Breadth First Search (BFS) Algoritme med EKSEMPEL
⚡ Smart opsummering
Breadth First Search (BFS) er en algoritme, der gennemløber en graf niveau for niveau og besøger alle naboer til en node, før den bevæger sig dybere. Den bruger en FIFO-kø og finder den korteste sti i uvægtede grafer uden uendelige løkker.

Hvad er BFS Algorithm (Bredth-First Search)?
Bredde-først-søgning (BFS) er en algoritme, der bruges til at tegne data grafisk, søge i et træ eller gennemgå strukturer. Den fulde form af BFS er bredde-først-søgning.
Algoritmen besøger og markerer effektivt alle nøgleknuder i en graf på en nøjagtig breddevis måde. Denne algoritme vælger en enkelt node (initial- eller kildepunkt) i en graf og besøger derefter alle noder, der støder op til den valgte node. Husk, at BFS får adgang til disse noder én efter én.
Når algoritmen besøger og markerer startknudepunktet, bevæger den sig mod de nærmeste ubesøgte knudepunkter og analyserer dem. Når de er besøgt, er alle noder markeret. Disse iterationer fortsætter, indtil alle knudepunkterne i grafen er blevet besøgt og markeret.
Hvad er Graph-traversals?
En grafgennemgang er en almindeligt anvendt metode til at lokalisere toppunktet i grafen. Det er en avanceret søgealgoritme, der kan analysere grafen med hastighed og præcision sammen med markering af rækkefølgen af de besøgte hjørner. Denne proces giver dig mulighed for hurtigt at besøge hver knude i en graf uden at være låst i en uendelig løkke.
Arkitekturen af BFS algoritme
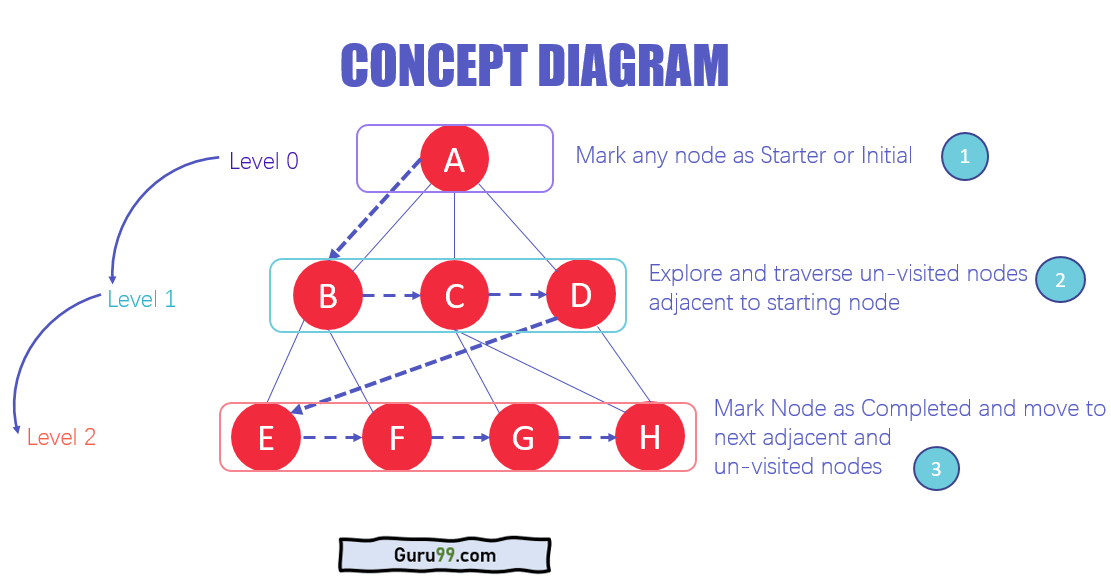
- På de forskellige dataniveauer kan du markere enhver node som start- eller initialnode for at begynde at krydse. BFS'en vil besøge noden, markere den som besøgt og placere den i køen.
- Nu vil BFS'en besøge de nærmeste og ubesøgte noder og markere dem. Disse værdier føjes også til køen. Køen fungerer på FIFO model.
- På lignende måde analyseres, markeres og føjes de resterende nærmeste og ubesøgte noder på grafen til køen. Disse elementer slettes fra køen, efterhånden som de modtages, og udskrives som resultat.
Hvorfor har vi brug for BFS-algoritme?
Der er adskillige grunde til at bruge BFS-algoritmen til at søge i dit datasæt. Nogle af de vigtigste aspekter, der gør denne algoritme til dit førstevalg, er:
- BFS er nyttig til at analysere knudepunkterne i en graf og konstruere den korteste vej til at krydse gennem disse.
- BFS kan krydse en graf i det mindste antal iterationer.
- Arkitekturen af BFS-algoritmen er enkel og robust.
- Resultatet af BFS-algoritmen har et højt niveau af nøjagtighed i sammenligning med andre algoritmer.
- BFS-iterationer er problemfrie, og der er ingen mulighed for, at denne algoritme bliver fanget af et problem med uendelig sløjfe.
Hvordan virker BFS-algoritmen?
Grafgennemgang kræver, at algoritmen besøger, tjekker og/eller opdaterer hver eneste ubesøgte node i en trælignende struktur. Grafgennemgange er kategoriseret efter den rækkefølge, de besøger knudepunkterne på grafen i.
BFS-algoritmen starter operationen fra den første eller startnode i en graf og gennemgår den grundigt. Når først den har krydset den indledende node, besøges og markeres det næste ikke-gennemløbede toppunkt i grafen.
Derfor kan man sige, at alle knuder, der støder op til det aktuelle hjørne, besøges og gennemløbes i den første iteration. En simpel kømetode anvendes til at implementere en BFS-algoritme, og den består af følgende trin:
Trin 1)

Hvert knudepunkt eller knudepunkt i grafen er kendt. For eksempel kan du markere noden som V.
Trin 2)

Hvis hjørne V ikke tilgås, skal hjørne V tilføjes til BFS-køen.
Trin 3)

Start BFS-søgningen, og marker hjørne V som besøgt efter afslutning.
Trin 4)

BFS-køen er stadig ikke tom, og fjern derfor toppunktet V på grafen fra køen.
Trin 5)

Hent alle de resterende hjørner på grafen, der støder op til hjørnet V.
Trin 6)

For hvert tilstødende hjørne, lad os sige V1, hvis det ikke er besøgt endnu, tilføj så V1 til BFS-køen.
Trin 7)

BFS vil besøge V1, markere den som besøgt og slette den fra køen.
Eksempel BFS-algoritme
Trin 1)

Du har en graf med syv tal fra 0 til 6.
Trin 2)

0 eller nul er blevet markeret som en rodnode.
Trin 3)

0 besøges, markeres og indsættes i køens datastruktur.
Trin 4)
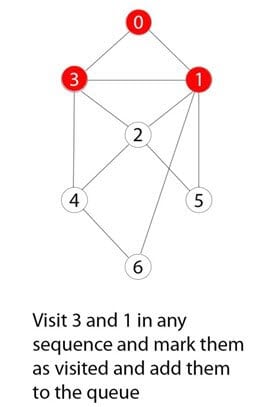
De resterende 0-tilstødende og ubesøgte noder besøges, markeres og indsættes i køen.
Trin 5)

Gennemgående iterationer gentages, indtil alle noder er besøgt.
Regler for BFS Algorithm
Her er vigtige regler for brug af BFS-algoritmen:
- En kø (FIFO – Først ind, først ud) datastruktur bruges af BFS.
- Du markerer en hvilken som helst node i grafen som roden og begynder at gennemløbe dataene fra den.
- BFS gennemløber alle noderne i grafen og fortsætter med at slippeping dem som færdige.
- BFS besøger en tilstødende ubesøgt node, markerer den som udført og indsætter den i en kø.
- Den fjerner det forrige hjørne fra køen, hvis der ikke findes et tilstødende hjørne.
- BFS-algoritmen itererer, indtil alle hjørner i grafen er gennemløbet og markeret som fuldført.
- Der er ingen sløjfer forårsaget af BFS under passage af data fra nogen knude.
Anvendelser af BFS Algorithm
Lad os tage et kig på nogle af de virkelige applikationer, hvor en BFS-algoritmeimplementering kan være yderst effektiv.
- Uvægtede grafer: BFS-algoritmen kan nemt oprette den korteste sti og et minimalt udspændende træ for at besøge alle grafens hjørner på kortest mulig tid med høj nøjagtighed.
- P2P-netværk: BFS kan implementeres til at lokalisere alle de nærmeste eller tilstødende noder i et peer-to-peer-netværk. Dette vil finde de nødvendige data hurtigere.
- Webcrawlere: Søgemaskiner eller webcrawlere kan nemt bygge flere niveauer af indekser ved at bruge BFS. BFS-implementering starter fra kilden, som er websiden, og derefter besøger den alle links fra den kilde.
- Navigationssystemer: BFS kan hjælpe med at finde alle de nærliggende steder fra hoved- eller kildeplaceringen.
- Netværksudsendelse: En udsendt pakke styres af BFS-algoritmen til at finde og nå alle de noder, den har adressen til.