MongoDB Regulært udtryk ($regex) med eksempler
⚡ Smart opsummering
MongoDB Regulære udtryk udfører mønstermatchning for at finde strenge i dokumenter ved hjælp af $regex-operatoren, $options-flaget for ufølsomhed over for store og små bogstaver, ankre for nøjagtige matches og skråstreg-afgrænsere, når den nøjagtige feltværdi er ukendt.

Regulære udtryk bruges til mønstermatchning, hvilket grundlæggende er til at finde strenge i dokumenter.
Nogle gange, når du henter dokumenter i en samling, ved du måske ikke præcis, hvad den nøjagtige feltværdi du skal søge efter. Derfor kan man bruge regulære udtryk til at hjælpe med at hente data baseret på mønstermatchende søgeværdier.
Brug af $regex-operator til mønstermatchning
$regex-operatoren i MongoDB bruges til at søge efter specifikke strenge i samlingen. Følgende eksempel viser, hvordan dette kan gøres.
Lad os antage, at vi har den samme medarbejdersamling, som har feltnavnene "Medarbejdereid" og "Medarbejdernavn". Lad os også antage, at vi har følgende dokumenter i vores samling.
| Medarbejder-ID | Ansattes navn |
|---|---|
| 22 | NewMartin |
| 2 | Mohan |
| 3 | Joe |
| 4 | MohanR |
| 100 | Guru99 |
| 6 | Gurang |
I nedenstående kode har vi brugt $regex-operatoren til at angive søgekriterierne.

db.Employee.find({EmployeeName : {$regex: "Gu" }}).forEach(printjson)
Code Forklaring:
- Her ønsker vi at finde alle medarbejdernavne, der indeholder tegnene 'Gu'. Derfor angiver vi $regex-operatoren for at definere søgekriterierne 'Gu'.
- Printjson'en bliver brugt til at udskrive hvert dokument, som returneres af forespørgslen på en bedre måde.
Hvis kommandoen udføres med succes, vil følgende output blive vist:
Output:

Outputtet viser tydeligt, at de dokumenter, hvori medarbejdernavnet indeholder 'Gu'-tegnene, returneres.
Hvis du antager, at din samling har følgende dokumenter med et yderligere dokument, der indeholder medarbejdernavnet som "Guru999”. Hvis du indtastede søgekriterierne som “Guru99”, ville den også returnere dokumentet, der havde “Guru999". Men lad os sige, at vi ikke ønskede dette, men kun ønskede at returnere dokumentet med "Guru99". Så kan vi gøre dette med præcis mønstermatchning. For at lave en præcis mønstermatchning bruger vi tegnene ^ og $. Vi tilføjer tegnet ^ i begyndelsen af strengen og $ i slutningen af strengen.
| Medarbejder-ID | Ansattes navn |
|---|---|
| 22 | NewMartin |
| 2 | Mohan |
| 3 | Joe |
| 4 | MohanR |
| 100 | Guru99 |
| 6 | Gurang |
| 8 | Guru999 |
Følgende eksempel viser, hvordan dette kan gøres.

db.Employee.find({EmployeeName : {$regex: "^Guru99$"}}).forEach(printjson)
Code Forklaring:
- Her i søgekriterierne bruger vi tegnene ^ og $. ^ bruges til at sikre, at strengen starter med et bestemt tegn, og $ bruges til at sikre, at strengen slutter med et bestemt tegn. Så når koden udføres, henter den kun strengen med navnet “Guru99. "
- Printjson'en bliver brugt til at udskrive hvert dokument, som returneres af forespørgslen på en bedre måde.
Hvis kommandoen udføres med succes, vil følgende output blive vist:
Output:
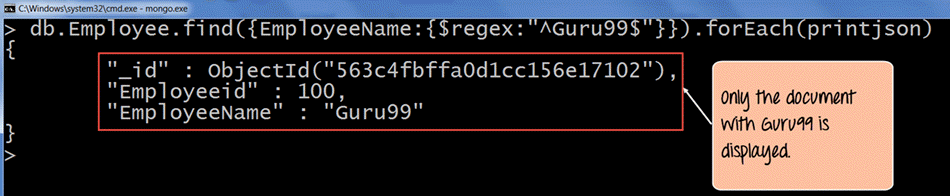
I outputtet er det tydeligt at se strengen "Guru99” er hentet.
Mønstermatching med $optioner
Når man bruger $regex-operatoren, kan man også give yderligere muligheder ved at bruge $optioner søgeord. Antag for eksempel, at du ønskede at finde alle de dokumenter, der havde 'Gu' i deres medarbejdernavn, uanset om det var store og små bogstaver eller ufølsomt. Hvis et sådant resultat ønskes, skal vi bruge $optioner med parameteren for ufølsomhed over for store og små bogstaver.
Følgende eksempel viser, hvordan dette kan gøres.
Lad os antage, at vi har vores samme medarbejdersamling, som har feltnavnene "Employeeid" og "EmployeeName".
Lad os også antage, at vi har følgende dokumenter i vores samling.
| Medarbejder-ID | Ansattes navn |
|---|---|
| 22 | NewMartin |
| 2 | Mohan |
| 3 | Joe |
| 4 | MohanR |
| 100 | Guru99 |
| 6 | Gurang |
| 7 | GURU99 |
Hvis vi kører den samme forespørgsel som i det sidste emne, vil vi aldrig se dokumentet med "GURU99" i resultatet. For at sikre, at dette kommer med i resultatsættet, skal vi tilføje parameteren $options "i".

db.Employee.find({EmployeeName:{$regex: "Gu",$options:'i'}}).forEach(printjson)
Code Forklaring:
- $options med parameteren 'i' (som betyder ufølsomhed over for store og små bogstaver) angiver, at vi ønsker at udføre søgningen uanset om vi finder bogstaverne 'Gu' med små eller store bogstaver.
Hvis kommandoen udføres med succes, vil følgende output blive vist:
Output:
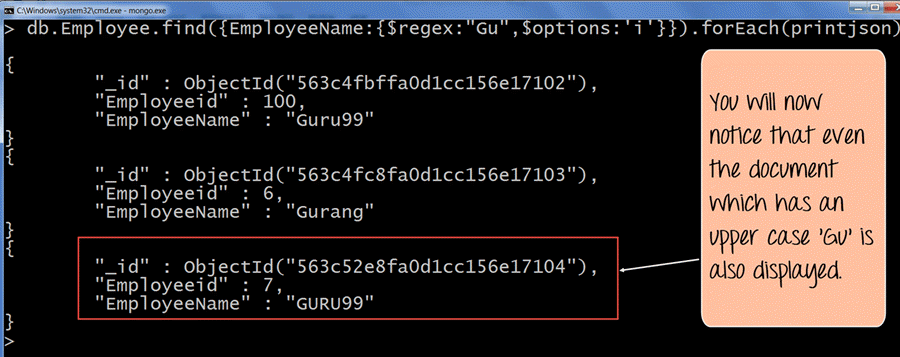
- Outputtet viser tydeligt, at selvom ét dokument har 'Gu' som stort bogstav, vises dokumentet stadig i resultatsættet.
Mønstermatching uden regex-operatoren
Man kan også lave mønstermatchning uden $regex-operatoren. Følgende eksempel viser, hvordan dette kan gøres.

db.Employee.find({EmployeeName: /Gu/}).forEach(printjson)
Code Forklaring:
- "//"-afgrænserne betyder grundlæggende at angive dine søgekriterier inden for disse afgrænsere. Derfor angiver vi /Gu/ for igen at finde de dokumenter, der har 'Gu' i deres medarbejdernavn.
Hvis kommandoen udføres med succes, vil følgende output blive vist:
Output:
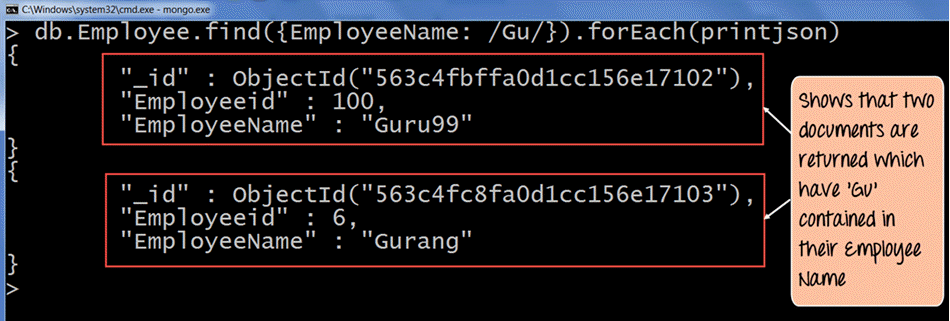
Outputtet viser tydeligt, at de dokumenter, hvori medarbejdernavnet indeholder 'Gu'-tegnene, returneres.
Henter sidste 'n' dokumenter fra en samling
Der er forskellige måder at få de sidste n dokumenter i en samling.
Lad os se på en af måderne via de følgende trin.
Følgende eksempel viser, hvordan dette kan gøres.
Lad os antage, at vi har vores samme medarbejdersamling, som har feltnavnene "Employeeid" og "EmployeeName".
Lad os også antage, at vi har følgende dokumenter i vores samling:
| Medarbejder-ID | Ansattes navn |
|---|---|
| 22 | NewMartin |
| 2 | Mohan |
| 3 | Joe |
| 4 | MohanR |
| 100 | Guru99 |
| 6 | Gurang |
| 7 | GURU99 |
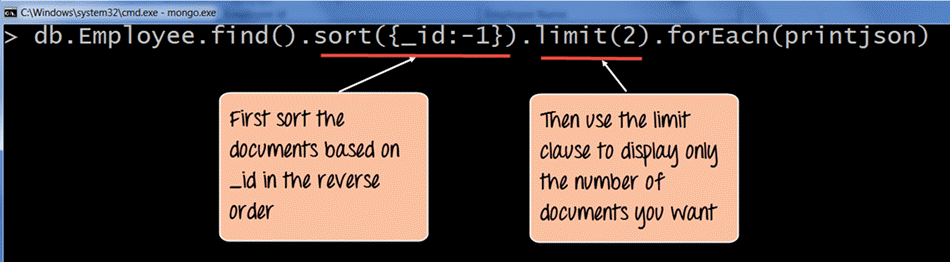
db.Employee.find().sort({_id:-1}).limit(2).forEach(printjson)
Code Forklaring:
- Når du forespørger om dokumenter, skal du bruge sorteringsfunktionen til at sortere posterne i omvendt rækkefølge baseret på _id-feltets værdi i samlingen. -1 angiver grundlæggende, at dokumenterne skal sorteres i omvendt rækkefølge eller faldende rækkefølge, så det sidste dokument bliver det første dokument, der vises.
- Brug derefter limit-klausulen til kun at vise det ønskede antal poster. Her har vi sat limit-klausulen (2), så den henter de sidste to dokumenter.
Hvis kommandoen udføres med succes, vil følgende output blive vist:
Output:
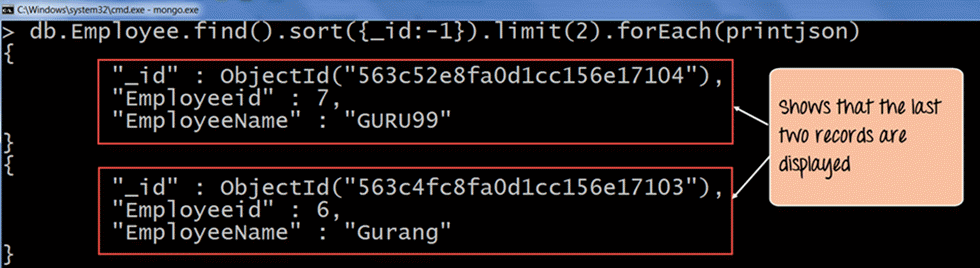
Outputtet viser tydeligt, at de to sidste dokumenter i samlingen vises. Derfor har vi tydeligt vist, at for at hente de sidste 'n'-dokumenter i samlingen, kan vi først sortere dokumenterne i faldende rækkefølge og derefter bruge grænseklausulen til at returnere 'n'-antallet af dokumenter, som er påkrævet.
Bemærk: Hvis søgningen udføres på en streng, der er større end f.eks. 38,000 tegn, vil den ikke vise de rigtige resultater.