50 otázek a odpovědí na pohovor SQL pro rok 2026
Otázky k pohovoru SQL pro začátečníky
1. Co je DBMS?
Systém správy databází (DBMS) je program, který řídí vytváření, údržbu a používání databáze. DBMS lze nazvat jako Správce souborů, který spravuje data v databázi spíše než je ukládá do souborových systémů.
👉 Zdarma ke stažení PDF: SQL Interview Otázky a odpovědi >>
2. Co je RDBMS?
RDBMS je zkratka pro Relational Database Management System. RDBMS ukládá data do kolekce tabulek, která je propojena společnými poli mezi sloupci tabulky. Poskytuje také relační operátory pro manipulaci s daty uloženými v tabulkách.
Příklad: SQL Server.
3. Co je SQL?
SQL je zkratka pro Structured Query Language a používá se ke komunikaci s databází. Jedná se o standardní jazyk používaný k provádění úloh, jako je získávání, aktualizace, vkládání a mazání dat z databáze.
Standard Příkazy SQL jsou Vybrat.
4. Co je databáze?
Databáze není nic jiného než organizovaná forma dat pro snadný přístup, ukládání, vyhledávání a správu dat. Toto je také známé jako strukturovaná forma dat, ke kterým lze přistupovat mnoha způsoby.
Příklad: Databáze vedení školy, Databáze vedení banky.
5. Co jsou tabulky a pole?
Tabulka je sada dat, která jsou uspořádána v modelu se sloupci a řádky. Sloupce lze kategorizovat jako svislé a řádky jsou vodorovné. Tabulka má zadaný počet sloupců nazývaných pole, ale může mít libovolný počet řádků, které se nazývají záznam.
Příklad:.
Tabulka: Zaměstnanec.
Pole: ID zaměstnance, jméno zaměstnance, datum narození.
Údaje: 201456, David, 11.
6. Co je primární klíč?
A primární klíč je kombinace polí, která jednoznačně určují řádek. Toto je speciální druh jedinečného klíče a má implicitní omezení NOT NULL. To znamená, že hodnoty primárního klíče nemohou být NULL.
7. Co je jedinečný klíč?
Omezení jedinečného klíče jednoznačně identifikuje každý záznam v databázi. To zajišťuje jedinečnost sloupce nebo sady sloupců.
Omezení primárního klíče má definované automatické jedinečné omezení. Ale ne v případě Unique Key.
Pro každou tabulku může být definováno mnoho jedinečných omezení, ale pro každou tabulku je definováno pouze jedno omezení primárního klíče.
8. Co je cizí klíč?
Cizí klíč je jedna tabulka, která může souviset s primárním klíčem jiné tabulky. Mezi dvěma tabulkami je třeba vytvořit vztah odkazem na cizí klíč s primárním klíčem jiné tabulky.
9. Co je to spojení?
Toto je klíčové slovo používané k dotazování na data z více tabulek na základě vztahu mezi poli tabulek. Klíče hrají hlavní roli při použití JOINů.
10. Jaké jsou typy spojení a vysvětlení každého z nich?
Existují různé druhy spojů které lze použít k načtení dat a záleží na vztahu mezi tabulkami.
- Vnitřní spojení.
Vnitřní spojení vrátí řádky, když mezi tabulkami existuje alespoň jedna shoda řádků.
- Správně Připojte se.
Pravé spojení vrátí řádky, které jsou společné pro tabulky a všechny řádky tabulky na pravé straně. Jednoduše vrátí všechny řádky z pravé tabulky, i když v levé tabulce nejsou žádné shody.
- Připojit se vlevo.
Levé spojení vrátí řádky, které jsou společné mezi tabulkami a všemi řádky tabulky na levé straně. Jednoduše vrátí všechny řádky z levého stolu, i když v pravém stole nejsou žádné shody.
- Úplné připojení.
Úplné spojení vrátí řádky, pokud v kterékoli z tabulek existují odpovídající řádky. To znamená, že vrátí všechny řádky z levé tabulky a všechny řádky z pravé tabulky.
Otázky k pohovoru SQL pro 3 roky zkušeností
11. Co je normalizace?
Normalizace je proces minimalizace redundance a závislosti uspořádáním polí a tabulek databáze. Hlavním cílem normalizace je přidat, odstranit nebo upravit pole, která lze vytvořit v jedné tabulce.
12. Co je denormalizace?
DeNormalization je technika používaná pro přístup k datům z vyšších do nižších normálních forem databáze. Je to také proces zavedení redundance do tabulky začleněním dat ze souvisejících tabulek.
13. Jaké jsou všechny různé normalizace?
Normalizace databáze lze snadno pochopit pomocí případové studie. Normální formy lze rozdělit do 6 forem a jsou vysvětleny níže -.
.png)
- První normální forma (1NF):.
To by mělo z tabulky odstranit všechny duplicitní sloupce. Tvorba tabulek pro související data a identifikace jedinečných sloupců.
- Druhá normální forma (2NF):.
Splnění všech požadavků první normální formy. Umístění podmnožin dat do samostatných tabulek a vytvoření vztahů mezi tabulkami pomocí primárních klíčů.
- Třetí normální forma (3NF):.
To by mělo splňovat všechny požadavky 2NF. Odstranění sloupců, které nejsou závislé na omezeních primárního klíče.
- Čtvrtá normální forma (4NF):.
Pokud žádná instance databázové tabulky neobsahuje dvě nebo více nezávislých a vícehodnotových dat popisujících příslušnou entitu, pak je ve 4th Normální forma.
- Pátá normální forma (5NF):.
Tabulka je v 5. normální formě pouze v případě, že je ve 4NF a nelze ji rozložit na libovolný počet menších tabulek bez ztráty dat.
- Šestá normální forma (6NF):.
6. normální forma není standardizována, nicméně je již nějakou dobu diskutována odborníky na databáze. Doufejme, že v blízké budoucnosti budeme mít jasnou a standardizovanou definici pro 6. normální formu…
14. Co je pohled?
Pohled je virtuální tabulka, která se skládá z podmnožiny dat obsažených v tabulce. Pohledy nejsou prakticky přítomné a jejich uložení zabere méně místa. Pohled může obsahovat data jedné nebo více tabulek a to v závislosti na vztahu.
15. Co je index?
Index je metoda ladění výkonu umožňující rychlejší načítání záznamů z tabulky. Index vytvoří položku pro každou hodnotu a bude rychlejší načíst data.
16. Jaké jsou všechny různé typy indexů?
Existují tři typy indexů -.
- Unikátní index.
Toto indexování neumožňuje, aby pole mělo duplicitní hodnoty, pokud je sloupec jedinečný indexován. Jedinečný index lze použít automaticky, když je definován primární klíč.
- Clustered Index.
Tento typ indexu mění pořadí fyzického pořadí tabulky a vyhledávání na základě hodnot klíče. Každá tabulka může mít pouze jeden seskupený index.
- NeClustered Index.
NeClustered Index nemění fyzické pořadí tabulky a zachovává logické pořadí dat. Každá tabulka může mít 999 neklastrovaných indexů.
17. Co je to kurzor?
Databázový kurzor je ovládací prvek, který umožňuje procházení řádků nebo záznamů v tabulce. To lze zobrazit jako ukazatel na jeden řádek v sadě řádků. Kurzor je velmi užitečný pro procházení, jako je načítání, přidávání a odstraňování záznamů databáze.
18. Co je to vztah a jaké jsou?
Databázový vztah je definován jako spojení mezi tabulkami v databázi. Existují různé datové vztahy a jsou následující:.
- Vztah jeden k jednomu.
- Vztah Jeden k mnoha.
- Vztah mnoho k jednomu.
- Sebeodkazovací vztah.
19. Co je to dotaz?
DB dotaz je kód napsaný za účelem získání informací zpět z databáze. Dotaz může být navržen tak, aby odpovídal našemu očekávání výsledné sady. Prostě otázka do Databáze.
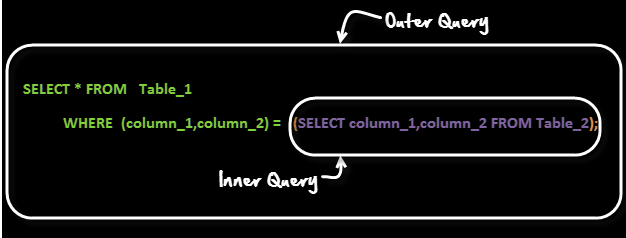
20. Co je poddotaz?
Poddotaz je dotaz v rámci jiného dotazu. Vnější dotaz se nazývá hlavní dotaz a vnitřní dotaz se nazývá poddotaz. Poddotaz se vždy provede jako první a výsledek poddotazu se předá hlavnímu dotazu.
Podívejme se na syntaxi dílčího dotazu –
Častou stížností zákazníků ve Videotéce MyFlix je nízký počet filmových titulů. Vedení chce nakupovat filmy pro kategorii, která má nejmenší počet titulů.
Můžete použít dotaz jako
SELECT category_name FROM categories WHERE category_id =( SELECT MIN(category_id) from movies);
Otázky k pohovoru SQL pro 5 roky zkušeností
21. Jaké jsou typy poddotazů?
Existují dva typy poddotazů – korelovaný a nekorelovaný.
Korelovaný poddotaz nelze považovat za nezávislý dotaz, ale může odkazovat na sloupec v tabulce uvedené v seznamu FROM hlavního dotazu.
Nekorelovaný dílčí dotaz lze považovat za nezávislý dotaz a výstup dílčího dotazu je nahrazen hlavním dotazem.
22. Co je to uložená procedura?
Uložená procedura je funkce sestávající z mnoha příkazů SQL pro přístup k databázovému systému. Několik příkazů SQL je sloučeno do uložené procedury a spouští je kdykoli a kdekoli je to potřeba.
23. Co je to spouštěč?
Spouštěč DB je kód nebo programy, které se automaticky spouštějí v reakci na nějakou událost v tabulce nebo pohledu v databázi. Spouštěč především pomáhá udržovat integritu databáze.
Příklad: Když je do databáze studentů přidán nový student, měly by být vytvořeny nové záznamy v souvisejících tabulkách, jako jsou tabulky zkoušek, skóre a docházky.
24. Jaký je rozdíl mezi příkazy DELETE a TRUNCATE?
Příkaz DELETE se používá k odstranění řádků z tabulky a klauzuli WHERE lze použít pro podmíněnou sadu parametrů. Po příkazu delete lze provést potvrzení a vrácení.
TRUNCATE odstraní všechny řádky z tabulky. Operaci zkrácení nelze vrátit zpět.
25. Jaké jsou lokální a globální proměnné a jejich rozdíly?
Lokální proměnné jsou proměnné, které mohou být použity nebo existují uvnitř funkce. Ostatní funkce je neznají a nelze na ně odkazovat ani je používat. Proměnné lze vytvořit při každém volání této funkce.
Globální proměnné jsou proměnné, které mohou být použity nebo existují v celém programu. Stejnou proměnnou deklarovanou v global nelze použít ve funkcích. Globální proměnné nelze vytvořit při každém volání této funkce.
26. Co je to omezení?
Omezení lze použít k určení limitu datového typu tabulky. Omezení lze zadat při vytváření nebo změně příkazu tabulky. Příklady omezení jsou.
- NENULOVÝ.
- ŠEK.
- VÝCHOZÍ.
- UNIKÁTNÍ.
- PRIMÁRNÍ KLÍČ.
- CIZÍ KLÍČ.
27. Co jsou data Integrity?
Data Integrity definuje přesnost a konzistenci dat uložených v databázi. Může také definovat omezení integrity pro vynucení obchodních pravidel pro data, když jsou zadána do aplikace nebo databáze.
28. Co je automatický přírůstek?
Klíčové slovo Auto increment umožňuje uživateli vytvořit jedinečné číslo, které se vygeneruje při vložení nového záznamu do tabulky. Klíčové slovo AUTO INCREMENT lze použít v Oracle a klíčové slovo IDENTITY lze použít v SQL SERVER.
Většinou lze toto klíčové slovo použít při každém použití PRIMARY KEY.
29. Jaký je rozdíl mezi Cluster a neCluster Index?
Clustered index se používá pro snadné získávání dat z databáze změnou způsobu, jakým jsou záznamy uloženy. Databáze třídí řádky podle sloupce, který je nastaven jako clusterovaný index.
Neklastrovaný index nemění způsob, jakým byl uložen, ale vytváří v tabulce úplný samostatný objekt. Po vyhledání ukazuje zpět na původní řádky tabulky.
30. Co je to Datawarehouse?
Datawarehouse je centrální úložiště dat z více zdrojů informací. Tato data jsou konsolidována, transformována a zpřístupněna pro těžbu a online zpracování. Skladová data obsahují podmnožinu dat nazývanou Data Marts.
31. Co je to Self-Join?
Vlastní připojení je nastaveno tak, aby bylo použito dotazu k porovnání se sebou samým. To se používá k porovnání hodnot ve sloupci s jinými hodnotami ve stejném sloupci ve stejné tabulce. ALIAS ES lze použít pro srovnání stejné tabulky.
32. Co je Cross-Join?
Křížové spojení definuje jako kartézský součin, kde počet řádků v první tabulce vynásobený počtem řádků ve druhé tabulce. Pokud předpokládejme, že se v křížovém spojení použije klauzule WHERE, bude dotaz fungovat jako INNER JOIN.
33. Co jsou to uživatelsky definované funkce?
Uživatelsky definované funkce jsou funkce napsané pro použití této logiky, kdykoli je to potřeba. Není nutné psát stejnou logiku několikrát. Místo toho lze funkci zavolat nebo spustit kdykoli je potřeba.
34. Jaké jsou všechny typy funkcí definovaných uživatelem?
Jsou tři typy uživatelsky definovaných funkcí.
- Skalární funkce.
- Inline Table hodnotné funkce.
- Funkce s více příkazy.
Skalární návratová jednotka, varianta definovaná návratovou klauzulí. Další dva typy vrátí tabulku jako návrat.
35. Co je to řazení?
Porovnání je definováno jako sada pravidel, která určují, jak lze znaková data třídit a porovnávat. To lze použít k porovnání znaků A a jiných jazyků a závisí také na šířce znaků.
Hodnotu ASCII lze použít k porovnání těchto znakových dat.
36. Jaké jsou různé typy citlivosti řazení?
Následují různé typy citlivosti řazení -.
- Rozlišení malých a velkých písmen – A a a a B a b.
- Citlivost na akcent.
- Kana Sensitivity – japonské znaky Kana.
- Citlivost na šířku – Jednobajtový znak a dvoubajtový znak.
37. Výhody a nevýhody uložené procedury?
Uloženou proceduru lze použít jako modulární programování – znamená vytvořit jednou, uložit a několikrát vyvolat, kdykoli je potřeba. To podporuje rychlejší provádění namísto provádění více dotazů. To snižuje provoz v síti a poskytuje lepší zabezpečení dat.
Nevýhodou je, že jej lze spouštět pouze v databázi a zabírá více paměti na databázovém serveru.
38. Co je zpracování online transakcí (OLTP)?
Online Transaction Processing (OLTP) spravuje aplikace založené na transakcích, které lze použít pro zadávání dat, získávání dat a zpracování dat. OLTP zjednodušuje a zefektivňuje správu dat. Na rozdíl od systémů OLAP je cílem systémů OLTP obsluhovat transakce v reálném čase.
Příklad – Bankovní transakce na denní bázi.
39. Co je CLAUSE?
Klauzule SQL je definována pro omezení sady výsledků poskytnutím podmínky dotazu. To obvykle odfiltruje některé řádky z celé sady záznamů.
Příklad – Dotaz, který má podmínku WHERE
Dotaz, který má podmínku HAVING.
40. Co je rekurzivní uložená procedura?
Uložená procedura, která sama volá, dokud nedosáhne nějaké okrajové podmínky. Tato rekurzivní funkce nebo procedura pomáhá programátorům použít stejnou sadu kódu kolikrát.
Otázky k pohovoru SQL pro více než 10 let zkušeností
41. Co jsou příkazy Union, minus a Interact?
Operátor UNION se používá ke spojení výsledků dvou tabulek a eliminuje duplicitní řádky z tabulek.
Operátor MINUS se používá k vrácení řádků z prvního dotazu, ale ne z druhého dotazu. Odpovídající záznamy prvního a druhého dotazu a další řádky z prvního dotazu se zobrazí jako sada výsledků.
Operátor INTERSECT se používá k vrácení řádků vrácených oběma dotazy.
42. Co je příkaz ALIAS?
Název ALIAS lze přiřadit tabulce nebo sloupci. Na tento alias lze odkazovat klauzule WHERE k identifikaci tabulky nebo sloupce.
Příklad-.
Select st.StudentID, Ex.Result from student st, Exam as Ex where st.studentID = Ex. StudentID
Zde st odkazuje na název aliasu pro tabulku studentů a Ex odkazuje na název aliasu pro tabulku zkoušek.
43. Jaký je rozdíl mezi příkazy TRUNCATE a DROP?
TRUNCATE odstraní všechny řádky z tabulky a nelze ji vrátit zpět. Příkaz DROP odstraní tabulku z databáze a operaci nelze vrátit zpět.
44. Co jsou agregační a skalární funkce?
Agregační funkce se používají k vyhodnocení matematického výpočtu a vrácení jednotlivých hodnot. To lze vypočítat ze sloupců v tabulce. Skalární funkce vracejí jednu hodnotu na základě vstupní hodnoty.
Příklad -.
Aggregate – max(), count – Vypočítáno s ohledem na numerické.
Skalární – UCASE(), NOW() – Vypočítáno s ohledem na řetězce.
45. Jak můžete vytvořit prázdnou tabulku z existující tabulky?
Příklad bude -.
Select * into studentcopy from student where 1=2
Zde kopírujeme tabulku studentů do jiné tabulky se stejnou strukturou bez zkopírovaných řádků.
46. Jak získat společné záznamy ze dvou tabulek?
Společnou sadu výsledků záznamů lze dosáhnout pomocí -.
Select studentID from student INTERSECT Select StudentID from Exam
47. Jak získat alternativní záznamy z tabulky?
Záznamy lze načíst pro lichá i sudá čísla řádků -.
Pro zobrazení sudých čísel-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
Pro zobrazení lichých čísel-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
from (Vyberte rowno, studentId od studenta) kde mod(rowno,2)=1.[/sql]
48. Jak vybrat jedinečné záznamy z tabulky?
Vyberte jedinečné záznamy z tabulky pomocí klíčového slova DISTINCT.
Select DISTINCT StudentID, StudentName from Student.
49. Jaký příkaz se používá k načtení prvních 5 znaků řetězce?
Existuje mnoho způsobů, jak načíst prvních 5 znaků řetězce -.
Select SUBSTRING(StudentName,1,5) as studentname from student
Select LEFT(Studentname,5) as studentname from student
50. Který operátor se používá v dotazu pro vyhledávání vzorů?
Operátor LIKE se používá pro porovnávání vzorů a lze jej použít jako -.
- % – Odpovídá nule nebo více znakům.
- _(Podtržítko) – Odpovídá přesně jednomu znaku.
Příklad -.
Select * from Student where studentname like 'a%'
Select * from Student where studentname like 'ami_'
Tyto otázky na pohovoru také pomohou ve vašem životě (ústních)