Vkládání slov a Word2Vec s příkladem
⚡ Chytré shrnutí
Word Embedding a Word2Vec převádějí text na husté číselné vektory, takže modely strojového učení rozpoznávají slova s podobným významem. Tento zdroj vysvětluje techniku, její architektury CBOW a Skip-Gram, aktivační funkce a kompletní implementaci Gensimu pro reálné aplikace.
Co je to vkládání slov?
Vkládání slov je typ reprezentace slov, který umožňuje algoritmům strojového učení rozumět slovům s podobným významem. Jedná se o techniku modelování jazyka a učení rysů, která mapuje slova do vektorů reálných čísel pomocí neuronových sítí, pravděpodobnostních modelů nebo redukce dimenzí na matici společného výskytu slov. Některé modely pro vkládání slov jsou Word2vec (Google), GloVe (Stanford) a fastText (Facebook).
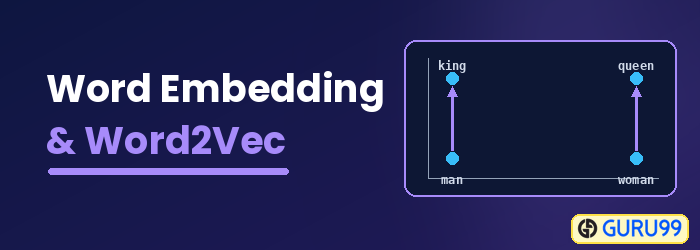
Vkládání slov se také nazývá distribuovaný sémantický model, distribuovaný reprezentovaný model, sémantický vektorový prostor nebo model vektorového prostoru. Při čtení těchto názvů narazíte na slovo sémantický, což znamená seskupování podobných slov. Například ovoce jako jablko, mango a banán by mělo být umístěno blízko sebe, zatímco knihy budou umístěny daleko od těchto slov. V širším smyslu vkládání slov vytvoří vektor ovoce, který je umístěn daleko od vektorové reprezentace knih.
Kde se používá Word Embedding?
Vkládání slov pomáhá s generováním rysů, shlukováním dokumentů, klasifikací textu a zpracováním přirozeného jazyka. Pojďme si tyto aplikace vyjmenovat a každou z nich prodiskutovat.
- Vypočítejte podobná slova: Vkládání slov se používá k navrhování slov podobných slovu, které je podrobeno predikčnímu modelu. Spolu s tím navrhuje také slova odlišná, stejně jako nejběžnější slova.
- Vytvořte skupinu příbuzných slov: Používá se pro sémantickou skupinuping, který seskupuje věci s podobnými vlastnostmi a odsouvá věci odlišné od sebe.
- Funkce pro klasifikaci textu: Text je mapován do polí vektorů, které jsou do modelu zadávány pro trénování i predikci. Textové klasifikační modely nelze trénovat na řetězcích, takže tento systém převádí text do strojově trénovatelné formy. Jeho funkce pro sémantické budování dále pomáhají při klasifikaci založené na textu.
- Shlukování dokumentů: Toto je další aplikace, kde se široce používají Word Embedding a Word2vec.
- Zpracování přirozeného jazyka: Existuje mnoho aplikací, kde je vkládání slov užitečné a vítězí nad funkcemi extracfáze, jako je označování slovních druhů, analýza sentimentu a syntaktická analýza.
Nyní, když chápete, kde se vkládání slov používá, podívejme se na nejoblíbenější model používaný k vytváření těchto vkládání.
Co je Word2vec?
Word2vec je technika nebo model, který vytváří vnoření slov pro lepší reprezentaci slov. Jedná se o metodu zpracování přirozeného jazyka, která zachycuje velké množství přesných syntaktických a sémantických vztahů mezi slovy. Jedná se o mělkou dvouvrstvou neuronovou síť, která dokáže detekovat synonymní slova a po natrénování navrhovat další slova pro částečné věty.
Než budeme pokračovat, podívejte se prosím na rozdíl mezi mělkou a hlubokou neuronovou sítí, jak je znázorněno v níže uvedeném příkladu vkládání Wordu:
Mělká neuronová síť se skládá pouze z jedné skryté vrstvy mezi vstupem a výstupem, zatímco hluboká neuronová síť obsahuje více skrytých vrstev mezi vstupem a výstupem. Vstup je podroben uzlům, zatímco skrytá vrstva, stejně jako výstupní vrstva, obsahuje neurony.
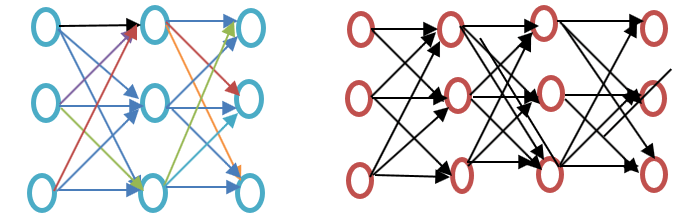
Word2vec je dvouvrstvá síť, kde je vstup, jedna skrytá vrstva a výstup.
Word2vec vyvinula skupina výzkumníků v čele s Tomášem Mikolovem. GoogleWord2vec je lepší a efektivnější než model latentní sémantické analýzy.
Proč Word2vec?
Word2vec reprezentuje slova ve vektorovém prostoru. Slova jsou reprezentována ve formě vektorů a jejich umístění je provedeno tak, že slova s podobným významem se objevují pohromadě a slova s různým významem se nacházejí daleko od sebe. Tomu se také říká sémantický vztah. Neuronové sítě nerozumí textu, ale pouze číslům. Vkládání slov (Word Embedding) poskytuje způsob, jak převést text na číselný vektor.
Word2vec rekonstruuje jazykový kontext slov. Než budeme pokračovat, pojďme si vysvětlit, co je jazykový kontext. Obecně platí, že když mluvíme nebo píšeme, abychom komunikovali, ostatní lidé se snaží zjistit účel věty. Například: „Jaká je teplota v Indii?“ Zde je kontext takový, že uživatel chce znát „teplotu v Indii“. Stručně řečeno, hlavním cílem věty je kontext. Slova nebo věty obklopující mluvený nebo psaný jazyk pomáhají určit význam kontextu. Word2vec se učí vektorovou reprezentaci slov prostřednictvím těchto kontextů.
Co dělá Word2vec?
Před vložením Wordu
Je důležité vědět, jaký přístup byl použit před vkládáním slov a jaké jsou jeho nevýhody, a poté se podíváme, jak tyto nevýhody překonává vkládání slov pomocí přístupu Word2vec. Nakonec se přesuneme k tomu, jak Word2vec funguje, protože je důležité pochopit jeho fungování.
Přístup k latentní sémantické analýze
Toto je přístup, který se používal před vkládáním slov. Používal koncept „bagu slov“, kde jsou slova reprezentována ve formě kódovaných vektorů. Jedná se o řídkou vektorovou reprezentaci, kde dimenze je rovna velikosti slovní zásoby. Pokud se slovo ve slovníku vyskytuje, započítá se; jinak se nepočítá. Více informací naleznete v níže uvedeném programu.
Příklad Word2vec

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Výstup:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Vysvětlení
- CountVectorizer je modul používaný k ukládání slovní zásoby na základě jejího zařazení. Tento modul je importován ze sklearn.
- Vytvořte objekt pomocí třídy CountVectorizer.
- Zapište data do seznamu, který má být vložen do CountVectorizeru.
- Data se vejdou do objektu vytvořeného z třídy CountVectorizer.
- Pro počítání slov v datech pomocí slovní zásoby použijte metodu „bag-of-words“. Pokud slovo nebo token ve slovní zásobě není k dispozici, pak se taková pozice v indexu nastaví na nulu.
- Proměnná v řádku 5, kterou je x, je převedena na pole (metoda dostupná pro x). To poskytuje počet všech tokenů ve větě nebo seznamu uvedeném v řádku 3.
- Toto ukazuje prvky, které jsou součástí slovní zásoby, když je doplněna pomocí dat v řádku 4.
V latentně sémantickém přístupu řádek představuje unikátní slova, zatímco sloupec představuje počet výskytů daného slova v dokumentu. Jedná se o reprezentaci slov ve formě matice dokumentů. K výpočtu četnosti slov v dokumentu se používá metoda TF-IDF (Term Frequency-Inverse Document Frequency), což je četnost termínu v dokumentu dělená četností termínu v celém korpusu.
Nedostatek metody Bag of Words
- Ignoruje pořadí slov, například je to špatné = špatné je tohle.
- Ignoruje kontext slov. Předpokládejme, že napíšeme větu „Miloval knihy. Vzdělání se nejlépe nachází v knihách.“ Vytvořilo by to dva vektory: jeden pro „Miloval knihy“ a druhý pro „Vzdělání se nejlépe nachází v knihách“. Oba by to považovalo za ortogonální, což je činí nezávislými, ale ve skutečnosti spolu souvisejí.
Pro překonání těchto omezení bylo vyvinuto vkládání slov a Word2vec je jedním z přístupů použitých k jeho implementaci.
Jak Word2vec funguje?
Word2vec se učí slovo předpovídáním jeho okolního kontextu. Vezměme si například slovo „He“ miluje Fotbal."
Chceme vypočítat Word2vec pro slovo: miluje.
Předpokládat:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Slovo miluje pohybuje se nad každým slovem v korpusu. Kódují se syntaktické i sémantické vztahy mezi slovy. To pomáhá při hledání podobných a analogických slov.
Všechny náhodné rysy slova miluje se vypočítávají. Tyto vlastnosti se mění nebo aktualizují s ohledem na sousední nebo kontextová slova s pomocí Zpětná propagace metoda.
Dalším způsobem učení je, že pokud jsou kontexty dvou slov podobné nebo dvě slova mají podobné rysy, pak jsou taková slova příbuzná.
Word2vec Architecture
Word2vec používá dvě architektury:
- Nepřetržitý pytel slov (CBOW)
- Přeskočit gram
Než budeme pokračovat, pojďme si probrat, proč jsou tyto architektury nebo modely důležité z hlediska reprezentace slov. Učení reprezentace slov je v podstatě bez dozoru, ale pro trénování modelu jsou potřeba cíle/návěstí. Skip-gram a CBOW převádějí neřízenou reprezentaci do řízené formy pro trénování modelu.
V CBOW je aktuální slovo predikováno pomocí okna okolních kontextových oken. Například, pokud wi-1, wi-2, wi + 1, wi + 2 jsou dána slova nebo kontext, tento model poskytne wi.
Skip-Gram provádí opak CBOW, což znamená, že předpovídá danou sekvenci nebo kontext ze slova. Pro pochopení můžete příklad obrátit. Pokud wi je dáno, bude to předpovídat kontext, nebo wi-1, wi-2, wi + 1, wi + 2.
Word2vec nabízí možnost volby mezi CBOW (Continuous Bag of Words) a skip-gramem. Tyto parametry jsou zadávány během trénování modelu. Lze zvolit použití negativního vzorkování nebo hierarchické softmax vrstvy.
Nepřetržitý pytel slov
Nakresleme si jednoduchý příkladový diagram Word2vec, abychom pochopili architekturu spojitého pytle slov.

Vypočítejme rovnice matematicky. Předpokládejme, že V je velikost slovní zásoby a N je velikost skryté vrstvy. Vstup je definován jako { xi-1, Xi-2, Xi + 1, Xi + 2 }. Váhovou matici získáme vynásobením V * N. Další matici získáme vynásobením vstupního vektoru váhovou maticí. To lze také pochopit pomocí následující rovnice.
h = xitW
kde xit a W jsou vstupní vektor a váhová matice.
Pro výpočet shody mezi kontextem a následujícím slovem se prosím podívejte na níže uvedenou rovnici.
u = předpokládaná reprezentace * h
kde předpokládaná reprezentace je získána z modelu ve výše uvedené rovnici.
Skip-Gram model
Přístup Skip-Gram se používá k predikci věty na základě zadaného slova. Pro lepší pochopení si nakresleme diagram znázorněný v níže uvedeném příkladu Word2vec.

Lze to považovat za opak modelu Continuous Bag of Words, kde vstupem je slovo a model poskytuje kontext nebo posloupnost. Můžeme také usoudit, že cíl je přiveden na vstup a výstupní vrstva je několikrát replikována, aby se přizpůsobila zvolenému počtu kontextových slov. Vektor chyb ze všech výstupních vrstev se sečte pro úpravu vah metodou zpětného šíření.
Jaký model vybrat?
CBOW je několikanásobně rychlejší než skip-gram a poskytuje lepší frekvenci pro častá slova, zatímco skip-gram potřebuje malé množství trénovacích dat a reprezentuje i vzácná slova nebo fráze. Níže uvedená tabulka porovnává obě architektury na první pohled.
| Vzhled | CBOW (Centrum volného obchodování) | Skip-Gram |
|---|---|---|
| Předpověď | Předpovídá cílové slovo z kontextu | Předpovídá kontext z cílového slova |
| Rychlost tréninku | Rychlejší | Pomaleji |
| Častá slova | Vyšší přesnost | Nižší přesnost |
| Vzácná slova | Slabší zastoupení | Silnější zastoupení |
| Údaje o školení | Potřebuje více dat | Funguje s menším množstvím dat |
Vztah mezi Word2vec a NLTK
NLTK je přirozené Language ToolSada. Používá se pro předzpracování textu. Lze provádět různé operace, jako je označování slovních druhů, lematizace, odstraňování stop-slov, odstraňování vzácných nebo nejméně používaných slov. Pomáhá s čištěním textu a také s přípravou rysů z efektivních slov. Na druhou stranu se Word2vec používá pro sémantické (úzce související položky dohromady) a syntaktické (sekvenční) porovnávání. Pomocí Word2vec lze najít podobná slova, odlišná slova, dimenzionální redukci a mnoho dalších. Další důležitou funkcí Word2vec je převod vícerozměrné reprezentace textu na méněrozměrné vektory.
Kde používat NLTK a Word2vec?
Pokud je třeba provádět některé obecné úkoly, jak je uvedeno výše, jako je tokenizace, tagování POS a parsování, je nutné zvolit NLTK, zatímco pro predikci slov podle kontextu, modelování témat nebo podobnosti dokumentů je nutné použít Word2vec.
Vztah NLTK a Word2vec pomocí kódu
NLTK a Word2vec lze použít společně k nalezení podobných slovních reprezentací nebo syntaktické shody. Sada nástrojů NLTK může být použita k načtení mnoha balíčků, které jsou součástí NLTK, a model lze vytvořit pomocí Word2vec. Ten lze poté testovat na slovech v reálném čase. Podívejme se na kombinaci obou v následujícím kódu. Před dalším zpracováním se prosím podívejte na korpusy, které NLTK poskytuje. Můžete si je stáhnout pomocí příkazu:
nltk(nltk.download('all'))

Kód naleznete na snímku obrazovky.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Výstup:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Vysvětlení Code
- Knihovna nltk je importována, odkud si můžete stáhnout korpus abc, který použijeme v dalším kroku.
- Gensim je importován. Pokud Gensim Word2vec není nainstalován, nainstalujte jej pomocí příkazu „pip3 install gensim“. Viz snímek obrazovky níže.

- Importujte korpus abc, který byl stažen pomocí nltk.download('abc').
- Předejte soubory modelu Word2vec, který je importován pomocí Gensimu, jako věty.
- Slovní zásoba je uložena ve formě proměnné.
- Model je testován na vzorovém slově věda, protože tyto soubory souvisí s vědou.
- Zde model předpovídá podobné slovo „věda“.
Aktivátory a Word2Vec
Aktivační funkce neuronu definuje výstup daného neuronu na základě dané sady vstupů. Je biologicky inspirována aktivitou v našem mozku, kde jsou různé neurony aktivovány pomocí různých podnětů. Pojďme si aktivační funkci znázornit pomocí následujícího diagramu.

Zde x1, x2, … x4 jsou uzly neuronové sítě.
w1, w2, w3 jsou váhy uzlů.
Součet (Σ) všech vah a hodnot uzlů funguje jako aktivační funkce.
Proč Aktivační funkce?
Pokud se nepoužije aktivační funkce, výstup by byl lineární, ale funkčnost lineární funkce je omezená. Pro dosažení složitých funkcí, jako je detekce objektů, klasifikace obrazu, typing text pomocí hlasu a mnoho dalších nelineárních výstupů je potřeba aktivační funkce.
Jak se vypočítá aktivační vrstva ve vkládání slova (Word2vec)
Vrstva Softmax (normalizovaná exponenciální funkce) je funkce výstupní vrstvy, která aktivuje nebo spouští každý uzel. Dalším používaným přístupem je hierarchický softmax, kde se složitost vypočítává pomocí O(log2V), zatímco v softmaxu je to O(V), kde V je velikost slovní zásoby. Rozdíl mezi nimi spočívá ve snížení složitosti v hierarchické vrstvě softmaxu. Pro pochopení jeho funkčnosti se prosím podívejte na níže uvedený příklad vkládání slov:

Předpokládejme, že chceme vypočítat pravděpodobnost pozorování slova láska za daného kontextu. Tok z kořene do koncového uzlu se nejprve přesune do uzlu 2 a poté do uzlu 5. Pokud tedy máme slovní zásobu o velikosti 8, jsou potřeba pouze tři výpočty. To umožňuje rozložit výpočet pravděpodobnosti jednoho slova (láska).
Jaké další možnosti jsou k dispozici kromě Hierarchical Softmax?
V obecném smyslu jsou dostupné možnosti vkládání slov Differentiated Softmax, CNN-Softmax, Importance Sampling, Adaptive Importance Sampling, Noise Contrastive Estimation, Negativní Sampling, Self-Normalization a Infertile Normalization.
Když mluvíme konkrétně o Word2vec, máme k dispozici negativní vzorky.
Negativní vzorkování je způsob vzorkování trénovacích dat. Je to do jisté míry podobné stochastickému gradientnímu sestupu, ale s určitým rozdílem. Negativní vzorkování hledá pouze negativní trénovací příklady. Je založeno na kontrastním odhadu šumu a náhodně vzorkuje slova, která nejsou v kontextu. Jedná se o rychlou trénovací metodu, která náhodně vybírá kontext. Pokud se predikované slovo objeví v náhodně zvoleném kontextu, oba vektory jsou si blízko.
Jaký závěr lze vyvodit?
Aktivátory aktivují neurony stejně jako naše neurony aktivují externí podněty. Vrstva Softmax je jednou z funkcí výstupní vrstvy, která aktivuje neurony v případě vkládání slov. Ve Word2vec máme možnosti, jako je hierarchický softmax a negativní vzorkování. Pomocí aktivátorů lze převést lineární funkci na nelineární a pomocí těchto funkcí lze implementovat komplexní algoritmus strojového učení.
Co je Gensim?
Gensim je open-source sada nástrojů pro modelování témat a zpracování přirozeného jazyka, která je implementována v Python a Cython. Sada nástrojů Gensim umožňuje uživatelům importovat Word2vec pro modelování témat a objevovat skryté struktury v textu. Gensim poskytuje nejen implementaci Word2vec, ale také Doc2vec a FastText.
Tato část se zaměřuje na Word2vec, takže se budeme držet aktuálního tématu.
Jak implementovat Word2vec pomocí Gensim
Doposud jsme probírali, co je Word2vec, jeho různé architektury, proč dochází k přechodu od pytle slov k Word2vec, vztah mezi Word2vec a NLTK s živým kódem a aktivační funkce.
Níže je uveden podrobný postup implementace Word2vec pomocí Gensimu:
Krok 1) Sběr dat
Prvním krokem k implementaci jakéhokoli modelu strojového učení nebo implementaci zpracování přirozeného jazyka je sběr dat.
Dodržujte prosím data pro vytvoření inteligentního chatbota, jak je znázorněno v níže uvedeném příkladu Gensim Word2vec.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Z dat vyplývá toto:
- Tato data obsahují tři věci: tag, vzor a odpovědi. Tag představuje záměr (co je předmětem diskuse).
- Data jsou ve formátu JSON.
- Vzor je otázka, kterou uživatelé položí botu.
- Odpovědi jsou odpovědi, které chatbot poskytne na odpovídající otázku/vzor.
Krok 2) Předzpracování dat
Je velmi důležité zpracovat nezpracovaná data. Pokud jsou do stroje přiváděna vyčištěná data, model bude reagovat přesněji a bude se data učit efektivněji.
Tento krok zahrnuje odstranění stop slov, odvozených slov, nepotřebných slov atd. Než budete pokračovat, je důležité načíst data a převést je do datového rámce. Prohlédněte si prosím níže uvedený kód.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Vysvětlení Code:
- Protože data jsou ve formátu JSON, importuje se JSON.
- Soubor je uložen v proměnné.
- Soubor se otevře a načte do datové proměnné.
Data jsou nyní importována a je čas je převést do datového rámce. Další krok naleznete v níže uvedeném kódu.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Vysvětlení Code:
1. Data jsou převedena do datového rámce pomocí PANDAS, který byl importován výše.
2. Převede seznam ve vzorcích sloupců na řetězec.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Vysvětlení:
1. Anglická stop slova se importují pomocí modulu stop-word ze sady nástrojů nltk.
2. Všechna slova textu jsou převedena na malá písmena pomocí podmínky for a funkce lambda. A Funkce lambda je anonymní funkce.
3. Všechny řádky textu v datovém rámci jsou kontrolovány na interpunkci řetězců a tyto řádky jsou filtrovány.
4. Znaky jako čísla nebo tečky se odstraňují pomocí regulárního výrazu.
5. Digits jsou z textu odstraněny.
6. Stop slova jsou v této fázi odstraněna.
7. Slova jsou nyní filtrována a různé tvary stejného slova jsou odstraněny pomocí lematizace. Tímto jsme dokončili předzpracování dat.
Výstup:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Krok 3) Budování neuronové sítě pomocí Word2vec
Nyní je čas vytvořit model pomocí modulu Gensim Word2vec. Musíme importovat Word2vec z Gensimu. Udělejme to, poté jej sestavíme a v závěrečné fázi model ověříme na datech v reálném čase.
from gensim.models import Word2Vec
Nyní můžeme úspěšně sestavit model pomocí Word2Vec. Prohlédněte si další řádek kódu, kde se dozvíte, jak model pomocí Word2Vec vytvořit. Text je modelu poskytován ve formě seznamu, takže text z datového rámce převedeme na seznam pomocí níže uvedeného kódu.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Vysvětlení Code:
1. Vytvořen byl soubor bigger_list, kam se připojuje vnitřní seznam. Toto je formát, který se předává modelu Word2Vec.
2. Je implementována smyčka a každý záznam ve sloupci vzorů datového rámce je iterován.
3. Každý prvek sloupcových vzorů je rozdělen a uložen ve vnitřním seznamu li.
4. Vnitřní seznam je doplněn vnějším seznamem.
5. Tento seznam je poskytnut modelu Word2Vec. Pojďme si vysvětlit některé zde uvedené parametry.
Min_count: Ignoruje všechna slova s celkovou frekvencí nižší než tato.
Velikost: Vypovídá o dimenzionalitě slovních vektorů.
Pracovníci: Toto jsou vlákna pro trénování modelu.
K dispozici jsou i další možnosti a některé důležité jsou vysvětleny níže.
Okno: Maximální vzdálenost mezi aktuálním a předpokládaným slovem ve větě.
Sg: Jedná se o trénovací algoritmus: 1 pro skip-gram a 0 pro souvislý pytel slov. Tyto algoritmy jsme podrobně probrali výše.
Hs: Pokud je toto 1, pak pro trénování používáme hierarchický softmax, a pokud 0, pak se používá záporné vzorkování.
Alpha: Počáteční míra učení.
Ukážeme konečný kód níže:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Krok 4) Uložení modelu
Model lze uložit ve formátu bin a souboru modelu. Bin je binární formát. Postup uložení modelu naleznete v následujících řádcích.
model.save("word2vec.model") model.save("model.bin")
Vysvětlení výše uvedeného kódu
1. Model je uložen ve formě souboru .model.
2. Model je uložen ve formě souboru .bin.
Tento model použijeme k testování v reálném čase, například k vyhledávání podobných slov, odlišných slov a nejběžnějších slov.
Krok 5) Načtení modelu a provedení testování v reálném čase
Model se načte pomocí následujícího kódu:
model = Word2Vec.load('model.bin')
Pokud chcete z něj vytisknout slovní zásobu, provedete to pomocí následujícího příkazu:
vocab = list(model.wv.vocab)
Podívejte se prosím na výsledek:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Krok 6) Kontrola většiny podobných slov
Uveďme věci prakticky:
similar_words = model.most_similar('thanks') print(similar_words)
Podívejte se prosím na výsledek:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Krok 7) Neodpovídá slovu z dodaných slov
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Dodali jsme slova 'Uvidíme se později, děkuji za návštěvu'. Toto vypíše nejméně podobné slovo z těchto slov. Spusťme tento kód a najděte výsledek.
Výsledek po provedení výše uvedeného kódu:
Thanks
Krok 8) Nalezení podobnosti mezi dvěma slovy
Toto udává výsledek z hlediska pravděpodobnosti podobnosti mezi dvěma slovy. Níže uvedený kód ukazuje, jak tuto sekci spustit.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Výsledek výše uvedeného kódu je následující:
0.13706
Podobná slova můžete dále najít spuštěním následujícího kódu:
similar = model.similar_by_word('kind') print(similar)
Výstup výše uvedeného kódu:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]