id eingeführt, die der Primärschlüssel für Tabelle 1 ist. Datensätze können in Tabelle 1 anhand der Mitgliedschafts-ID eindeutig identifiziert werden
Datenbank – Fremdschlüssel
In Tabelle 2 ist Membership_ID der Fremdschlüssel


Foreign Key verweist auf den Primärschlüssel einer anderen Tabelle! Es hilft, Ihre Tische zu verbinden
- Ein Fremdschlüssel kann einen anderen Namen haben als sein Primärschlüssel
- Es stellt sicher, dass Zeilen in einer Tabelle entsprechende Zeilen in einer anderen haben
- Im Gegensatz zum Primärschlüssel müssen sie nicht eindeutig sein. Meistens sind sie es nicht
- Fremdschlüssel können null sein, obwohl Primärschlüssel dies nicht können

Warum braucht man einen Fremdschlüssel?
Angenommen, ein Anfänger fügt einen Datensatz in Tabelle B ein, z

Sie können nur Werte in Ihren Fremdschlüssel einfügen, die im eindeutigen Schlüssel in der übergeordneten Tabelle vorhanden sind. Dies trägt zur referenziellen Integrität bei.
Das obige Problem kann gelöst werden, indem die Mitglieds-ID aus Tabelle2 als Fremdschlüssel der Mitglieds-ID aus Tabelle1 deklariert wird
Wenn nun jemand versucht, einen Wert in das Feld „Mitgliedschafts-ID“ einzufügen, der in der übergeordneten Tabelle nicht vorhanden ist, wird ein Fehler angezeigt!
Was sind transitive funktionale Abhängigkeiten?
Ein Transitiv funktionale Abhängigkeit Wenn Sie eine Nicht-Schlüsselspalte ändern, kann dies dazu führen, dass sich auch alle anderen Nicht-Schlüsselspalten ändern
Betrachten Sie die Tabelle 1. Durch Ändern der Nichtschlüsselspalte „Vollständiger Name“ kann sich die Anrede ändern.

Kommen wir zu 3NF
Dritte Normalform (3NF)
- Regel 1 – Seien Sie in 2NF
- Regel 2 – Hat keine transitiven funktionalen Abhängigkeiten
Um unsere 2NF-Tabelle in 3NF zu verschieben, müssen wir unsere Tabelle erneut teilen.
3NF-Beispiel
Unten finden Sie ein 3NF-Beispiel in einer SQL-Datenbank:


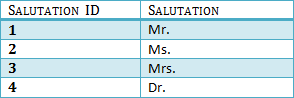
Wir haben unsere Tabellen noch einmal aufgeteilt und eine neue Tabelle erstellt, in der Anreden gespeichert sind.
Es gibt keine transitiven funktionalen Abhängigkeiten und daher ist unsere Tabelle in 3NF
In Tabelle 3 ist die Anrede-ID der Primärschlüssel, und in Tabelle 1 ist die Anrede-ID ein Fremdschlüssel für den Primärschlüssel in Tabelle 3
Jetzt ist unser kleines Beispiel auf einer Ebene, die nicht weiter zerlegt werden kann, um höhere Normalisierungsformen in DBMS zu erreichen. Tatsächlich ist es bereits in höheren Normalisierungsformen vorhanden. In komplexen Datenbanken sind normalerweise separate Anstrengungen erforderlich, um in die nächsten Ebenen der Datennormalisierung zu gelangen. Wir werden jedoch im Folgenden kurz die nächsten Ebenen der Normalisierung in DBMS besprechen.
Boyce-Codd-Normalform (BCNF)
Auch wenn eine Datenbank in 3 istrd Normalform, dennoch würde es zu Anomalien kommen, wenn es mehr als eine hätte Kandidat Schlüssel.
Manchmal wird auch BCNF genannt 3.5 Normalform.
Vierte Normalform (4NF)
Wenn keine Datenbanktabelleninstanz zwei oder mehr unabhängige und mehrwertige Daten enthält, die die relevante Entität beschreiben, dann ist sie in 4th Normalform.
Fünfte Normalform (5NF)
Eine Tabelle finden Sie in 5th Normalform nur, wenn sie in 4NF vorliegt und nicht ohne Datenverlust in eine beliebige Anzahl kleinerer Tabellen zerlegt werden kann.
Sechste Normalform (6NF) vorgeschlagen
6th Die Normalform ist nicht standardisiert, wird jedoch seit einiger Zeit von Datenbankexperten diskutiert. Hoffentlich hätten wir eine klare und standardisierte Definition für 6th Normalform in naher Zukunft…
Was sind die Vorteile der Normalisierung?
- Verbessern Sie die Datenkonsistenz: Durch die Normalisierung wird sichergestellt, dass jedes Datenelement nur an einem Ort gespeichert wird, wodurch die Wahrscheinlichkeit inkonsistenter Daten verringert wird. Wenn Daten aktualisiert werden, müssen sie nur an einer Stelle aktualisiert werden, um die Konsistenz sicherzustellen.
- Datenredundanz reduzieren: Durch die Normalisierung werden doppelte Daten eliminiert, indem sie in mehrere zusammengehörige Tabellen aufgeteilt werden. Dies kann Speicherplatz sparen und die Datenbank effizienter machen.
- Verbessern Sie die Abfrageleistung: Normalisierte Datenbanken sind oft einfacher abzufragen. Da die Daten logisch organisiert sind, können Abfragen so optimiert werden, dass sie schneller ausgeführt werden.
- Machen Sie Daten aussagekräftiger: Normalisierung beinhaltet Gruppenping Daten werden so aufbereitet, dass sie verständlich und intuitiv sind. Dadurch wird die Datenbank leichter verständlich und nutzbar, insbesondere für Personen, die sie nicht entworfen haben.
- Reduzieren Sie die Wahrscheinlichkeit von Anomalien: Anomalien sind Probleme, die beim Hinzufügen, Aktualisieren oder Löschen von Daten auftreten können. Durch Normalisierung kann die Wahrscheinlichkeit dieser Anomalien verringert werden, indem sichergestellt wird, dass die Daten logisch organisiert sind.
Was sind die Nachteile der Normalisierung?
- Erhöhte Komplexität: Normalisierung kann zu komplexen Beziehungen führen. Eine große Anzahl von Tabellen mit Fremdschlüsseln kann schwierig zu verwalten sein und zu Verwirrung führen.
- Reduzierte Flexibilität: Aufgrund der strengen Normalisierungsregeln besteht möglicherweise weniger Flexibilität beim Speichern von Daten, die diese Regeln nicht einhalten.
- Erhöhter Speicherbedarf: Während die Normalisierung die Redundanz verringert, kann es erforderlich sein, mehr Speicherplatz zuzuweisen, um die zusätzlichen Tabellen und Indizes unterzubringen.
- Leistungs-Overhead: Das Zusammenführen mehrerer Tabellen kann im Hinblick auf die Leistung kostspielig sein. Je normalisierter die Daten sind, desto mehr Verknüpfungen sind erforderlich, was die Datenabrufzeiten verlangsamen kann.
- Verlust des Datenkontexts: Durch die Normalisierung werden Daten in separate Tabellen aufgeteilt, was zum Verlust des Geschäftskontexts führen kann. Die Untersuchung verwandter Tabellen ist notwendig, um den Kontext eines Datenelements zu verstehen.
- Bedarf an Expertenwissen: Die Implementierung einer normalisierten Datenbank erfordert ein tiefes Verständnis der Daten, der Beziehungen zwischen Daten und der Normalisierungsregeln. Dies erfordert Expertenwissen und kann zeitaufwändig sein.
Das ist alles zur SQL-Normalisierung!!!
Häufig gestellte Fragen
Zusammenfassung
- Datenbankdesign ist entscheidend für die erfolgreiche Implementierung eines Datenbankverwaltungssystems, das die Datenanforderungen eines Unternehmenssystems erfüllt.
- Die Normalisierung im DBMS ist ein Prozess, der dazu beiträgt, Datenbanksysteme zu erstellen, die kostengünstiger sind und über bessere Sicherheitsmodelle verfügen.
- Funktionale Abhängigkeiten sind ein sehr wichtiger Bestandteil des Normalisierungsprozesses von Daten
- Die meisten Datenbanksysteme sind bis zur dritten Normalform im DBMS normalisierte Datenbanken.
- Ein Primärschlüssel identifiziert den Datensatz in einer Tabelle eindeutig und darf nicht null sein
- Ein Fremdschlüssel hilft beim Verbinden einer Tabelle und verweist auf einen Primärschlüssel