Ordindlejring og Word2Vec med eksempel
⚡ Smart opsummering
Word Embedding og Word2Vec konverterer tekst til tætte numeriske vektorer, så maskinlæringsmodeller genkender ord med lignende betydning. Denne ressource forklarer teknikken, dens CBOW- og Skip-Gram-arkitekturer, aktiveringsfunktioner og en komplet Gensim-implementering til virkelige applikationer.
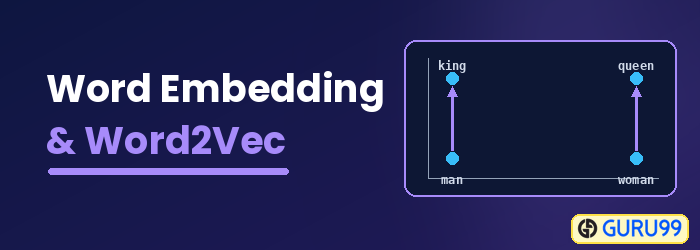
Hvad er Word Embedding?
Indlejring af ord er en ordrepræsentationstype, der gør det muligt for maskinlæringsalgoritmer at forstå ord med lignende betydninger. Det er en sprogmodellerings- og funktionslæringsteknik til at kortlægge ord i vektorer af reelle tal ved hjælp af neurale netværk, probabilistiske modeller eller dimensionsreduktion på ord-samforekomstmatricen. Nogle ordindlejringsmodeller er Word2vec (Google), GloVe (Stanford) og fastText (Facebook).
Ordindlejring kaldes også en distribueret semantisk model, distribueret repræsenteret model, semantisk vektorrum eller vektorrumsmodel. Når du læser disse navne, støder du på ordet semantiske, hvilket betyder at kategorisere lignende ord sammen. For eksempel bør frugter som æble, mango og banan placeres tæt sammen, hvorimod bøger placeres langt væk fra disse ord. I en bredere forstand vil ordindlejring skabe en vektor af frugter, der er placeret langt væk fra vektorrepræsentationen af bøger.
Hvor bruges Word Embedding?
Ordindlejring hjælper med funktionsgenerering, dokumentklyngering, tekstklassificering og opgaver med behandling af naturligt sprog. Lad os liste disse anvendelser og diskutere hver enkelt.
- Beregn lignende ord: Ordindlejring bruges til at foreslå lignende ord som det ord, der er underlagt forudsigelsesmodellen. Derudover foreslås også forskellige ord, såvel som de mest almindelige ord.
- Opret en gruppe af relaterede ord: Det bruges til semantiske grupperping, som grupperer ting med lignende karakteristika sammen og skubber forskellige genstande langt væk.
- Funktion til tekstklassificering: Tekst kortlægges i arrays af vektorer, der føres til modellen til både træning og forudsigelse. Tekstbaserede klassificeringsmodeller kan ikke trænes på strenge, så dette konverterer teksten til en maskintrænbar form. Dens semantisk opbyggende funktioner hjælper yderligere med tekstbaseret klassificering.
- Dokumentklynger: Dette er en anden applikation, hvor Word Embedding og Word2vec er meget udbredt.
- Naturlig sprogbehandling: Der er mange applikationer, hvor ordindlejring er nyttigt og vinder over funktioner som f.eks.tractionsfaser, såsom ordklassetagging, sentimentanalyse og syntaktisk analyse.
Nu hvor du forstår, hvor ordindlejring anvendes, lad os se på den mest populære model, der bruges til at oprette disse indlejringer.
Hvad er Word2vec?
Word2vec er en teknik eller model, der producerer ordindlejringer for bedre ordrepræsentation. Det er en naturlig sprogbehandlingsmetode, der indfanger et stort antal præcise syntaktiske og semantiske ordforhold. Det er et overfladisk tolags neuralt netværk, der kan registrere synonyme ord og foreslå yderligere ord til delvise sætninger, når det er trænet.
Før du går videre, se venligst forskellen mellem et overfladisk og et dybt neuralt netværk, som vist i nedenstående eksempeldiagram for Word-indlejring:
Det overfladiske neurale netværk består kun af ét skjult lag mellem input og output, hvorimod et dybt neuralt netværk indeholder flere skjulte lag mellem input og output. Input er underlagt noder, hvorimod det skjulte lag, såvel som outputlaget, indeholder neuroner.
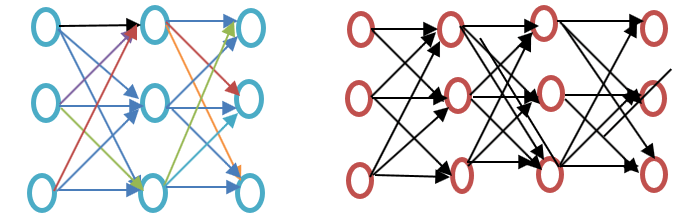
Word2vec er et tolagsnetværk, hvor der er et input, et skjult lag og et output.
Word2vec blev udviklet af en gruppe forskere ledet af Tomas Mikolov hos GoogleWord2vec er bedre og mere effektiv end den latente semantiske analysemodel.
Hvorfor Word2vec?
Word2vec repræsenterer ord i en vektorrumsrepræsentation. Ord repræsenteres i form af vektorer, og placeringen sker på en sådan måde, at ord med lignende betydning vises sammen, og ord med forskellige betydninger er placeret langt væk. Dette kaldes også en semantisk relation. Neurale netværk forstår ikke tekst; i stedet forstår de kun tal. Ordindlejring giver en måde at konvertere tekst til en numerisk vektor.
Word2vec rekonstruerer den sproglige kontekst af ord. Før vi går videre, lad os forstå, hvad sproglig kontekst er. I et generelt scenarie, når vi taler eller skriver for at kommunikere, forsøger andre mennesker at finde ud af sætningens formål. For eksempel: "Hvad er temperaturen i Indien?" Her er konteksten, at brugeren ønsker at kende "temperaturen i Indien". Kort sagt er hovedformålet med en sætning kontekst. Ordene eller sætningerne omkring talt eller skrevet sprog hjælper med at bestemme betydningen af konteksten. Word2vec lærer vektorrepræsentationen af ord gennem disse kontekster.
Hvad gør Word2vec?
Før Word Embedding
Det er vigtigt at vide, hvilken tilgang der blev brugt før ordindlejring, og hvad dens ulemper er, og derefter vil vi se på, hvordan disse ulemper overvindes ved ordindlejring ved hjælp af Word2vec-tilgangen. Til sidst vil vi gå videre til, hvordan Word2vec fungerer, fordi det er vigtigt at forstå, hvordan det fungerer.
Tilgang til latent semantisk analyse
Dette er den fremgangsmåde, der blev brugt før ordindlejringer. Den brugte konceptet med en ordpose, hvor ord repræsenteres i form af kodede vektorer. Det er en sparsom vektorrepræsentation, hvor dimensionen er lig med ordforrådets størrelse. Hvis ordet forekommer i ordbogen, tælles det; ellers tælles det ikke. For at forstå mere, se venligst programmet nedenfor.
Word2vec eksempel

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Output:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Forklaring
- CountVectorizer er modulet, der bruges til at gemme ordforrådet baseret på at tilpasse ordene i det. Dette importeres fra sklearn.
- Lav objektet ved hjælp af klassen CountVectorizer.
- Skriv de data i listen, der skal tilpasses i CountVectorizer.
- Data passer ind i objektet oprettet fra klassen CountVectorizer.
- Anvend en "bag-of-words"-metode til at tælle ord i dataene ved hjælp af ordforrådet. Hvis et ord eller en token ikke er tilgængelig i ordforrådet, sættes en sådan indeksposition til nul.
- Variablen i linje 5, som er x, konverteres til et array (en metode tilgængelig for x). Dette giver antallet af hvert token i sætningen eller listen angivet i linje 3.
- Dette viser de funktioner, der er en del af ordforrådet, når det tilpasses ved hjælp af dataene i linje 4.
I den latente semantiske tilgang repræsenterer rækken unikke ord, mens kolonnen repræsenterer antallet af gange, ordet forekommer i dokumentet. Det er en repræsentation af ord i form af en dokumentmatrix. Term Frequency-Inverse Document Frequency (TF-IDF) bruges til at tælle hyppigheden af ord i dokumentet, hvilket er hyppigheden af termen i dokumentet divideret med hyppigheden af termen i hele korpuset.
Manglende Bag of Words metode
- Den ignorerer ordenes rækkefølge; for eksempel, det her er dårligt = er det her dårligt.
- Den ignorerer ordenes kontekst. Antag, at vi skriver sætningen "Han elskede bøger. Uddannelse findes bedst i bøger." Det ville oprette to vektorer: en for "Han elskede bøger" og en anden for "Uddannelse findes bedst i bøger." Den ville behandle dem begge som ortogonale, hvilket gør dem uafhængige, men i virkeligheden er de relateret til hinanden.
For at overvinde disse begrænsninger blev ordindlejring udviklet, og Word2vec er én tilgang, der bruges til at implementere det.
Hvordan fungerer Word2vec?
Word2vec lærer et ord ved at forudsige dets omgivende kontekst. Lad os for eksempel tage ordet "Han elsker Fodbold."
Vi ønsker at beregne Word2vec for ordet: elsker.
Formode:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Ordet elsker bevæger sig hen over hvert ord i korpuset. Syntaktiske såvel som semantiske forhold mellem ord er kodet. Dette hjælper med at finde lignende og analoge ord.
Alle tilfældige træk ved ordet elsker beregnes. Disse funktioner ændres eller opdateres i forhold til naboord eller kontekstord ved hjælp af en Rygformering fremgangsmåde.
En anden måde at lære på er, at hvis konteksterne af to ord er ens, eller to ord har lignende træk, så er sådanne ord beslægtede.
Word2vec Architecture
Der er to arkitekturer, der bruges af Word2vec:
- Kontinuerlig ordpose (CBOW)
- Skip-gram
Før vi går videre, lad os diskutere, hvorfor disse arkitekturer eller modeller er vigtige fra et ordrepræsentationssynspunkt. Indlæring af ordrepræsentation er i bund og grund uovervåget, men der er behov for mål/etiketter for at træne modellen. Skip-gram og CBOW konverterer den uovervågede repræsentation til en overvåget form til modeltræning.
I CBOW forudsiges det aktuelle ord ved hjælp af vinduet i omgivende kontekstvinduer. For eksempel, hvis wI-1, ogI-2, ogi + 1, ogi + 2 får ord eller kontekst, vil denne model give wi.
Skip-Gram udfører det modsatte af CBOW, hvilket antyder, at den forudsiger den givne sekvens eller kontekst ud fra ordet. Du kan vende eksemplet om for at forstå det. Hvis wi er givet, vil dette forudsige konteksten, eller wI-1, ogI-2, ogi + 1, ogi + 2.
Word2vec giver mulighed for at vælge mellem CBOW (Continuous Bag of Words) og skip-gram. Sådanne parametre leveres under træningen af modellen. Man kan vælge at bruge negativ sampling eller et hierarkisk softmax-lag.
Kontinuerlig pose med ord
Lad os tegne et simpelt Word2vec-eksempeldiagram for at forstå den kontinuerlige "bag-of-words"-arkitektur.

Lad os beregne ligningerne matematisk. Antag, at V er ordforrådets størrelse, og N er størrelsen på det skjulte lag. Input er defineret som { xI-1, xI-2, xi + 1, xi + 2 }. Vi får vægtmatricen ved at gange V * N. En anden matrix fås ved at gange inputvektoren med vægtmatricen. Dette kan også forstås ved hjælp af følgende ligning.
h = xitW
hvor xit og W er henholdsvis inputvektoren og vægtmatricen.
For at beregne overensstemmelsen mellem kontekst og det næste ord, henvises til nedenstående ligning.
u = forudsagt repræsentation * h
hvor den forudsagte repræsentation opnås fra modellen i ovenstående ligning.
Skip-Gram model
Skip-Gram-metoden bruges til at forudsige en sætning givet et inputord. For bedre at forstå det, lad os tegne diagrammet vist i Word2vec-eksemplet nedenfor.

Man kan behandle det som det modsatte af modellen med den kontinuerlige pose af ord, hvor inputtet er ordet, og modellen leverer konteksten eller sekvensen. Vi kan også konkludere, at målet føres til inputtet, og outputlaget replikeres flere gange for at imødekomme det valgte antal kontekstord. Fejlvektoren fra alle outputlag summeres for at justere vægte via en backpropagation-metode.
Hvilken model skal man vælge?
CBOW er flere gange hurtigere end skip-gram og giver en bedre frekvens for hyppige ord, hvorimod skip-gram kræver en lille mængde træningsdata og repræsenterer selv sjældne ord eller sætninger. Tabellen nedenfor sammenligner begge arkitekturer med et hurtigt blik.
| Aspect | CBOW | Skip-Gram |
|---|---|---|
| Forudsigelse | Forudsiger målordet ud fra konteksten | Forudsiger kontekst ud fra målordet |
| Træningshastighed | Hurtigere | Langsommere |
| Hyppige ord | Højere nøjagtighed | Lavere nøjagtighed |
| Sjældne ord | Svagere repræsentation | Stærkere repræsentation |
| Træningsdata | Behøver flere data | Fungerer med mindre data |
Forholdet mellem Word2vec og NLTK
NLTK er det naturlige Language Toolkit. Det bruges til forbehandling af tekst. Man kan udføre forskellige operationer såsom ordklasse-tagging, lemmatisering, stemming, fjernelse af stopord og fjernelse af sjældne eller mindst brugte ord. Det hjælper med at rense teksten samt forberede funktioner fra de effektive ord. På den anden side bruges Word2vec til semantisk (nært beslægtede elementer sammen) og syntaktisk (sekvens) matchning. Ved hjælp af Word2vec kan man finde lignende ord, forskellige ord, dimensionsreduktion og mange andre. En anden vigtig funktion i Word2vec er at konvertere den højere dimensionelle repræsentation af tekst til lavere dimensionelle vektorer.
Hvor skal man bruge NLTK og Word2vec?
Hvis man skal udføre nogle generelle opgaver som nævnt ovenfor, såsom tokenisering, POS-tagging og parsing, skal man bruge NLTK, hvorimod man skal bruge Word2vec til at forudsige ord i henhold til en kontekst, emnemodellering eller dokumentlighed.
Relation mellem NLTK og Word2vec ved hjælp af kode
NLTK og Word2vec kan bruges sammen til at finde lignende ordrepræsentationer eller syntaktisk matchning. NLTK-værktøjssættet kan bruges til at indlæse mange pakker, der følger med NLTK, og en model kan oprettes ved hjælp af Word2vec. Den kan derefter testes på ord i realtid. Lad os se kombinationen af begge i følgende kode. Før du går videre med processen, bedes du se på de korpusa, som NLTK leverer. Du kan downloade det ved hjælp af kommandoen:
nltk(nltk.download('all'))

Se venligst skærmbilledet for koden.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Output:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Forklaring af Code
- Nltk-biblioteket importeres, hvorfra du kan downloade abc-korpuset, som vi vil bruge i næste trin.
- Gensim er importeret. Hvis Gensim Word2vec ikke er installeret, skal du installere det ved hjælp af kommandoen "pip3 install gensim". Se venligst skærmbilledet nedenfor.

- Importer abc-korpuset, som er blevet downloadet ved hjælp af nltk.download('abc').
- Send filerne til Word2vec-modellen, som importeres ved hjælp af Gensim, som sætninger.
- Ordforrådet gemmes i form af en variabel.
- Modellen testes på eksempelordet videnskab, da disse filer er relateret til videnskab.
- Her forudsiges det lignende ord "videnskab" af modellen.
Aktivatorer og Word2Vec
En neurons aktiveringsfunktion definerer neuronens output givet et sæt input. Den er biologisk inspireret af aktivitet i vores hjerner, hvor forskellige neuroner aktiveres ved hjælp af forskellige stimuli. Lad os forstå aktiveringsfunktionen gennem følgende diagram.

Her er x1, x2, … x4 noderne i det neurale netværk.
w1, w2, w3 er vægtene af noderne.
Summen (Σ) af alle vægte og nodeværdier fungerer som aktiveringsfunktionen.
Hvorfor aktiveringsfunktion?
Hvis der ikke anvendes nogen aktiveringsfunktion, ville outputtet være lineært, men funktionaliteten af en lineær funktion er begrænset. For at opnå kompleks funktionalitet såsom objektdetektion, billedklassificering osv.ping tekst ved hjælp af stemme og mange andre ikke-lineære output, er en aktiveringsfunktion nødvendig.
Hvordan aktiveringslaget beregnes i ordet indlejring (Word2vec)
Softmax-laget (normaliseret eksponentiel funktion) er output-lagets funktion, der aktiverer eller udløser hver node. En anden anvendt tilgang er hierarkisk softmax, hvor kompleksiteten beregnes ved O(log2V), hvorimod det i softmax er O(V), hvor V er ordforrådets størrelse. Forskellen mellem disse er reduktionen af kompleksiteten i det hierarkiske softmax-lag. For at forstå dets funktionalitet, se venligst nedenstående eksempel på Word-indlejring:

Antag, at vi vil beregne sandsynligheden for at observere ordet kærlighed givet en bestemt kontekst. Flytningen fra roden til bladnoden vil først bevæge sig til node 2 og derefter til node 5. Så hvis vi har en ordforrådsstørrelse på 8, er der kun behov for tre beregninger. Dette muliggør dekomponering af beregningen af sandsynligheden for ét ord (kærlighed).
Hvilke andre muligheder er tilgængelige end Hierarchical Softmax?
Generelt er de tilgængelige indlejringsmuligheder Differentieret Softmax, CNN-Softmax, vigtighedssampling, adaptiv vigtighedssampling, støjkontrastiv estimering, negativ sampling, selvnormalisering og hyppig normalisering.
Når vi taler specifikt om Word2vec, har vi negativ sampling tilgængelig.
Negativ sampling er en måde at sample træningsdata på. Det minder lidt om stokastisk gradient descent, men med en vis forskel. Negativ sampling søger kun efter negative træningseksempler. Det er baseret på støjkontraststiv estimering og sampler tilfældigt ord, der ikke er i konteksten. Det er en hurtig træningsmetode, der vælger konteksten tilfældigt. Hvis det forudsagte ord vises i den tilfældigt valgte kontekst, er begge vektorer tæt på hinanden.
Hvilken konklusion kan man drage?
Aktivatorer aktiverer neuronerne, ligesom vores neuroner aktiveres af eksterne stimuli. Softmax-laget er en af outputlagsfunktionerne, der aktiverer neuronerne i tilfælde af ordindlejringer. I Word2vec har vi muligheder som hierarkisk softmax og negativ sampling. Ved hjælp af aktivatorer kan man konvertere en lineær funktion til en ikke-lineær funktion, og en kompleks maskinlæringsalgoritme kan implementeres ved hjælp af sådanne funktioner.
Hvad er Gensim?
Gensim er et open source-emnemodellering og naturligt sprogbehandlingsværktøj, der er implementeret i Python og Cython. Gensim-værktøjssættet giver brugerne mulighed for at importere Word2vec til emnemodellering for at opdage skjult struktur i tekstens brødtekst. Gensim tilbyder ikke kun en implementering af Word2vec, men også Doc2vec og FastText.
Dette afsnit fokuserer på Word2vec, så vi holder os til det aktuelle emne.
Sådan implementeres Word2vec ved hjælp af Gensim
Indtil nu har vi diskuteret, hvad Word2vec er, dets forskellige arkitekturer, hvorfor der er et skift fra en ordsæk til Word2vec, forholdet mellem Word2vec og NLTK med livekode, og aktiveringsfunktioner.
Nedenfor er den trinvise metode til at implementere Word2vec ved hjælp af Gensim:
Trin 1) Dataindsamling
Det første skridt til at implementere enhver maskinlæringsmodel eller implementering af naturlig sprogbehandling er dataindsamling.
Bemærk venligst dataene for at bygge en intelligent chatbot som vist i nedenstående Gensim Word2vec-eksempel.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Her er hvad vi forstår ud fra dataene:
- Disse data indeholder tre ting: tag, mønster og svar. Tagget er intentionen (hvad er emnet for diskussionen).
- Dataene er i JSON-format.
- Et mønster er et spørgsmål, som brugerne stiller botten.
- Svar er de svar, som chatbotten giver på det tilsvarende spørgsmål/mønster.
Trin 2) Dataforbehandling
Det er meget vigtigt at behandle rådataene. Hvis rensede data føres til maskinen, vil modellen reagere mere præcist og lære dataene mere effektivt.
Dette trin involverer fjernelse af stopord, stemming, unødvendige ord osv. Før du går videre, er det vigtigt at indlæse data og konvertere dem til en dataframe. Se venligst nedenstående kode for dette.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Forklaring af Code:
- Da dataene er i JSON-format, importeres json.
- Filen gemmes i variablen.
- Filen åbnes og indlæses i datavariablen.
Nu er dataene importeret, og det er tid til at konvertere dataene til en dataframe. Se nedenstående kode for det næste trin.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Forklaring af Code:
1. Data konverteres til en dataramme ved hjælp af pandas, som blev importeret ovenfor.
2. Den konverterer listen i kolonnemønstrene til en streng.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Forklaring:
1. Engelske stopord importeres ved hjælp af stopordmodulet fra nltk-værktøjssættet.
2. Alle ord i teksten konverteres til små bogstaver ved hjælp af en for-betingelse og en lambda-funktion. Lambda funktion er en anonym funktion.
3. Alle tekstrækker i datarammen kontrolleres for strengtegnsætning, og disse filtreres.
4. Tegn som tal eller prikker fjernes ved hjælp af et regulært udtryk.
5. Digits fjernes fra teksten.
6. Stopord fjernes på dette trin.
7. Ord filtreres nu, og forskellige former af det samme ord fjernes ved hjælp af lemmatisering. Med disse har vi afsluttet dataforbehandlingen.
Output:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Trin 3) Opbygning af neuralt netværk ved hjælp af Word2vec
Nu er det tid til at bygge en model ved hjælp af Gensim Word2vec-modulet. Vi skal importere Word2vec fra Gensim. Lad os gøre dette, og så vil vi bygge den, og i den sidste fase vil vi kontrollere modellen på realtidsdata.
from gensim.models import Word2Vec
Nu kan vi bygge modellen ved hjælp af Word2Vec. Se venligst den næste kodelinje for at lære, hvordan du opretter modellen ved hjælp af Word2Vec. Tekst leveres til modellen i form af en liste, så vi konverterer teksten fra datarammen til en liste ved hjælp af nedenstående kode.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Forklaring af Code:
1. Oprettede bigger_list, hvor den indre liste tilføjes. Dette er det format, der føres til modellen Word2Vec.
2. En løkke implementeres, og hver indtastning i mønsterkolonnen i datarammen itereres.
3. Hvert element i kolonnemønstrene opdeles og gemmes i den indre liste li.
4. Den indre liste tilføjes til den ydre liste.
5. Denne liste er angivet for Word2Vec-modellen. Lad os forstå nogle af de parametre, der er angivet her.
Min_antal: Den ignorerer alle ord med en samlet frekvens lavere end dette.
Størrelse: Det fortæller dimensionaliteten af ordet vektorer.
Arbejdere: Dette er trådene til at træne modellen.
Der er også andre muligheder tilgængelige, og nogle vigtige af dem er forklaret nedenfor.
Vindue: Maksimal afstand mellem det aktuelle og det forudsagte ord i en sætning.
Sg: Det er en træningsalgoritme: 1 for skip-gram og 0 for en kontinuerlig ordseddel. Vi har diskuteret disse i detaljer ovenfor.
Hs: Hvis dette er 1, bruger vi hierarkisk softmax til træning, og hvis 0, bruges negativ sampling.
Alpha: Indledende læringshastighed.
Lad os vise den endelige kode nedenfor:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Trin 4) Modelbesparelse
Modellen kan gemmes i form af en bin-fil og en modelfil. Bin er det binære format. Se venligst nedenstående linjer for at gemme modellen.
model.save("word2vec.model") model.save("model.bin")
Forklaring af ovenstående kode
1. Modellen gemmes i form af en .model-fil.
2. Modellen gemmes i form af en .bin-fil.
Vi vil bruge denne model til at udføre test i realtid, såsom lignende ord, forskellige ord og mest almindelige ord.
Trin 5) Indlæsning af model og udførelse af test i realtid
Modellen indlæses ved hjælp af nedenstående kode:
model = Word2Vec.load('model.bin')
Hvis du vil udskrive ordforrådet fra det, gøres det ved hjælp af kommandoen nedenfor:
vocab = list(model.wv.vocab)
Se venligst resultatet:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Trin 6) De fleste lignende ord kontrol
Lad os implementere tingene praktisk:
similar_words = model.most_similar('thanks') print(similar_words)
Se venligst resultatet:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Trin 7) Matcher ikke ord fra de leverede ord
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Vi har leveret ordene 'Vi ses senere, tak for besøget'Dette udskriver det mest forskellige ord fra disse ord. Lad os køre denne kode og finde resultatet.
Resultatet efter udførelse af ovenstående kode:
Thanks
Trin 8) Find ligheden mellem to ord
Dette fortæller resultatet i form af sandsynligheden for lighed mellem to ord. Se venligst nedenstående kode for, hvordan du udfører dette afsnit.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Resultatet af ovenstående kode er som følger:
0.13706
Du kan finde lignende ord ved at udføre nedenstående kode:
similar = model.similar_by_word('kind') print(similar)
Output af ovenstående kode:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]