Scikit-Learn Tutorial: Sådan installeres & Scikit-Learn eksempler
⚡ Smart opsummering
Scikit-learn er open source Python Et bibliotek, der dækker forbehandling, klassificering, regression, klyngedannelse og modelvalg bag en enkelt konsistent estimatorgrænseflade, som holder en komplet maskinlæringsworkflow kort, læsbar og reproducerbar fra rådata til scorede forudsigelser.

Hvad er Scikit-learn?
Scikit-lære er en open source Python bibliotek for machine learningDen understøtter veletablerede algoritmer som KNN, gradient boosting, random forest og SVM, og den er bygget oven på nusset og SciPy. Scikit-learn bruges i vid udstrækning i Kaggle-konkurrencer såvel som i fremtrædende teknologivirksomheder. Det dækker forbehandling, dimensionalitetsreduktion, klassificering, regression, klyngedannelse og modelvalg.
Scikit-learn har noget af den bedste dokumentation af alle open source-biblioteker. Det tilbyder endda et interaktivt estimatordiagram, Valg af den rigtige estimator, der guider dig fra størrelsen af dit datasæt til en kort liste over algoritmer, der er værd at prøve.
Figuren nedenfor illustrerer, hvordan Scikit-learn fungerer.
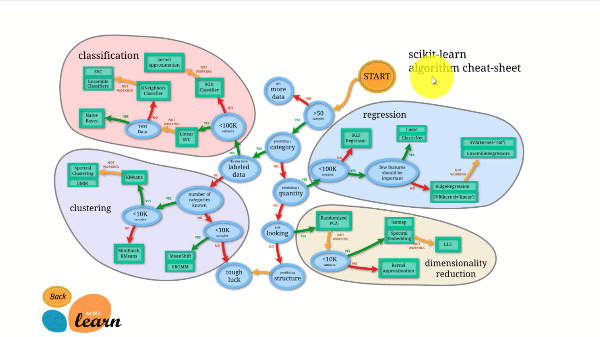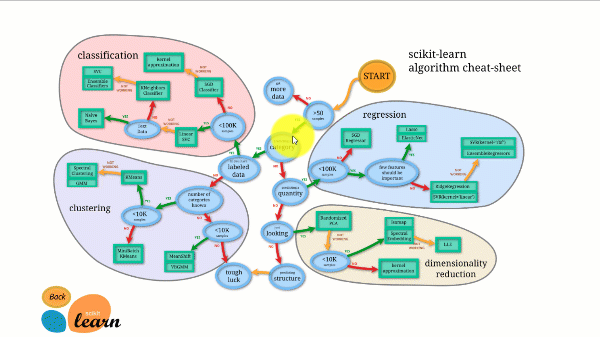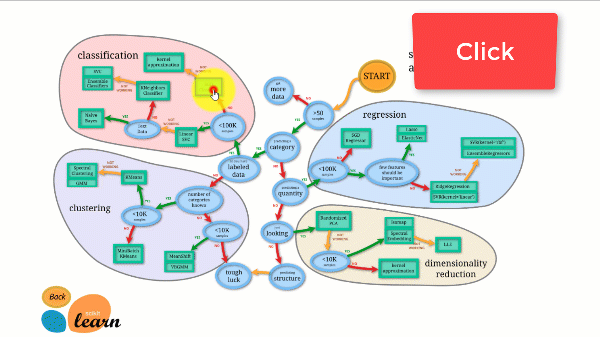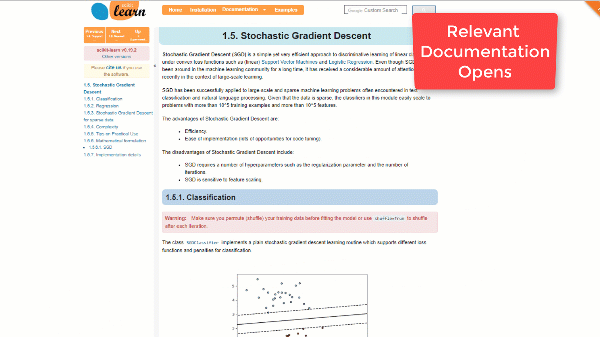
Scikit-learn er ikke svært at bruge og giver fremragende resultater. Det træner dog på CPU'en: arbejdet paralleliseres på tværs af kerner med argumentet n_jobs i stedet for på en GPU. Det er muligt, men sjældent optimalt, især hvis du allerede ved, hvordan man bruger det. TensorFlow.
Sådan downloades og installeres Scikit-learn
Nu i dette Python Scikit-learn-vejledning, du lærer hvordan du downloader og installerer Scikit-learn:
Mulighed 1: AWS
Scikit-learn kan bruges over AWS. Et Docker-billede med scikit-learn forudinstalleret sparer alt opsætningsarbejdet.
For at installere udviklerversionen skal du køre kommandoen nedenfor Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Mulighed 2: Mac eller Windows ved hjælp af Anaconda
For at lære om installation af Anaconda, se Sådan downloader og installerer du TensorFlow.
Da denne gennemgang blev skrevet, havde udviklerne af scikit udgivet en udviklingsversion, der løste problemer i den daværende udgivelse, så nedenstående trin bruger den udviklerversion. På en frisk maskine i dag indeholder den nuværende stabile udgivelse allerede alle de transformere, der bruges her, og pip install -U scikit-learn er nok.
Sådan installeres scikit-learn med Conda Environment
Hvis du installerede scikit-learn med conda-miljøet, skal du følge nedenstående trin for at opdatere til version 0.20.
Trin 1) Aktivér tensorflow-miljøet
source activate hello-tf
Trin 2) Fjern scikit-learn ved hjælp af conda-kommandoen
conda remove scikit-learn
Trin 3) Installer udviklerversionen
Installer scikit-learn-udviklerversionen sammen med de nødvendige biblioteker.
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
BEMÆRK VENLIGST: Windows brugernes behov Microsoft Visuel C++ 14. Du kan få det link..
Scikit-Learn Eksempel med Machine Learning
Denne Scikit-tutorial er opdelt i to dele:
- Maskinlæring med scikit-learn
- Sådan stoler du på din model med LIME
Den første del beskriver, hvordan man opbygger en pipeline, opretter en model og finjusterer hyperparametrene, mens den anden del dækker modelfortolkning.
Trin 1) Importer dataene
I denne Scikit Learn-vejledning vil du bruge datasættet for voksne.
Filen læses direkte fra UCI Machine Learning Repository i koden nedenfor, så manuel download er ikke nødvendig. Hvis du er interesseret i beskrivende statistik, er Dive- og Overview-værktøjerne et kig værd. Se denne tutorial for at lære mere om Dyk og Oversigt.
Du importerer datasættet med pandas. Bemærk, at du skal konvertere de kontinuerlige variabler til flydende format.
Dette datasæt indeholder otte kategoriske variabler, der er anført i CATE_FEATURES:
- arbejdsklasse
- uddannelse
- ægteskabelig
- besættelse
- forhold
- løb
- køn
- oprindelses land
Den indeholder også seks kontinuerlige variabler, som er angivet i CONTI_FEATURES:
- alder
- fnlwgt
- uddannelsesnummer
- kapitalgevinst
- kapitaltab
- timer_uge
Listerne er udfyldt manuelt her, så du har en klarere idé om, hvilke kolonner der er i spil. En hurtigere måde at opbygge en liste over kategoriske eller kontinuerlige kolonner på er:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
Her er koden til at importere dataene:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
Kald af describe() på framen returnerer den overordnede statistik for de seks kontinuerlige kolonner:
| alder | fnlwgt | uddannelsesnummer | kapitalgevinst | kapitaltab | timer_uge | |
|---|---|---|---|---|---|---|
| tælle | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| betyde | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| minut | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Du kan kontrollere antallet af unikke værdier for funktionen native_country. Kun én husstand kommer fra Holland. Den husstand giver ingen information og vil give en fejl under træningen.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Du kan udelade denne uinformative række fra datasættet:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Dernæst gemmer du placeringen af de kontinuerlige funktioner i en liste. Du skal bruge det i næste trin for at bygge rørledningen.
Koden nedenfor kører over alle kolonnenavne i CONTI_FEATURES, læser hver placering (dvs. dens kolonnenummer) og tilføjer den til en liste kaldet conti_features.
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
Den næste blok gør det samme for de kategoriske variabler.
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Se nu på selve datasættet. Hvert kategorisk element er en streng, og en model kan ikke tilføres en strengværdi, så datasættet skal transformeres med dummy-variabler.
df_train.head(5)
Faktisk skal du bruge én kolonne for hver gruppe i hver funktion. Kør først koden nedenfor for at beregne det samlede antal nødvendige kolonner.
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
Hele datasættet indeholder 101 grupper, som vist ovenfor. Alene arbejdsklassefunktionen har ni grupper. Du kan angive navnene på grupperne med koden nedenfor; unique() returnerer de forskellige værdier for hver kategorisk funktion.
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Træningsdatasættet vil derfor indeholde 101 + 6 kolonner: de en-hot-grupper plus de seks kontinuerlige funktioner.
Scikit-learn kan håndtere konverteringen i to trin:
- Konverter strengen til et ID. State-gov bliver ID 1, Self-emp-not-inc bliver ID 2 osv. LabelEncoder gør dette for dig.
- Transponér hvert ID til en ny kolonne. Datasættet har 101 gruppe-ID'er, så der vil være 101 kolonner, der registrerer alle kategoriske funktionsgrupper. Scikit-learn stiller OneHotEncoder til rådighed til denne operation.
Trin 2) Opret tog-/testsættet
Nu hvor datasættet er klar, skal det opdeles 80/20: 80 procent for træningssættet og 20 procent for testsættet.
Du kan bruge train_test_split. Det første argument er dataframen for funktionerne, og det andet er label'en. Du angiver størrelsen på testsættet med test_size.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Trin 3) Byg rørledningen
Pipelinen gør det nemmere at forsyne modellen med konsistente data. Ideen er at sende de rå data gennem ét objekt, der udfører alle operationer i rækkefølge.
Med dette datasæt skal du standardisere de kontinuerlige variabler og konvertere de kategoriske. Enhver operation kan ligge i en pipeline: manglende værdier kan erstattes med middelværdien eller medianen, og nye variabler kan oprettes.
Du har et valg: hardcode de to processer, eller opbyg en pipeline. Hardcodering kan lække testdata ind i den tilpassede statistik og skabe uoverensstemmelser over tid, så pipelinen er den bedre løsning.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Pipelinen udfører to operationer, før den føder den logistiske klassifikator:
- Standardiser variablen: StandardScaler()
- Konverter de kategoriske funktioner: OneHotEncoder(sparse=False)
Du udfører begge trin med make_column_transformer. Da denne gennemgang blev skrevet, var funktionen ikke i den udgivne version af scikit-learn (0.19), hvilket er grunden til, at udviklerversionen blev brugt; den er blevet leveret i alle stabile udgivelser siden 0.20.
make_column_transformer er ligetil: du deklarerer hvilke kolonner der skal transformeres, og hvilken transformation der skal anvendes. For at standardisere de kontinuerlige funktioner, overfører du:
- conti_features, StandardScaler() inde i make_column_transformer
- conti_features: listen over kontinuerlige kolonner
- StandardScaler: standardiserer disse kolonner
OneHotEncoder-objektet i make_column_transformer koder etiketterne automatisk.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Versionsnotat: to argumenter i blokken ovenfor er gået videre. Nuværende versioner forventer transformeren først og kolonnerne derefter, og sparsomme blev omdøbt sparse_output i scikit-learn 1.2 og fjernet i 1.4, så nyere kode læses OneHotEncoder(sparse_output=False).
Du kan teste om pipelinen fungerer med fit_transform. Outputtet skal have formen 26048, 107.
preprocess.fit_transform(X_train).shape
(26048, 107)
Datatransformeren er klar. Du opretter pipelinen med make_pipeline, og når dataene er transformeret, bruger du den logistiske regression.
model = make_pipeline(
preprocess,
LogisticRegression())
Det er så trivielt at træne en model med scikit-learn: kald fit på pipelinen. Du kan udskrive nøjagtigheden med score-metoden.
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Endelig kan du forudsige klasserne med predict_proba, som returnerer sandsynligheden for hver klasse. Bemærk, at de to sandsynligheder summerer til én.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Trin 4) Brug af vores pipeline i en gittersøgning
Det kan være kedeligt og udmattende at justere hyperparametrene, de værdier der fastlægger modellens struktur.
En måde at evaluere modellen på ville være at ændre størrelsen på træningssættet og måle præstationen, hvorved øvelsen gentages ti gange for at se spredningen af scoren. Det er en masse manuelt arbejde.
I stedet tilbyder scikit-learn funktioner, der udfører parameterjustering og krydsvalidering for dig.
Krydsvalidering
Krydsvalidering betyder, at træningssættet under træning opdeles n gange i folder, og modellen evalueres n gange. Hvis cv sættes til 10, trænes og evalueres modellen ti gange. I hver runde træner klassifikatoren på ni tilfældigt valgte folder, og den tiende fold beholdes til evaluering.
Netsøgning
Hver klassifikator har hyperparametre, der skal justeres. Du kan prøve værdier én ad gangen eller indstille et parametergitter. Scikit-learn-dokumentationen viser alle de parametre, som den logistiske klassifikator accepterer. For at holde træningen hurtig justerer dette eksempel kun C-parameteren, som styrer regularisering. Den skal være positiv, og en lille værdi giver mere vægt til regularisatoren.
Du bruger GridSearchCV-objektet, som tager en ordbog over de hyperparametre, der skal finjusteres. Angiv hver hyperparameter efterfulgt af de værdier, du vil prøve. For at finjustere C skriver du:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — parameternavnet efterfølges af klassifikatorens navn med små bogstaver og to understregninger.
Modellen vil afprøve fire forskellige værdier: 0.001, 0.01, 0.1 og 1. Den er trænet med 10 foldninger, det vil sige cv=10.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
Du kan nu træne modellen ved hjælp af GridSearchCV med parameterne grid og cv.
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
Output:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
Versionsnotat: og iid Argumentet, der er synligt i dette output, blev udfaset i scikit-learn 0.22 og fjernet i 0.24, så det bør blot fjernes fra GridSearchCV-kaldet i aktuelle udgivelser.
For at få adgang til de bedste parametre bruger du best_params_.
grid_clf.best_params_
Output:
{'logisticregression__C': 1.0}
Efter at have trænet modellen med fire forskellige regulariseringsværdier, giver den optimale parameter:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
bedste logistiske regression fra gittersøgning: 0.850891
Sådan får du adgang til de forudsagte sandsynligheder:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
XGBoost-model med scikit-learn
Prøv nu en af de stærkeste klassifikatorer på markedet. XGBoost er en gradientforstærkende forbedring af den tilfældige skov. Dens teoretiske baggrund er uden for dette projekts omfang. Python Scikit-vejledning, men husk at XGBoost har vundet mange Kaggle-konkurrencer. På et datasæt af gennemsnitlig størrelse kan den fungere lige så godt som en deep learning-algoritme, eller bedre.
Klassifikatoren er udfordrende at træne, fordi den eksponerer et stort antal parametre. Du kan selvfølgelig bruge GridSearchCV til at vælge dem for dig.
En bedre mulighed her er RandomizedSearchCV. GridSearchCV bliver langsom, når gitteret er stort, fordi søgeområdet vokser med hver parameter, der tilføjes. RandomizedSearchCV sampler i stedet værdierne for hver hyperparameter tilfældigt ved hver iteration, så 1,000 iterationer evaluerer 1,000 kombinationer. Det fungerer ellers meget ligesom GridSearchCV.
Du skal importere xgboost. Hvis biblioteket ikke er installeret, så kør pip3 install xgboost, eller installer det indefra en [server/server/etc.]. Jupyter notesbog med:
use import sys
!{sys.executable} -m pip install xgboost
Importer derefter klassifikatoren og de to søgehjælpeprogrammer:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Det næste trin i denne Scikit Python Tutorialen går ud på at specificere de parametre, der skal finjusteres. Den officielle XGBoost-dokumentation viser dem alle. Af hensyn til dette Python I Sklearn-tutorialen vælger du kun to hyperparametre med to værdier hver, fordi XGBoost tager lang tid at træne, og hvert ekstra gitterpunkt øger ventetiden.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Derefter konstruerer du en ny pipeline med XGBoost-klassifikatoren og 600 estimatorer. n_estimators er i sig selv justerbar, og en høj værdi kan føre til overfitting. Du kan prøve andre værdier, men vær opmærksom på, at det kan tage timer. Alle andre parametre beholder deres standardværdi.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Du kan forbedre krydsvalideringen med Stratified K-Folds krydsvalidatoren. Kun tre foldninger bruges her for at fremskynde beregningen, hvilket går ud over kvaliteten; øg dette til 5 eller 10 på din egen maskine for bedre resultater. Modellen trænes over fire iterationer.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Den randomiserede søgning er klar, så du kan træne modellen.
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Som du kan se, scorer XGBoost bedre end den tidligere logistiske regression.
print("Bedste parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Bedste parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Opret DNN med MLPClassifier i scikit-learn
Endelig kan du træne et neuralt netværk med scikit-learn. Metoden er den samme som for enhver anden klassifikator, og estimatoren er MLPClassifier.
from sklearn.neural_network import MLPClassifier
Netværket nedenfor er defineret med:
- Adam løser
- ReLU aktiveringsfunktion
- Alfa = 0.0001
- Batchstørrelse på 150
- To skjulte lag med henholdsvis 200 og 100 neuroner
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Du kan ændre antallet af lag for at forbedre modellen.
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN-regressionsscore: 0.821253
LIME: Stol på din model
Nu hvor du har en god model, har du brug for en måde at stole på den. Maskinlæringsalgoritmer, især tilfældige skove og neurale netværk, er kendt som black-box-modeller: de virker, men ingen kan se hvorfor.
Tre forskere har bygget et værktøj, der viser, hvordan computeren når frem til en forudsigelse. Deres artikel er "Hvorfor skulle jeg stole på dig?", og den algoritme, de publicerede, kaldes Local Interpretable Model-Agnostic Explanations (LIME).
Tag et eksempel. Nogle gange ved man ikke, om en maskinlæringsforudsigelse kan stoles på. En læge kan ikke acceptere en diagnose blot fordi en computer har produceret den, og man er nødt til at vide, om en model er pålidelig, før man sætter den i produktion.
Forestil dig at kunne se, hvorfor en klassifikator lavede en forudsigelse, selv for modeller så komplicerede som neurale netværk, tilfældige skove eller SVM'er med en vilkårlig kerne. Det bliver langt lettere at stole på en forudsigelse, når årsagerne bag den er synlige, og lige så lettere at afgøre, hvornår en model ikke skal stoles på. LIME fortæller dig, hvilke funktioner der lå til grund for klassifikatorens beslutning.
Dataforberedelse
Der er et par ting, du skal ændre for at køre LIME med PythonFørst skal du installere lime i terminalen med pip install lime.
Lime bruger et LimeTabularExplainer-objekt til at approksimere modellen lokalt. Dette objekt kræver:
- et datasæt i nusset format
- Navnet på funktionerne: feature_names
- Navnet på klasserne: klassenavne
- Indekset for kolonnen af kategoriske funktioner: categorical_features
- Navnet på gruppen for hver kategorisk funktion: kategoriske_navne
Opret NumPy-togsættet
Du kan meget nemt kopiere og konvertere df_train fra pandas til NumPy.
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
Få klassens navn
Etiketten er tilgængelig via unique(). Du bør se:
- '<=50K'
- '>50K'
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
Indeksér de kategoriske funktionskolonner
Brug den metode, du lærte tidligere, til at finde navnet på hver gruppe. Du koder etiketten med LabelEncoder og gentager operationen på hvert kategorisk element.
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Nu hvor datasættet er klar, kan du bygge de forskellige datasæt, der er vist i Scikit-læringseksemplerne nedenfor. Dataene transformeres uden for pipelinen her for at undgå fejl med LIME: træningssættet, der sendes til LimeTabularExplainer, skal være et NumPy-array uden strenge, og metoden ovenfor har allerede produceret et.
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
Du kan lave pipelinen med de optimale parametre, som XGBoost har fundet.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
Du får en advarsel. Den forklarer, at du ikke behøver at oprette en label-encoder før pipelinen. Hvis du ikke bruger LIME, er metoden fra den første del af denne Machine Learning med Scikit-learn-tutorial fin. Ellers skal du beholde denne fremgangsmåde: opret først et kodet datasæt, og anvend derefter one-hot-encoderen inde i pipelinen.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Før du bruger LIME, skal du oprette et NumPy-array, der indeholder funktionerne i de forkert klassificerede rækker. Du kan bruge listen senere til at få en idé om, hvad der vildledte klassifikatoren.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
Derefter opretter du en lambda-funktion, der henter forudsigelsen fra modellen for nye data. Du skal snart bruge den.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Du konverterer pandas-dataframen til et NumPy-array.
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
Vælg nu en tilfældig husstand fra testsættet, og se både forudsigelsen, og hvordan computeren er nået frem til den.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Du kan bruge explaineren sammen med explain_instance til at undersøge ræsonnementet bag modellen. Diagrammet, som den gengiver, er vist nedenfor.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klassifikatoren forudsagde denne husstand korrekt: indkomsten er faktisk over 50 kr.
Det første, man skal bemærke, er, at klassifikatoren ikke er særlig sikker på sig selv. Den forudsiger en indkomst over 50 med en sandsynlighed på 64 %, og at 64 % er drevet af kapitalgevinst og civilstand. Den blå farve bidrager negativt til den positive klasse, og den orange linje positivt.
Klassifikatoren er tøvende, fordi denne husstands kapitalgevinst er nul, mens kapitalgevinst normalt er en god indikator for formue. Husstanden arbejder også færre end 40 timer om ugen. Alder, erhverv og køn bidrager alle positivt.
Hvis den civilstand var single, ville klassifikatoren have forudsagt en indkomst under 50 kr. (0.64 – 0.18 = 0.46).
Prøv nu en anden husstand, en der blev klassificeret forkert. Forklaringsskemaet for den følger koden.
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klassifikatoren forudsagde en indkomst under 50, hvilket er forkert. Denne husstand er usædvanlig: den har hverken en kapitalgevinst eller et kapitaltab, personen er skilt, tæt på 60 år gammel og uddannet, dvs. uddannelsesnummer > 12. Klassifikatoren fulgte det overordnede mønster og placerede husstanden under 50.
Leg med LIME selv, og du vil bemærke masser af upræcise fejl fra klassificeringsværktøjet. GitHub-arkivet, som tilhører bibliotekets forfatter, indeholder ekstra dokumentation til billed- og tekstklassificering.
Scikit-learn-kommandoreference
Nedenfor er en liste over nyttige kommandoer, der gælder for scikit-learn version 0.20 og nyere.
| Opgaver | Funktion eller klasse |
|---|---|
| Opret tog-/testdatasættet | train_test_split |
| Byg en pipeline | |
| Markér kolonnerne, og anvend transformationen | make_column_transformer |
| Type af transformation | |
| Standardisere | StandardScaler |
| Min-maks skalering | MinMaxScaler |
| Normaliser | Normalisator |
| Imputer manglende værdier | SimpleImputer |
| Konverter kategorisk | OneHotEncoder |
| Tilpas og transformer dataene | fit_transform |
| Lav rørledningen | make_pipeline |
| Grundlæggende model | |
| Logistisk regression | Logistisk regression |
| XGBoost | XGBClassifier |
| Neuralt net | MLPClassifier |
| Netsøgning | GridSearchCV |
| Randomiseret søgning | RandomizedSearchCV |