SQLite Dotaz: Select, Where, LIMIT, OFFSET, Count, Group By
⚡ Chytré shrnutí
SQLite Dotazy načítají a filtrují data pomocí klauzulí SELECT, FROM, WHERE, GROUP BY, ORDER BY a LIMIT. Kombinace těchto klauzulí s operátory, agregacemi, poddotazy a operacemi množin umožňuje číst, upravovat a sumarizovat záznamy z libovolného SQLite databáze.

Následující části se věnují čtení dat pomocí operátorů SELECT a FROM, filtrování řádků pomocí operátoru WHERE a jeho operátorů, řazení a omezování výsledků, agregačním funkcím, GROUP BY a HAVING, poddotazům, operacím s množinami, zpracování NULL, výrazům CASE a běžným tabulkovým výrazům.
Psát SQL dotazy v SQLite databáze, musíte vědět, jak fungují klauzule SELECT, FROM, WHERE, GROUP BY, ORDER BY a LIMIT a jak je používat.
Během tohoto tutoriálu se naučíte používat tyto klauzule a jak je psát SQLite doložky.
Čtení dat pomocí Select
Klauzule SELECT je hlavní příkaz, který používáte k dotazování SQLite databáze. V klauzuli SELECT uvedete, co vybrat. Ale před klauzulí select se podívejme, odkud můžeme vybrat data pomocí klauzule FROM.
Klauzule FROM se používá k určení, kde chcete vybrat data. V klauzuli from můžete zadat jednu nebo více tabulek nebo poddotazů, ze kterých chcete vybrat data, jak uvidíme později ve výukových programech.
Všimněte si, že pro všechny následující příklady musíte spustit sqlite3.exe a otevřít připojení k ukázkové databázi jako plynulé:
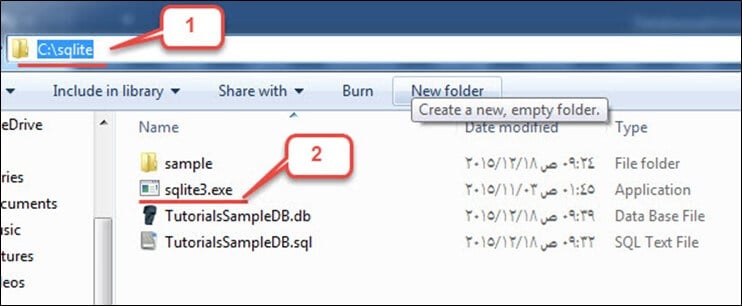
Krok 1) V tomto kroku,
Otevřete složku Tento počítač, přejděte do adresáře „C:\sqlite“ a poté otevřete soubor „sqlite3.exe“:
Krok 2) Otevřete databázi „TutorialsSampleDB.db“ pomocí následujícího příkazu:
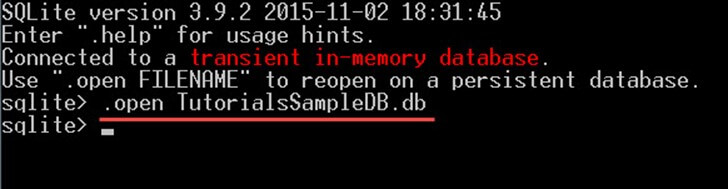
Nyní jste připraveni spustit jakýkoli typ dotazu na databázi.
V klauzuli SELECT můžete vybrat nejen název sloupce, ale máte spoustu dalších možností, jak určit, co vybrat. Takto:
SELECT *
Tento příkaz vybere všechny sloupce ze všech odkazovaných tabulek (nebo poddotazů) v klauzuli FROM. Například:
SELECT * FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
Tím vyberete všechny sloupce z tabulek studentů i tabulek oddělení:
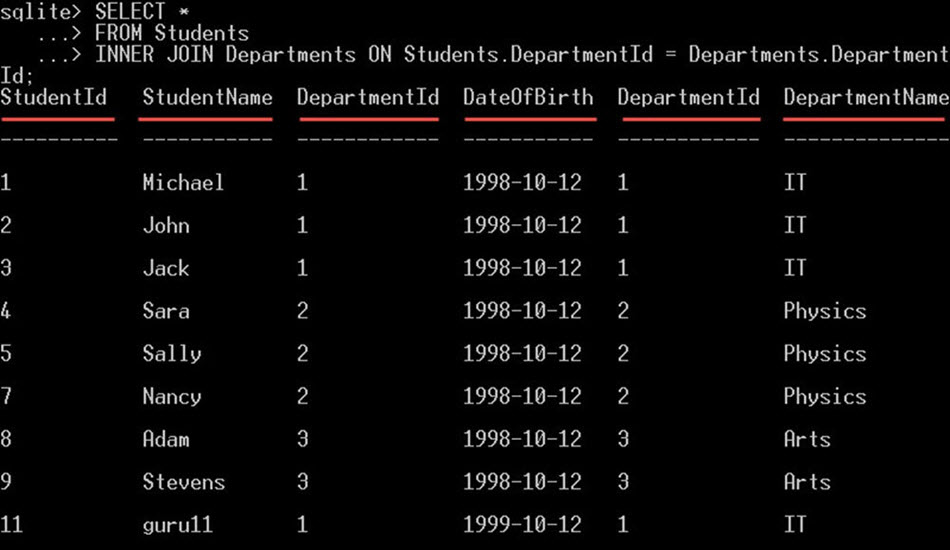
VYBERTE název tabulky.*
Tím vyberete všechny sloupce pouze z tabulky „název_tabulky“. Například:
SELECT Students.* FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
Tím vyberete pouze všechny sloupce z tabulky studentů:
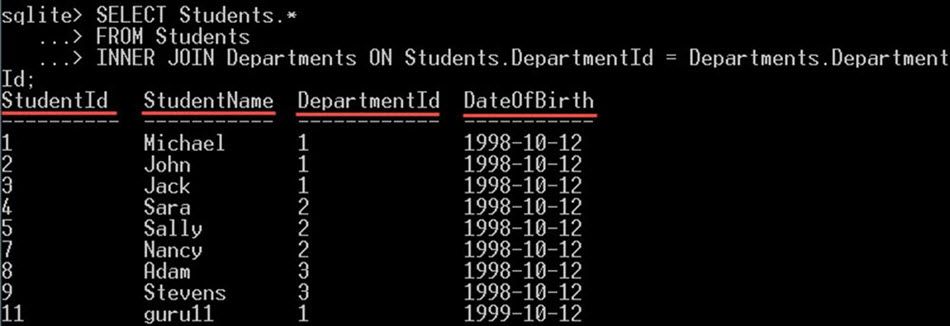
Doslovná hodnota
Doslovná hodnota je konstantní hodnota, kterou lze zadat v příkazu select. Doslovné hodnoty můžete normálně používat stejným způsobem, jako používáte názvy sloupců v klauzuli SELECT. Tyto doslovné hodnoty se zobrazí pro každý řádek z řádků vrácených dotazem SQL.
Zde je několik příkladů různých doslovných hodnot, které můžete vybrat:
- Numerický literál – čísla v libovolném formátu jako 1, 2.55, … atd.
- Řetězcové literály – Libovolný řetězec 'USA', 'toto je ukázkový text', … atd.
- NULL – hodnota NULL.
- Current_TIME – Ukáže vám aktuální čas.
- CURRENT_DATE – tím získáte aktuální datum.
To může být užitečné v některých situacích, kdy musíte vybrat konstantní hodnotu pro všechny vrácené řádky. Pokud například chcete vybrat všechny studenty z tabulky Studenti s novým sloupcem nazvaným země, který obsahuje hodnotu „USA“, můžete to udělat takto:
SELECT *, 'USA' AS Country FROM Students;
Tím získáte všechny sloupce studentů plus nový sloupec „Země“, jako je tento:
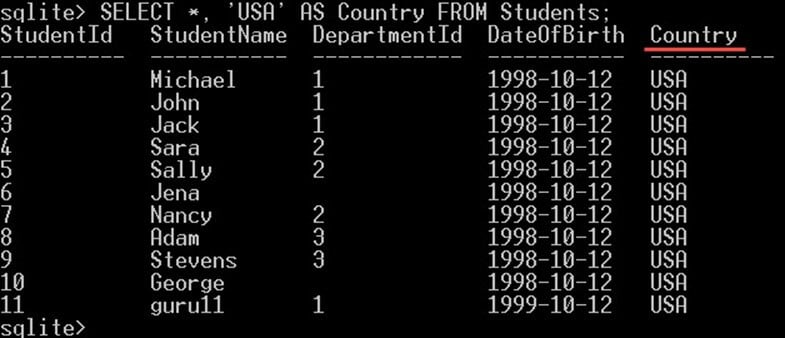
Všimněte si, že tento nový sloupec Země ve skutečnosti není novým sloupcem přidaným do tabulky. Je to virtuální sloupec, vytvořený v dotazu pro zobrazení výsledků a nebude se vytvářet v tabulce.
Jména a alias
Alias je nový název pro sloupec, který umožňuje vybrat sloupec s novým názvem. Aliasy sloupců jsou specifikovány pomocí klíčového slova „AS“.
Například, pokud chcete vybrat sloupec StudentName, který má být vrácen se „Student Name“ namísto „StudentName“, můžete mu přiřadit alias takto:
SELECT StudentName AS 'Student Name' FROM Students;
Tím získáte jména studentů se jménem „Student Name“ namísto „StudentName“ takto:

Všimněte si, že název sloupce je stále „StudentName“; sloupec StudentName je stále stejný, alias se v něm nemění.
Alias nezmění název sloupce; pouze změní zobrazovaný název v klauzuli SELECT.
Všimněte si také, že klíčové slovo „AS“ je volitelné, název aliasu můžete zadat i bez něj, něco takového:
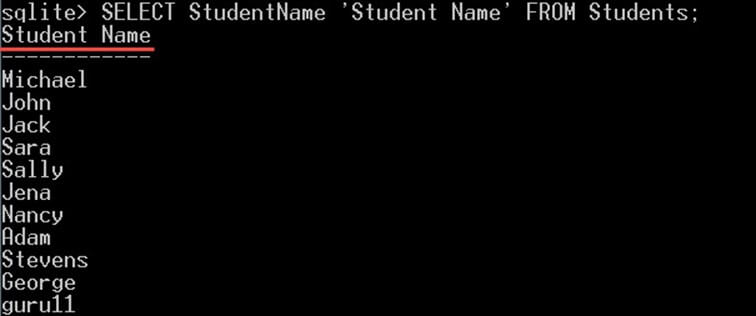
SELECT StudentName 'Student Name' FROM Students;
A dá vám přesně stejný výstup jako předchozí dotaz:
Tabulkám můžete také přidělit aliasy, nejen sloupce. Se stejným klíčovým slovem „AS“. Můžete například provést toto:
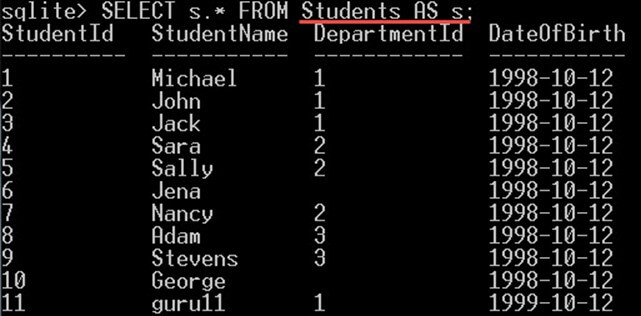
SELECT s.* FROM Students AS s;
Tím získáte všechny sloupce v tabulce Studenti:
To může být velmi užitečné, pokud se připojujete k více než jednomu stolu; místo opakování celého názvu tabulky v dotazu můžete každé tabulce přiřadit krátký alias. Například v následujícím dotazu:
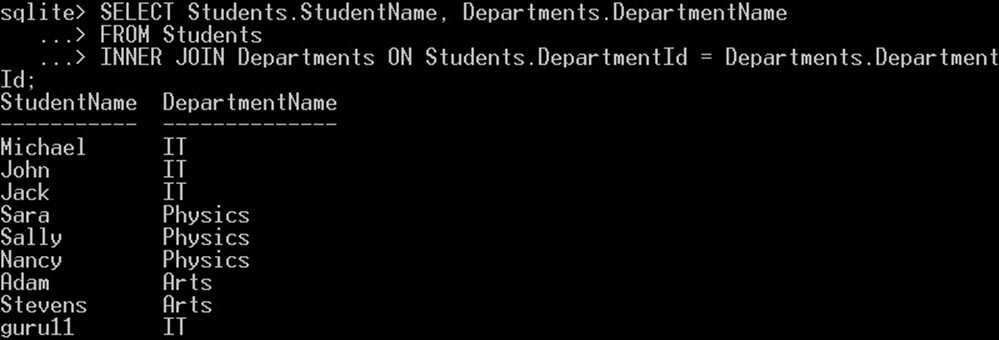
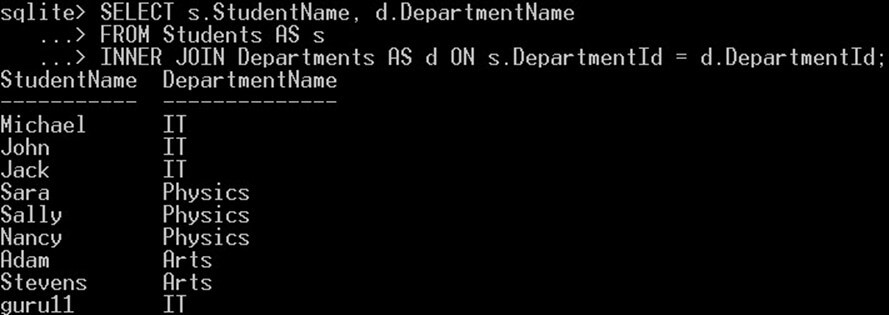
SELECT Students.StudentName, Departments.DepartmentName FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
Tento dotaz vybere jméno každého studenta z tabulky „Studenti“ a jeho název oddělení z tabulky „Oddělení“:
Stejný dotaz však lze napsat takto:
SELECT s.StudentName, d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
Tabulce Students jsme dali alias „s“ a tabulce departments alias „d“. Pak jsme místo použití celého názvu tabulky použili jejich aliasy k odkazování na ně. INNER JOIN spojuje dvě nebo více tabulek pomocí podmínky. V našem příkladu jsme spojili tabulku Students s tabulkou Departments se sloupcem DepartmentId. Podrobné vysvětlení INNER JOIN je také uvedeno v „SQLite Připojuje„tutoriál“.
Tím získáte přesný výstup jako předchozí dotaz:
KDE
Zápis SQL dotazů pomocí samotné klauzule SELECT s klauzulí FROM, jak jsme viděli v předchozí části, vám poskytne všechny řádky z tabulek. Pokud však chcete filtrovat vrácená data, musíte přidat klauzuli „WHERE“.
Klauzule WHERE se používá k filtrování výsledné sady vrácené dotazem SQL. Klauzule WHERE funguje takto:
- V klauzuli WHERE můžete zadat „výraz“.
- Tento výraz bude vyhodnocen pro každý řádek vrácený z tabulek zadaných v klauzuli FROM.
- Výraz bude vyhodnocen jako booleovský výraz s výsledkem buď true, false, nebo null.
- Potom budou vráceny pouze řádky, pro které byl výraz vyhodnocen s hodnotou true, a ty s nepravdivými nebo nulovými výsledky budou ignorovány a nebudou zahrnuty do sady výsledků.
Chcete-li filtrovat sadu výsledků pomocí klauzule WHERE, musíte použít výrazy a operátory.
Seznam operátorů v SQLite a jak je používat
V následující části vysvětlíme, jak můžete filtrovat pomocí výrazů a operátorů.
Výraz je jedna nebo více doslovných hodnot nebo sloupců vzájemně kombinovaných pomocí operátoru.
Všimněte si, že výrazy můžete použít jak v klauzuli SELECT, tak v klauzuli WHERE.
V následujících příkladech si vyzkoušíme výrazy a operátory v klauzuli select i v klauzuli WHERE. Abychom vám ukázali, jak fungují.
Existují různé typy výrazů a operátorů, které můžete zadat následovně:
SQLite operátor zřetězení „||“
Tento operátor se používá ke zřetězení jedné nebo více literálových hodnot nebo sloupců. Vytvoří jeden řetězec výsledků ze všech zřetězených literálových hodnot nebo sloupců. Například:
SELECT 'Id with Name: '|| StudentId || StudentName AS StudentIdWithName FROM Students;
Toto se zřetězí do nového aliasu „StudentIdWithName“:
- Doslovná řetězcová hodnota „Id s názvem:“
- s hodnotou sloupce „StudentId“ a
- s hodnotou ze sloupce „Jméno studenta“

SQLite Operátor CAST:
Operátor CAST se používá k převodu hodnoty z datový typ na jiný datový typ.
Například pokud máte číselnou hodnotu uloženou jako řetězec, například „'12.5'“ a chcete ji převést na číselnou hodnotu, můžete k tomu použít operátor CAST, například „CAST('12.5' AS REAL)“. Nebo pokud máte desetinnou hodnotu, například 12.5, a potřebujete získat pouze celočíselnou část, můžete ji převést na celé číslo, například „CAST(12.5 AS INTEGER)“.
Příklad
V následujícím příkazu se pokusíme převést různé hodnoty na jiné datové typy:
SELECT CAST('12.5' AS REAL) ToReal, CAST(12.5 AS INTEGER) AS ToInteger;
To vám dá:

Výsledek je následující:
- CAST('12.5' AS REAL) – hodnota '12.5' je řetězcová hodnota, bude převedena na hodnotu REAL.
- CAST(12.5 AS INTEGER) – hodnota 12.5 je dekadická hodnota, bude převedena na celočíselnou hodnotu. Desetinná část bude zkrácena a bude z ní 12.
SQLite Aritmetický Operators:
Vezměte dvě nebo více číselných literálových hodnot nebo číselných sloupců a vraťte jednu číselnou hodnotu. Podporované aritmetické operátory v SQLite jsou:
- Sčítání „+“ – udává součet dvou operandů.
- Vtracce „–“ – podřízenýtracts dva operandy a výsledkem je rozdíl.
- Násobení „*“ – součin dvou operandů.
- Připomínka (modulo) „%“ – udává zbytek, který vznikne dělením jednoho operandu druhým operandem.
- Dělení „/“ – vrací podíl, který vznikne dělením levého operandu pravým operandem.
Příklad:
V následujícím příkladu si vyzkoušíme pět aritmetických operátorů s doslovnými číselnými hodnotami ve stejné klauzuli select:
SELECT 25+6, 25-6, 25*6, 25%6, 25/6;
To vám dá:

Všimněte si, jak jsme zde použili příkaz SELECT bez klauzule FROM. A toto je povoleno SQLite pokud vybíráme doslovné hodnoty.
SQLite Porovnávací operátoři
Porovnejte dva operandy mezi sebou a vraťte hodnotu true nebo false následovně:
- „<“ – vrací hodnotu true, pokud je levý operand menší než pravý operand.
- „<=“ – vrací hodnotu true, pokud je levý operand menší nebo roven pravému operandu.
- „>“ – vrací hodnotu true, pokud je levý operand větší než pravý operand.
- „>=" – vrací hodnotu true, pokud je levý operand větší nebo roven pravému operandu.
- „=“ a „==“ – vrací hodnotu true, pokud jsou oba operandy stejné. Všimněte si, že oba operátory jsou stejné a není mezi nimi žádný rozdíl.
- „!=" a „<>" – vrátí hodnotu true, pokud se dva operandy neshodují. Všimněte si, že oba operátory jsou stejné a není mezi nimi žádný rozdíl.
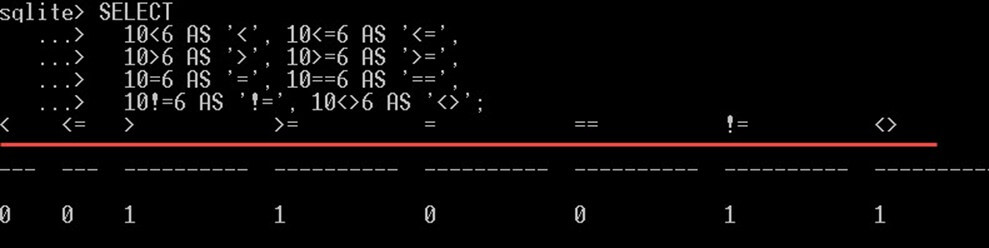
Všimněte si, že, SQLite vyjadřuje skutečnou hodnotu s 1 a nepravdivou hodnotu s 0.
Příklad:
SELECT 10<6 AS '<', 10<=6 AS '<=', 10>6 AS '>', 10>=6 AS '>=', 10=6 AS '=', 10==6 AS '==', 10!=6 AS '!=', 10<>6 AS '<>';
To dá něco takového:
SQLite Operátory shody vzorů
„LIKE“ – používá se pro porovnávání vzorů. Pomocí „LIKE“ můžete vyhledávat hodnoty, které odpovídají vzoru zadanému pomocí zástupného znaku.
Operand nalevo může být buď hodnota řetězcového literálu, nebo sloupec řetězce. Vzor lze specifikovat následovně:
- Obsahuje vzor. Například StudentName LIKE '%a%' – tato funkce vyhledá jména studentů, která obsahují písmeno „a“ na libovolné pozici ve sloupci StudentName.
- Začíná vzorem. Například „JménoStudenta LIKE 'a%'“ – vyhledá jména studentů, která začínají písmenem „a“.
- Končí daným vzorem. Například „JménoStudenta LIKE '%a'“ – Vyhledá jména studentů, která končí písmenem „a“.
- Hledání libovolného jednotlivého znaku v řetězci pomocí podtržítka „_“. Například „StudentName LIKE 'J___'“ – Vyhledávání jmen studentů, která mají délku 4 znaky. Musí začínat písmenem „J“ a za tímto písmenem může být libovolných tři další znaky.
Příklady shody vzorů:
Získejte jména studentů začínající písmenem „j“:
SELECT StudentName FROM Students WHERE StudentName LIKE 'j%';
Výsledek:

Získejte, aby jména studentů končila písmenem „y“:
SELECT StudentName FROM Students WHERE StudentName LIKE '%y';
Výsledek:

Získejte jména studentů, která obsahují písmeno „n“:
SELECT StudentName FROM Students WHERE StudentName LIKE '%n%';
Výsledek:

„GLOB“ – je ekvivalentem operátoru LIKE, ale GLOB rozlišuje velká a malá písmena, na rozdíl od operátoru LIKE. Například následující dva příkazy vrátí různé výsledky:
SELECT 'Jack' GLOB 'j%'; SELECT 'Jack' LIKE 'j%';
To vám dá:

První příkaz vrátí 0 (nepravda), protože operátor GLOB rozlišuje velká a malá písmena, takže 'j' se nerovná 'J'. Druhý příkaz však vrátí 1 (pravda), protože operátor LIKE nerozlišuje malá a velká písmena, takže 'j' se rovná 'J'.
Další operátoři:
SQLite A AUTOMATIZACI
Logický operátor, který kombinuje jeden nebo více výrazů. Vrátí hodnotu true, pouze pokud všechny výrazy poskytnou hodnotu „true“. Vrátí však hodnotu false, pouze pokud všechny výrazy poskytnou hodnotu „false“.
Příklad:
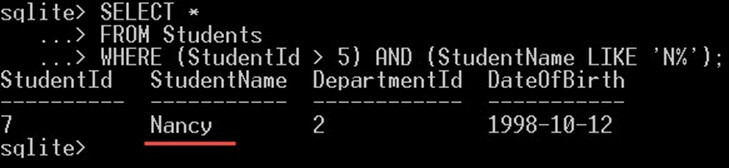
Následující dotaz vyhledá studenty, kteří mají StudentId > 5 a StudentName začíná písmenem N, vrácení studenti musí splňovat dvě podmínky:
SELECT * FROM Students WHERE (StudentId > 5) AND (StudentName LIKE 'N%');
Jako výstup na výše uvedeném snímku obrazovky získáte pouze „Nancy“. Nancy je jedinou studentkou, která splňuje obě podmínky.
SQLite OR
Logický operátor, který kombinuje jeden nebo více výrazů, takže pokud jeden z kombinovaných operátorů dá hodnotu true, vrátí hodnotu true. Pokud však všechny výrazy dávají hodnotu false, vrátí hodnotu false.
Příklad:
Následující dotaz vyhledá studenty, kteří mají StudentId > 5 nebo StudentName začíná písmenem N, vrácení studenti musí splňovat alespoň jednu z podmínek:
SELECT * FROM Students WHERE (StudentId > 5) OR (StudentName LIKE 'N%');
To vám dá:
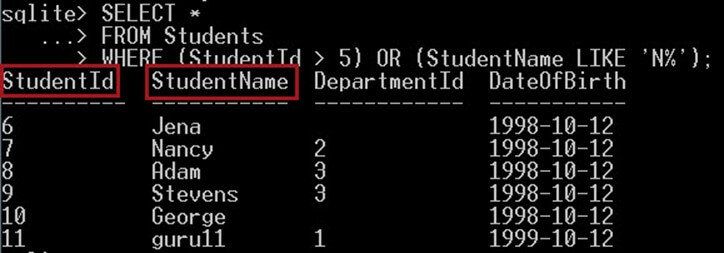
Jako výstup na výše uvedeném snímku obrazovky získáte jméno studenta s písmenem „n“ ve svém jméně plus ID studenta s hodnotou > 5.
Jak vidíte, výsledek je jiný než dotaz s operátorem AND.
SQLite MEZI
Funkce BETWEEN se používá k výběru hodnot, které jsou v rozsahu dvou hodnot. Například „X BETWEEN Y AND Z“ vrátí hodnotu true (1), pokud se hodnota X nachází mezi hodnotami Y a Z. V opačném případě vrátí hodnotu false (0). „X BETWEEN Y AND Z“ je ekvivalentní funkci „X >= Y AND X <= Z“, X musí být větší nebo rovno Y a X je menší nebo rovno Z.
Příklad:
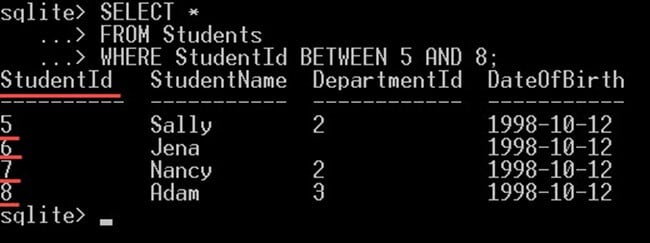
V následujícím příkladu dotazu napíšeme dotaz, abychom získali studenty s hodnotou Id mezi 5 a 8:
SELECT * FROM Students WHERE StudentId BETWEEN 5 AND 8;
To dá pouze studentům s ID 5, 6, 7 a 8:
SQLite IN
Vezme jeden operand a seznam operandů. Vrátí hodnotu true, pokud je hodnota prvního operandu rovna jedné z hodnot operandů ze seznamu. Operátor IN vrátí hodnotu true (1), pokud seznam operandů obsahuje hodnotu prvního operandu v rámci svých hodnot. V opačném případě vrátí hodnotu false (0).
Takto: „col IN(x, y, z)“. To je ekvivalentní k „(col=x) nebo (col=y) nebo (col=z)“.
Příklad:
Následující dotaz vybere pouze studenty s ID 2, 4, 6, 8:
SELECT * FROM Students WHERE StudentId IN(2, 4, 6, 8);
Stejně jako tento:

Předchozí dotaz poskytne přesný výsledek jako následující dotaz, protože jsou ekvivalentní:
SELECT * FROM Students WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);
Oba dotazy poskytují přesný výstup. Rozdíl mezi těmito dvěma dotazy je však ten, že u prvního dotazu jsme použili operátor „IN“. Ve druhém dotazu jsme použili více operátorů „OR“.
Operátor IN je ekvivalentní použití více operátorů OR. Operátor „WHERE StudentId IN(2, 4, 6, 8)“ je ekvivalentní operátoru „WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);“.
Stejně jako tento:

SQLite NE V
Operand „NOT IN“ je opakem operátoru IN. Má však stejnou syntaxi; bere jeden operand a seznam operandů. Vrátí hodnotu true, pokud hodnota prvního operandu není rovna hodnotě jednoho z operandů ze seznamu, tj. vrátí hodnotu true (0), pokud seznam operandů neobsahuje první operand. Například: „col NOT IN(x, y, z)“. Toto je ekvivalentní operaci „(col<>x) AND (col<>y) AND (col<>z)“.
Příklad:
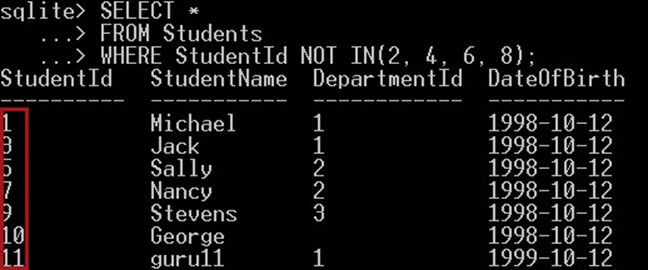
Následující dotaz vybere studenty s ID, která se nerovna jednomu z těchto ID 2, 4, 6, 8:
SELECT * FROM Students WHERE StudentId NOT IN(2, 4, 6, 8);
Takhle
Předchozí dotaz dáváme přesný výsledek jako následující dotaz, protože jsou ekvivalentní:
SELECT * FROM Students WHERE (StudentId <> 2) AND (StudentId <> 4) AND (StudentId <> 6) AND (StudentId <> 8);
Stejně jako tento:
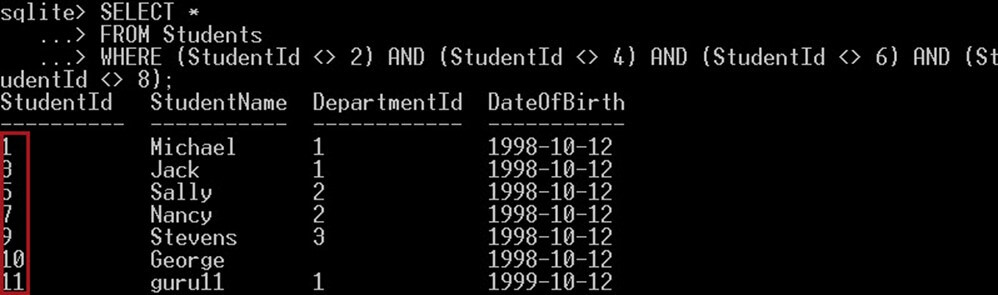
Na výše uvedeném snímku obrazovky
Použili jsme několik různých operátorů „<>“, abychom získali seznam studentů, kteří se nerovnají žádnému z následujících ID 2, 4, 6 ani 8. Tento dotaz vrátí všechny ostatní studenty kromě těchto seznamů ID.
SQLite EXISTUJE
Operátory EXISTS neberou žádné operandy; po něm trvá pouze klauzule SELECT. Operátor EXISTS vrátí hodnotu true (1), pokud jsou vráceny nějaké řádky z klauzule SELECT, a vrátí hodnotu false (0), pokud z klauzule SELECT nejsou vráceny žádné řádky.
Příklad:
V následujícím příkladu vybereme název oddělení, pokud ID oddělení existuje v tabulce studentů:
SELECT DepartmentName FROM Departments AS d WHERE EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
To vám dá:

Vrátí se pouze tři katedry: „IT, Fyzika a Umění“. Název katedry „Matematika“ se nevrátí, protože na této katedře není žádný student, takže ID katedry v tabulce studentů neexistuje. Proto operátor EXISTS katedru „Matematika“ ignoroval.
SQLite NENÍ
Reverseje výsledek předchozího operátoru, který následuje za ním. Například:
- NOT BETWEEN – Vrátí true, pokud BETWEEN vrátí false a naopak.
- NOT LIKE – Vrátí true, pokud LIKE vrátí false a naopak.
- NOT GLOB – Vrátí true, pokud GLOB vrátí false a naopak.
- NOT EXISTS – Vrátí true, pokud EXISTS vrátí false a naopak.
Příklad:
V následujícím příkladu použijeme operátor NOT s operátorem EXISTS k získání názvů kateder, které neexistují v tabulce Studenti, což je opačný výsledek operátoru EXISTS. Hledání tedy bude provedeno pomocí DepartmentId, které v tabulce oddělení neexistuje.
SELECT DepartmentName FROM Departments AS d WHERE NOT EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
Výstup:

Vrátí se pouze oddělení „Matematika“. Protože oddělení „Matematika“ je jediné oddělení, které v tabulce studentů neexistuje.
Omezení a objednání
SQLite Objednávka
SQLite Pořadí znamená seřadit výsledek podle jednoho nebo více výrazů. Chcete-li seřadit sadu výsledků, musíte použít klauzuli ORDER BY takto:
- Nejprve musíte zadat klauzuli ORDER BY.
- Na konci dotazu musí být uvedena klauzule ORDER BY; za ním lze uvést pouze klauzuli LIMIT.
- Zadejte výraz, pomocí kterého se mají data seřadit, tento výraz může být název sloupce nebo výraz.
- Za výrazem můžete zadat volitelný směr řazení. Buď DESC, chcete-li data seřadit sestupně, nebo ASC, abyste data seřadili vzestupně. Pokud byste žádný z nich nezadali, data by seřadila vzestupně.
- Můžete zadat více výrazů pomocí „,“ mezi sebou.
Příklad
V následujícím příkladu vybereme všechny studenty seřazené podle jejich jmen, ale v sestupném pořadí, a poté podle názvu katedry ve vzestupném pořadí:
SELECT s.StudentName, d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId ORDER BY d.DepartmentName ASC , s.StudentName DESC;
To vám dá:
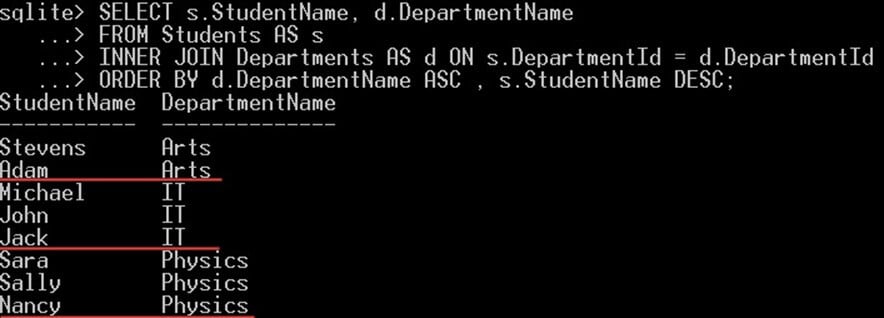
- SQLite nejprve seřadí všechny studenty podle názvu katedry ve vzestupném pořadí
- Poté se pro každý název oddělení zobrazí všichni studenti pod tímto názvem oddělení v sestupném pořadí podle jejich jmen
SQLite Omezit:
Pomocí klauzule LIMIT můžete omezit počet řádků vrácených vaším dotazem SQL. Například LIMIT 10 vám poskytne pouze 10 řádků a všechny ostatní řádky ignoruje.
V klauzuli LIMIT můžete pomocí klauzule OFFSET vybrat určitý počet řádků počínaje od určité pozice. Například „LIMIT 4 OFFSET 4“ bude ignorovat první 4 řádky a vrátí 4 řádky počínaje pátým řádkem, takže získáte řádky 5, 6, 7 a 8.
Klauzule OFFSET je volitelná, můžete ji napsat například jako „LIMIT 4, 4“ a dostanete přesné výsledky.
Příklad:
V následujícím příkladu vrátíme pomocí dotazu pouze 3 studenty počínaje studentským ID 5:
SELECT * FROM Students LIMIT 4,3;
Tím získáte pouze tři studenty od řádku 5. Získáte tedy řádky se StudentId 5, 6 a 7:

Odstraňování duplikátů
Pokud váš SQL dotaz vrací duplicitní hodnoty, můžete použít klíčové slovo „DISTINCT“ k odstranění těchto duplicit a vrácení odlišných hodnot. Po použití klíče DISTINCT můžete zadat více než jeden sloupec.
Příklad:
Následující dotaz vrátí duplicitní „hodnoty názvu oddělení“: Zde máme duplicitní hodnoty s názvy IT, Physics a Arts.
SELECT d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
Tím získáte duplicitní hodnoty pro název oddělení:
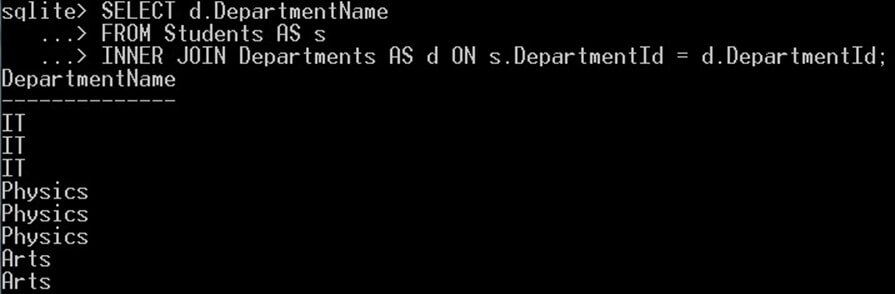
Všimněte si, že existují duplicitní hodnoty pro název oddělení. Nyní použijeme klíčové slovo DISTINCT se stejným dotazem k odstranění těchto duplikátů a získání pouze jedinečných hodnot. Takhle:
SELECT DISTINCT d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
Tím získáte pouze tři jedinečné hodnoty pro sloupec názvu oddělení:
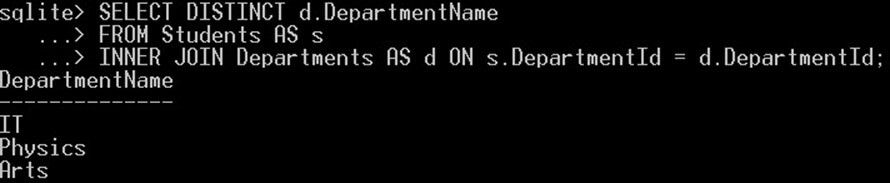
Agregát
SQLite Agregáty jsou vestavěné funkce definované v SQLite který seskupí více hodnot z více řádků do jedné hodnoty.
Zde jsou podporované agregáty SQLite:
SQLite AVG()
Vrátí průměr pro všechny hodnoty x.
Příklad:
V následujícím příkladu získáme průměrnou známku, kterou studenti získají ze všech zkoušek:
SELECT AVG(Mark) FROM Marks;
To vám dá hodnotu „18.375“:

Tyto výsledky pocházejí ze součtu všech hodnot známek děleno jejich počtem.
COUNT() – COUNT(X) nebo COUNT(*)
Vrátí celkový počet, kolikrát se objevila hodnota x. A zde jsou některé možnosti, které můžete použít s COUNT:
- COUNT(x): Počítá pouze x hodnot, kde x je název sloupce. Bude ignorovat hodnoty NULL.
- COUNT(*): Spočítá všechny řádky ze všech sloupců.
- COUNT (DISTINCT x): Před x můžete zadat klíčové slovo DISTINCT, které získá počet různých hodnot x.
Příklad
V následujícím příkladu získáme celkový počet oddělení s COUNT(DepartmentId), COUNT(*) a COUNT(DISTINCT DepartmentId) a jak se liší:
SELECT COUNT(DepartmentId), COUNT(DISTINCT DepartmentId), COUNT(*) FROM Students;
To vám dá:

Takto:
- COUNT(DepartmentId) vám poskytne počet všech ID oddělení a bude ignorovat hodnoty null.
- COUNT(DISTINCT DepartmentId) vám dává odlišné hodnoty DepartmentId, které jsou pouze 3. Což jsou tři různé hodnoty názvu oddělení. Všimněte si, že ve jménu studenta je 8 hodnot názvu oddělení. Ale pouze tři různé hodnoty, kterými jsou matematika, IT a fyzika.
- COUNT(*) počítá počet řádků v tabulce studentů, což je 10 řádků pro 10 studentů.
GROUP_CONCAT() – GROUP_CONCAT(X) nebo GROUP_CONCAT(X,Y)
Agregační funkce GROUP_CONCAT zřetězí násobky hodnot do jedné hodnoty a oddělí je čárkou. Má následující možnosti:
- GROUP_CONCAT(X): Toto zřetězí všechny hodnoty x do jednoho řetězce s čárkou „,“ používanou jako oddělovač mezi hodnotami. Hodnoty NULL budou ignorovány.
- GROUP_CONCAT(X, Y): Toto zřetězí hodnoty x do jednoho řetězce, přičemž hodnota y se použije jako oddělovač mezi každou hodnotou namísto výchozího oddělovače ','. Hodnoty NULL budou také ignorovány.
- GROUP_CONCAT(DISTINCT X): Toto zřetězí všechny odlišné hodnoty x do jednoho řetězce s čárkou „,“ používanou jako oddělovač mezi hodnotami. Hodnoty NULL budou ignorovány.
GROUP_CONCAT(název oddělení) Příklad
Následující dotaz zřetězí všechny hodnoty názvu oddělení z tabulky studentů a oddělení do jednoho řetězce odděleného čárkou. Takže místo vracení seznamu hodnot jedna hodnota na každém řádku. Vrátí pouze jednu hodnotu na jednom řádku se všemi hodnotami oddělenými čárkou:
SELECT GROUP_CONCAT(d.DepartmentName) FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
To vám dá:

Získáte tak seznam hodnot názvů 8 oddělení spojených do jednoho řetězce odděleného čárkou.
GROUP_CONCAT(DISTINCT název oddělení) Příklad
Následující dotaz zřetězí odlišné hodnoty názvu oddělení z tabulky studentů a oddělení do jednoho řetězce odděleného čárkou:
SELECT GROUP_CONCAT(DISTINCT d.DepartmentName) FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
To vám dá:

Všimněte si, jak se výsledek liší od předchozího výsledku; vrátily se pouze tři hodnoty, což jsou odlišná jména oddělení, a duplicitní hodnoty byly odstraněny.
GROUP_CONCAT(Název oddělení ,'&') Příklad
Následující dotaz zřetězí všechny hodnoty sloupce názvu oddělení z tabulky studentů a oddělení do jednoho řetězce, ale se znakem '&' namísto čárky jako oddělovače:
SELECT GROUP_CONCAT(d.DepartmentName, '&') FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
To vám dá:

Všimněte si, jak je k oddělení hodnot použit znak „&“ místo výchozího znaku „,“.
SQLite MAX() & MIN()
MAX(X) vám vrátí nejvyšší hodnotu z hodnot X. MAX vrátí hodnotu NULL, pokud jsou všechny hodnoty x nulové. Zatímco MIN(X) vám vrátí nejmenší hodnotu z hodnot X. MIN vrátí hodnotu NULL, pokud jsou všechny hodnoty X nulové.
Příklad
V následujícím dotazu použijeme funkce MIN a MAX k získání nejvyšší a nejnižší známky z tabulky „Známky“:
SELECT MAX(Mark), MIN(Mark) FROM Marks;
To vám dá:

SQLite SUM(x), Celkem (x)
Oba vrátí součet všech hodnot x. Liší se ale v následujícím:
- Pokud jsou všechny hodnoty null, SUM vrátí null, ale Total vrátí 0.
- TOTAL vždy vrací hodnoty s plovoucí desetinnou čárkou. SUM vrátí celočíselnou hodnotu, pokud jsou všechny hodnoty x celé číslo. Pokud však hodnoty nejsou celé číslo, vrátí hodnotu s plovoucí desetinnou čárkou.
Příklad
V následujícím dotazu použijeme funkce SUM a total k získání součtu všech známek v tabulkách „Známky“:
SELECT SUM(Mark), TOTAL(Mark) FROM Marks;
To vám dá:

Jak vidíte, TOTAL vždy vrací plovoucí desetinnou čárku. Ale SUM vrátí celočíselnou hodnotu, protože hodnoty ve sloupci „Mark“ mohou být v celých číslech.
Rozdíl mezi příkladem SUM a TOTAL:
V následujícím dotazu ukážeme rozdíl mezi SUM a TOTAL, když získají SUM hodnot NULL:
SELECT SUM(Mark), TOTAL(Mark) FROM Marks WHERE TestId = 4;
To vám dá:

Všimněte si, že pro TestId = 4 nejsou žádné značky, takže pro tento test existují hodnoty null. SUM vrátí nulovou hodnotu jako prázdnou, zatímco TOTAL vrátí 0.
Skupina vytvořená
Klauzule GROUP BY se používá k určení jednoho nebo více sloupců, které budou použity k seskupení řádků do skupin. Řádky se stejnými hodnotami budou shromážděny (uspořádány) do skupin.
Pro jakýkoli jiný sloupec, který není zahrnut ve skupině podle sloupců, můžete použít agregační funkci.
Příklad:
Následující dotaz vám poskytne celkový počet studentů přítomných v jednotlivých odděleních.
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId GROUP BY d. DepartmentName;
To vám dá:
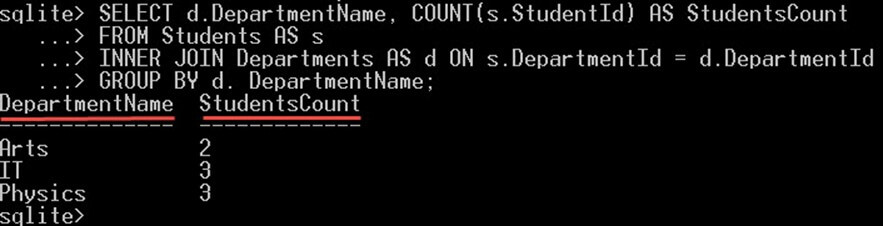
Klauzule GROUPBY DepartmentName seskupí všechny studenty do skupin po jedné pro každý název oddělení. Pro každou skupinu „oddělení“ bude počítat studenty na ní.
klauzule HAVING
Pokud chcete filtrovat skupiny vrácené klauzulí GROUP BY, můžete zadat klauzuli „HAVING“ s výrazem za klauzuli GROUP BY. Výraz bude použit k filtrování těchto skupin.
Příklad
V následujícím dotazu vybereme ty katedry, na kterých jsou pouze dva studenti:
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId GROUP BY d. DepartmentName HAVING COUNT(s.StudentId) = 2;
To vám dá:
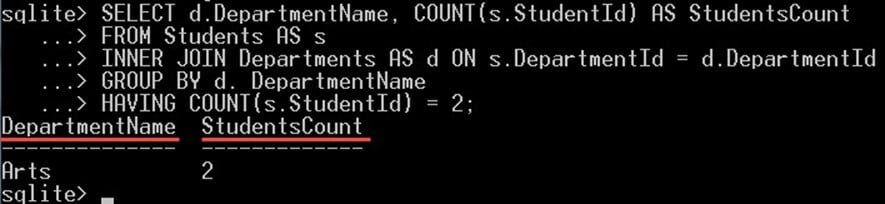
Klauzule HAVING COUNT(S.StudentId) = 2 vyfiltruje vrácené skupiny a vrátí pouze ty skupiny, které obsahují právě dva studenty. V našem případě má katedra umění 2 studenty, takže je zobrazena ve výstupu.
SQLite Dotaz a poddotaz
Uvnitř jakéhokoli dotazu můžete použít jiný dotaz buď v SELECT, INSERT, DELETE, UPDATE nebo uvnitř jiného poddotazu.
Tento vnořený dotaz se nazývá poddotaz. Nyní uvidíme několik příkladů použití poddotazů v klauzuli SELECT. V tutoriálu Modifying Data však uvidíme, jak můžeme použít poddotazy s příkazy INSERT, DELETE a UPDATE.
Použití poddotazu v příkladu klauzule FROM
V následujícím dotazu zahrneme poddotaz do klauzule FROM:
SELECT s.StudentName, t.Mark FROM Students AS s INNER JOIN ( SELECT StudentId, Mark FROM Tests AS t INNER JOIN Marks AS m ON t.TestId = m.TestId ) ON s.StudentId = t.StudentId;
dotaz:
SELECT StudentId, Mark FROM Tests AS t INNER JOIN Marks AS m ON t.TestId = m.TestId
Výše uvedený dotaz se zde nazývá poddotaz, protože je vnořen do klauzule FROM. Všimněte si, že jsme mu dali alias „t“, abychom mohli odkazovat na sloupce vrácené z něj v dotazu.
Tento dotaz vám poskytne:
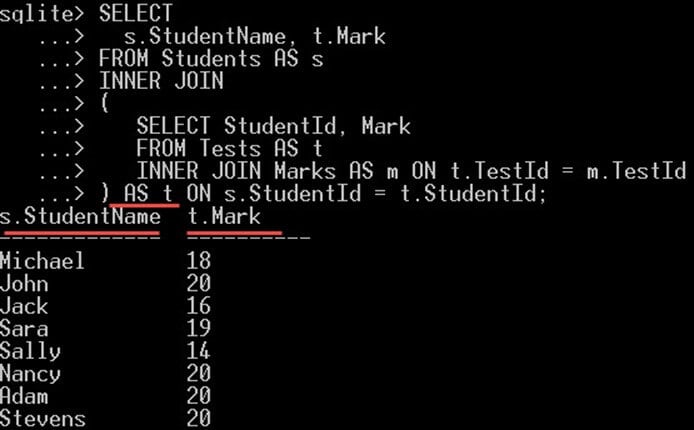
Takže v našem případě,
- s.StudentName je vybráno z hlavního dotazu, který udává jména studentů a
- t.Mark je vybrán z dílčího dotazu; to dává známky získané každým z těchto studentů
Použití poddotazu v příkladu klauzule WHERE
V následujícím dotazu zahrneme poddotaz do klauzule WHERE:
SELECT DepartmentName FROM Departments AS d WHERE NOT EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
dotaz:
SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId
Výše uvedený dotaz se zde nazývá poddotaz, protože je vnořen do klauzule WHERE. Poddotaz vrátí hodnoty DepartmentId, které použije operátor NOT EXISTS.
Tento dotaz vám poskytne:
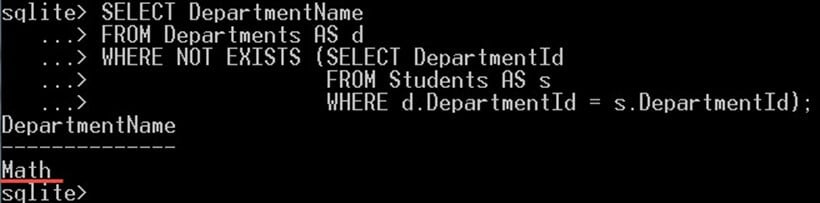
Ve výše uvedeném dotazu jsme vybrali katedru, na které není zapsán žádný student. Což je tady "matematické" oddělení.
sada Operations – UNION,Intersect
SQLite podporuje následující operace SET:
UNION & UNION VŠECHNY
Kombinuje jednu nebo více sad výsledků (skupina řádků) vrácených z více příkazů SELECT do jedné sady výsledků.
UNION vrátí odlišné hodnoty. UNION ALL však nebude a bude obsahovat duplikáty.
Všimněte si, že název sloupce bude název sloupce zadaný v prvním příkazu SELECT.
Příklad UNION
V následujícím příkladu získáme seznam DepartmentId z tabulky studentů a seznam DepartmentId z tabulky departments ve stejném sloupci:
SELECT DepartmentId AS DepartmentIdUnioned FROM Students UNION SELECT DepartmentId FROM Departments;
To vám dá:
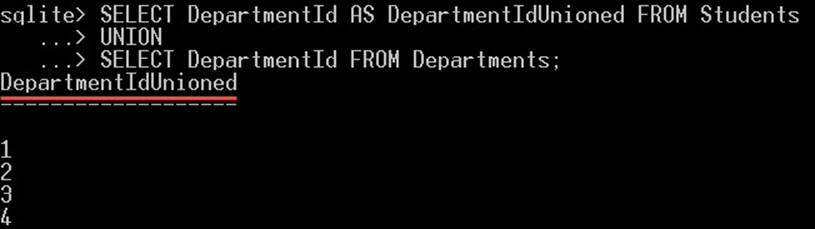
Dotaz vrátí pouze 5 řádků, což jsou odlišné hodnoty ID oddělení. Všimněte si první hodnoty, která je nulovou hodnotou.
SQLite UNION ALL Příklad
V následujícím příkladu získáme seznam DepartmentId z tabulky studentů a seznam DepartmentId z tabulky departments ve stejném sloupci:
SELECT DepartmentId AS DepartmentIdUnioned FROM Students UNION ALL SELECT DepartmentId FROM Departments;
To vám dá:
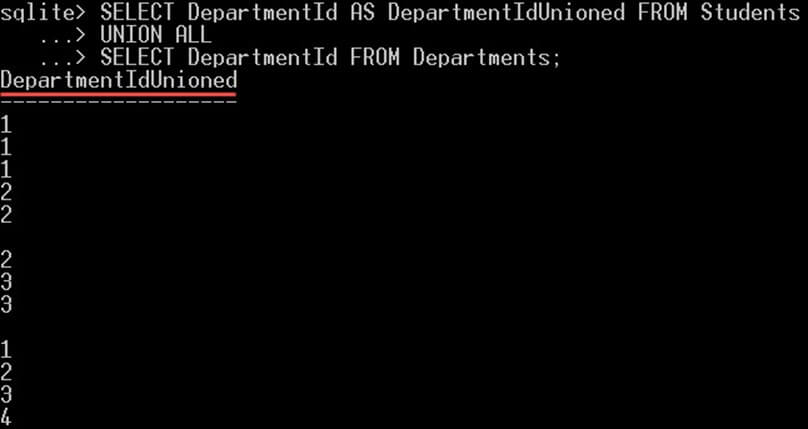
Dotaz vrátí 14 řádků, 10 řádků z tabulky studentů a 4 z tabulky oddělení. Všimněte si, že vrácené hodnoty jsou duplikáty. Všimněte si také, že název sloupce byl ten, který byl zadán v prvním příkazu SELECT.
Nyní se podívejme, jak UNION all poskytne různé výsledky, pokud nahradíme UNION ALL za UNION:
SQLite PROSÍT
Vrátí hodnoty, které existují v obou kombinovaných sadě výsledků. Hodnoty, které existují v jedné z kombinované sady výsledků, budou ignorovány.
Příklad
V následujícím dotazu vybereme hodnoty DepartmentId, které existují v tabulkách Students a Departments ve sloupci DepartmentId:
SELECT DepartmentId FROM Students Intersect SELECT DepartmentId FROM Departments;
To vám dá:
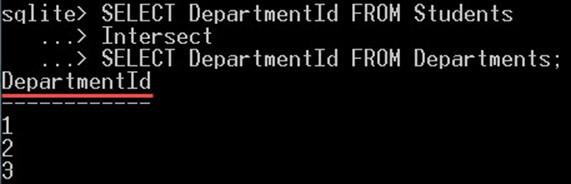
Dotaz vrací pouze tři hodnoty 1, 2 a 3. Což jsou hodnoty, které existují v obou tabulkách.
Hodnoty null a 4 však nebyly zahrnuty, protože hodnota null existuje pouze v tabulce studentů a nikoli v tabulce oddělení. A hodnota 4 existuje v tabulce oddělení a ne v tabulce studentů.
To je důvod, proč byly hodnoty NULL i 4 ignorovány a nebyly zahrnuty do vrácených hodnot.
AŽ NA
Předpokládejme, že pokud máte dva seznamy řádků, seznam1 a seznam2, a chcete řádky pouze ze seznamu1, který v seznamu2 neexistuje, můžete použít klauzuli „EXCEPT“. Klauzule EXCEPT porovná dva seznamy a vrátí ty řádky, které existují v seznamu1 a neexistují v seznamu2.
Příklad
V následujícím dotazu vybereme hodnoty DepartmentId, které existují v tabulce oddělení a neexistují v tabulce studentů:
SELECT DepartmentId FROM Departments EXCEPT SELECT DepartmentId FROM Students;
To vám dá:

Dotaz vrátí pouze hodnotu 4. Což je jediná hodnota, která existuje v tabulce oddělení a neexistuje v tabulce studentů.
Zpracování NULL
Hodnota „NULL“ je speciální hodnota v SQLitePoužívá se k reprezentaci neznámé nebo chybějící hodnoty. Všimněte si, že hodnota null je zcela odlišná od hodnoty „0“ nebo prázdné hodnoty „“. Protože 0 a prázdná hodnota jsou známé hodnoty, je hodnota null neznámá.
Hodnoty NULL vyžadují speciální zpracování SQLite, nyní uvidíme, jak zacházet s hodnotami NULL.
Hledejte hodnoty NULL
K vyhledání hodnot null nemůžete použít normální operátor rovnosti (=). Například následující dotaz hledá studenty, kteří mají nulovou hodnotu DepartmentId:
SELECT * FROM Students WHERE DepartmentId = NULL;
Tento dotaz nepřinese žádný výsledek:
![]()
Protože hodnota NULL se nerovná žádné jiné hodnotě včetně samotné hodnoty null, proto nevrátila žádný výsledek.
Aby však dotaz fungoval, musíte k vyhledávání hodnot NULL použít operátor „IS NULL“ takto:
SELECT * FROM Students WHERE DepartmentId IS NULL;
To vám dá:

Dotaz vrátí ty studenty, kteří mají nulovou hodnotu DepartmentId.
Pokud chcete získat hodnoty, které nejsou null, musíte použít operátor „IS NOT NULL“ takto:
SELECT * FROM Students WHERE DepartmentId IS NOT NULL;
To vám dá:
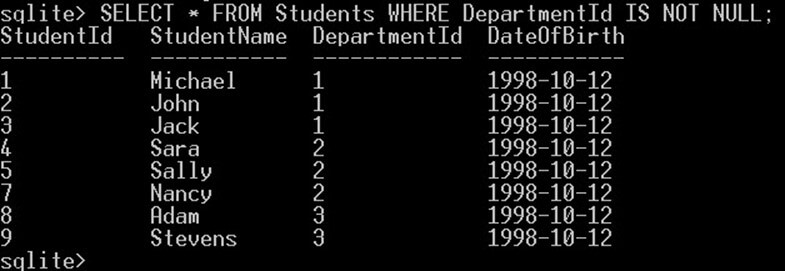
Dotaz vrátí ty studenty, kteří nemají hodnotu NULL DepartmentId.
Podmíněné výsledky
Pokud máte seznam hodnot a chcete vybrat kteroukoli z nich na základě určitých podmínek. Za tímto účelem by podmínka pro tuto konkrétní hodnotu měla být pravdivá, aby mohla být vybrána.
Výraz CASE vyhodnotí tento seznam podmínek pro všechny hodnoty. Pokud je podmínka pravdivá, vrátí tuto hodnotu.
Máte-li například sloupec Známka a chcete vybrat textovou hodnotu na základě hodnoty stupně takto:
– „Výborně“, pokud je známka vyšší než 85.
– „Velmi dobře“, pokud je známka mezi 70 a 85.
– „Dobrý“, pokud je známka mezi 60 a 70.
Pak k tomu můžete použít výraz CASE.
To lze použít k definování určité logiky v klauzuli SELECT, abyste mohli vybrat určité výsledky v závislosti na určitých podmínkách, jako je například příkaz if.
Operátor CASE lze definovat s různými syntaxemi takto:
Můžete použít různé podmínky:
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 WHEN condition3 THEN result3 … ELSE resultn END
Nebo můžete použít pouze jeden výraz a vložit různé možné hodnoty na výběr:
CASE expression WHEN value1 THEN result1 WHEN value2 THEN result2 WHEN value3 THEN result3 … ELSE restuln END
Všimněte si, že klauzule ELSE je volitelná.
Příklad
V následujícím příkladu použijeme výraz CASE s hodnotou NULL ve sloupci ID oddělení v tabulce Studenti k zobrazení textu „Žádné oddělení“ takto:
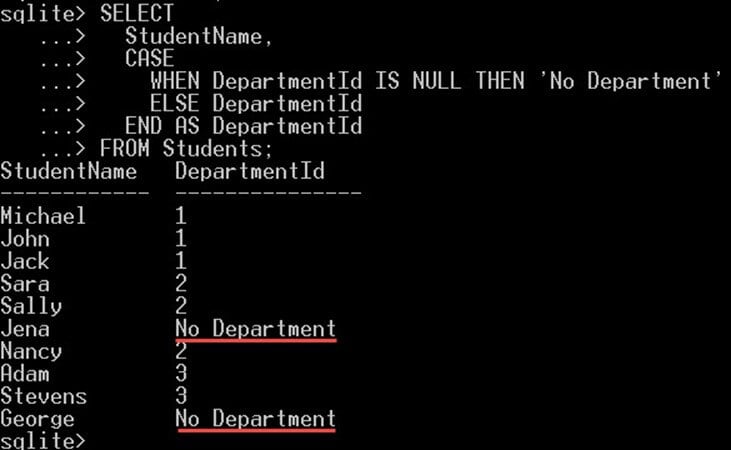
SELECT StudentName, CASE WHEN DepartmentId IS NULL THEN 'No Department' ELSE DepartmentId END AS DepartmentId FROM Students;
- Operátor CASE zkontroluje hodnotu DepartmentId, zda je nulová nebo ne.
- Pokud se jedná o hodnotu NULL, vybere doslovnou hodnotu 'No Department' namísto hodnoty DepartmentId.
- Pokud hodnota není nulová, vybere se hodnota sloupce DepartmentId.
Tím získáte výstup, jak je znázorněno níže:
Běžný tabulkový výraz
Běžné tabulkové výrazy (CTE) jsou poddotazy, které jsou definovány uvnitř příkazu SQL s daným názvem.
Oproti poddotazům má výhodu, protože je definována z příkazů SQL a usnadňuje čtení, údržbu a pochopení dotazů.
Společný tabulkový výraz lze definovat umístěním klauzule WITH před příkazy SELECT takto:
WITH CTEname AS ( SELECT statement ) SELECT, UPDATE, INSERT, or update statement here FROM CTE
„Název CTE“ je libovolný název, který můžete CTE přiřadit a který můžete použít k pozdějšímu odkazování. Upozorňujeme, že pro CTE můžete definovat příkazy SELECT, UPDATE, INSERT nebo DELETE.
Nyní se podívejme na příklad, jak použít CTE v klauzuli SELECT.
Příklad
V následujícím příkladu definujeme CTE z příkazu SELECT a později jej použijeme v jiném dotazu:
WITH AllDepartments AS ( SELECT DepartmentId, DepartmentName FROM Departments ) SELECT s.StudentId, s.StudentName, a.DepartmentName FROM Students AS s INNER JOIN AllDepartments AS a ON s.DepartmentId = a.DepartmentId;
V tomto dotazu jsme definovali CTE a pojmenovali ho „Všechna oddělení“. Toto CTE bylo definováno z dotazu SELECT:
SELECT DepartmentId, DepartmentName FROM Departments
Poté, co jsme definovali CTE, jsme jej použili v dotazu SELECT, který následuje po něm.
Všimněte si, že běžné tabulkové výrazy neovlivňují výstup dotazu. Je to způsob, jak definovat logický pohled nebo poddotaz, aby bylo možné je znovu použít ve stejném dotazu. Běžné tabulkové výrazy jsou jako proměnná, kterou deklarujete a znovu ji použijete jako poddotaz. Pouze příkaz SELECT ovlivňuje výstup dotazu.
Tento dotaz vám poskytne:

Pokročilé dotazy
Pokročilé dotazy jsou ty dotazy, které obsahují komplexní spojení, poddotazy a některé agregáty. V následující části uvidíme příklad pokročilého dotazu:
Kde získáme,
- Jména oddělení se všemi studenty pro každé oddělení
- Jméno studentů oddělené čárkou a
- Ukazuje, že oddělení má alespoň tři studenty
SELECT d.DepartmentName, COUNT(s.StudentId) StudentsCount, GROUP_CONCAT(StudentName) AS Students FROM Departments AS d INNER JOIN Students AS s ON s.DepartmentId = d.DepartmentId GROUP BY d.DepartmentName HAVING COUNT(s.StudentId) >= 3;
Přidali jsme klauzuli JOIN pro získání názvu oddělení (DepartmentName) z tabulky Departments. Poté jsme přidali klauzuli GROUP BY se dvěma agregačními funkcemi:
- „POČET“ pro sčítání studentů pro každou skupinu oddělení.
- GROUP_CONCAT pro zřetězení studentů pro každou skupinu s čárkami oddělenými v jednom řetězci.
Po GROUP BY jsme pomocí klauzule HAVING filtrovali katedry a vybrali pouze ta katedry, která mají alespoň 3 studenty.
Výsledek bude následující:
