Sådan downloader og installerer du NLTK
⚡ Smart opsummering
Download og installer NLTK på Windows, Mac eller Linux ved at installere Python først, derefter tilsættes det naturlige Language Toolkit via pip eller Anaconda og download af corpus-datasættene.

Installerer NLTK i Windows
Lær hvordan du konfigurerer NLTK Windows fra kommandoprompten. Instruktionerne nedenfor forudsætter Python er ikke installeret endnu, så det første trin er at installere Python.
Installation Python in Windows
Trin 1) Åbn linket https://www.python.org/downloads/, og vælg den nyeste Windows frigive.
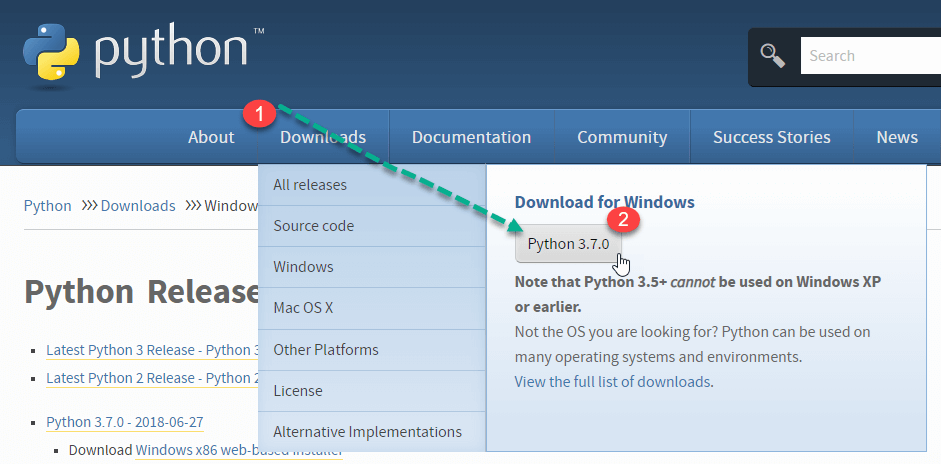
BemærkFor en ældre version, besøg fanen Downloads for at se alle udgivelser.

Trin 2) Klik på den downloadede installationsfil.

Trin 3) Vælg Tilpas installation.
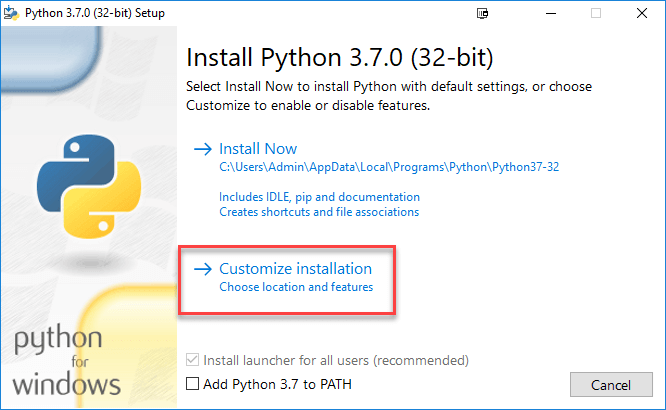
Trin 4) Klik på NÆSTE.

Trin 5) På det næste skærmbillede:
- Vælg de avancerede indstillinger.
- Angiv en brugerdefineret installationsplacering. I dette eksempel er en mappe på C-drevet valgt for at give nemmere adgang.
- Klik på Installer.

Trin 6) Klik på knappen Luk, når installationen er færdig.

Trin 7) Kopier stien til din Scripts-mappe.

Trin 8) I Windows kommandoprompt:
- Naviger til placeringen af pip-mappen.
- Indtast kommandoen for at installere NLTK:
pip3 install nltk
- Installationen skulle gerne være fuldført.

BEMÆRK: Til Python 2, brug kommandoen pip2 install nltk.
Trin 9) På hjemmesiden for oprettelse af en konto skal du indtaste postnummeret for dit service-eller faktureringsområde i feltet, der er markeret (A) på billedet ovenfor. Windows Startmenuen, søg efter og åbn Python Skal.

Trin 10) Bekræft at installationen fungerer ved at køre kommandoen nedenfor:
import nltk

Hvis der ikke vises nogen fejl, er installationen fuldført.
Installation af NLTK i Mac/Linux
Installation af NLTK på Mac eller Linux kræver Python pakkehåndtering pip. Hvis pip ikke er installeret, skal du følge instruktionerne nedenfor for at fuldføre processen.
Trin 1) Opdater pakkeindekset af typing kommandoen nedenfor:
sudo apt update
Trin 2) Installer pip til Python 3:
sudo apt install python3-pip
Du kan også installere pip via easy_install:
sudo apt-get install python-setuptools python-dev build-essential
Når easy_install er installeret, skal du køre kommandoen nedenfor for at installere pip:
sudo easy_install pip
Trin 3) Brug følgende kommando til at installere NLTK:
sudo pip install -U nltk sudo pip3 install -U nltk
Installation af NLTK gennem Anaconda
Trin 1) Installer Anaconda ved at besøge https://www.anaconda.com/products/individual og vælge Python version du har brug for.

Bemærk: Se denne vejledning for detaljerede trin til Installer Anaconda.
Trin 2) I Anaconda-prompten:
- Indtast kommandoen:
conda install -c anaconda nltk
- RevSe oplysningerne om pakkeopgradering, nedgradering og installation, og skriv derefter ja.
- NLTK er downloadet og installeret.

NLTK datasæt
NLTK-modulet leveres med mange datasæt, som du skal downloade før brug. Teknisk set kaldes hvert datasæt et corpusAlmindelige eksempler inkluderer stopord, Gutenberg, rammenet_v15, store_grammatikker, brunog wordnet.
Sådan downloader du alle NLTK-pakker
Trin 1) Kør Python tolk in Windows eller Linux.
Trin 2)
- Indtast kommandoerne:
import nltk nltk.download ()
- NLTK Downloader-vinduet åbnes. Klik på knappen Download for at hente datasættet. Denne proces tager tid afhængigt af din internetforbindelse.

BEMÆRK VENLIGST: Du kan ændre downloadplaceringen ved at klikke på Filer > Skift downloadmappe.

Trin 3) For at teste de installerede data skal du bruge følgende kode:
>>> from nltk.corpus import brown >>>brown.words()
['The', 'Fulton', 'County', 'Grand', 'Jury', 'sagde', …]

Kørsel af NLP-scriptet
Dette afsnit forklarer, hvordan et NLP-script kører på en lokal pc. Det rigtige biblioteksvalg afhænger af dine behov. Se den officielle liste over NLP biblioteker for alternativer som spaCy, gensim og TextBlob.
Sådan kører du NLTK-script
Trin 1) Kopier koden i dit yndlingskodeeditor, og gem filen som NLTKsample.py:
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
filterdText=tokenizer.tokenize('Hello Guru99, You have build a very good site and I love visiting your site.')
print(filterdText)

Code Forklaring:
- Formålet med dette program er at fjerne alle former for tegnsætning fra en given tekst. Vi importerede "RegexpTokenizer", et modul af NLTK der fjerner ethvert udtryk, symbol, tegn eller numerisk værdi, du vælger.
- Et regulært udtryk sendes til modulet “RegexpTokenizer”.
- Teksten tokeniseres ved hjælp af "tokenize"-metoden, og outputtet gemmes i variablen "filterdText".
- Resultatet udskrives ved hjælp af “print()”.
Trin 2) I kommandoprompten:
- Naviger til den placering, hvor du gemte filen.
- Kør kommandoen
python NLTKsample.py.

Udgangen er:
['Hej', 'Guru99', 'Du', 'har', 'bygge', 'en', 'meget', 'god', 'sted', 'og', 'jeg', 'elsker', 'besøger', 'din', 'sted']