Python RegEx: re.match(), re.search(), re.findall() s příkladem
⚡ Chytré shrnutí
Python Tutoriál o regulárních výrazech zahrnuje funkce re.match, research, re.findall a re.split na praktických příkladech. LessVysvětlují metaznaky, třídy znaků, skupiny, příznaky, substituci a běžné vzory pro analýzu a validaci textu.

V čem je regulární výraz Python?
A regulární výraz (RE) V programovacím jazyce je speciální textový řetězec používaný k popisu vyhledávacího vzoru. Je extrémně užitečný např.traczískávání informací z textu, jako je kód, soubory, protokoly, tabulky nebo dokonce dokumenty.
Při používání Python regulární výraz, první věcí je uznat, že vše je v podstatě znak a my píšeme vzory, které odpovídají specifické posloupnosti znaků, také nazývané řetězec. Ascii nebo latinská písmena jsou ta, která jsou na vašich klávesnicích a pro shodu s cizím textem se používá Unicode. Obsahuje číslice a interpunkci a všechny speciální znaky jako $#@!% atd.
Například: Python regulární výraz by mohl říci programu, aby vyhledal konkrétní text z řetězce a poté podle toho vytiskl výsledek. Výraz může zahrnovat
- Shoda textu
- Opakování
- Rozvětvení
- Složení vzoru atd.
Regulární výraz nebo RegEx in Python se označuje jako RE (RE, regulární výrazy nebo vzor regulárních výrazů) jsou importovány prostřednictvím re modul. Python podporuje regulární výraz prostřednictvím knihoven. RegEx v Python podporuje různé věci jako Modifikátory, identifikátory a prázdné znaky.
| Identifikátory | Modifikátory | Prázdné znaky | Je vyžadován únik |
|---|---|---|---|
| \d= libovolné číslo (číslice) | \d představuje číslici. Příklad: \d{1,5} bude deklarovat číslici mezi 1,5 jako 424,444,545 atd. | \n = nový řádek | . + * ? [] $ ^ () {} | \ |
| \D= cokoliv kromě čísla (nečíslice) | + = odpovídá 1 nebo více | \s= mezera | |
| \s = mezera (tabulátor, mezera, nový řádek atd.) |
? = odpovídá 0 nebo 1 | \t =tab | |
| \S= cokoliv kromě mezery | * = 0 nebo více | \e = útěk | |
| \w = písmena (shoda alfanumerických znaků, včetně „_“) | $ odpovídá konci řetězce | \r = návrat vozíku | |
| \W =cokoli kromě písmen (odpovídá nealfanumerickým znakům kromě „_“) | ^ odpovídat začátku řetězce | \f= zdroj formuláře | |
| . = cokoliv kromě písmen (teček) | | odpovídá buď nebo x/y | ------ | |
| \b = libovolný znak kromě nového řádku | [] = rozsah nebo „rozptyl“ | ------ | |
| \. | {x} = toto množství předchozího kódu | ------ |
Syntaxe regulárních výrazů (RE).
import re
- Modul „re“ je součástí dodávky Python primárně se používá pro vyhledávání řetězců a manipulaci
- Často se také používá pro webovou stránku “Jizvaping„(např.tracvelké množství dat z webových stránek)
Výukový program výrazů začneme tímto jednoduchým cvičením s použitím výrazů (w+) a (^).
Příklad výrazu w+ a ^
- "^": Tento výraz odpovídá začátku řetězce
- „w+“: Tento výraz se shoduje s alfanumerickým znakem v řetězci
Zde uvidíme a Python RegEx Příklad toho, jak můžeme v našem kódu použít výrazy w+ a ^. Pokrýváme funkci re.findall() in Python, později v tomto tutoriálu, ale na chvíli se jednoduše zaměříme na výraz \w+ a \^.
Například pro náš řetězec „guru99, vzdělání je zábava“, pokud spustíme kód pomocí w+ a^, dostane výstup „guru99“.
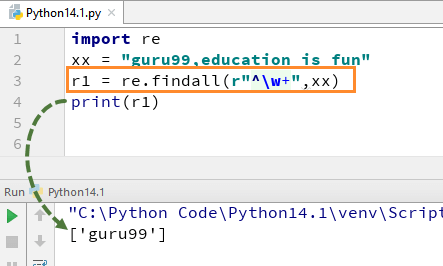
import re xx = "guru99,education ">is fun" r1 = re.findall(r"^\w+",xx) print(r1)
Pamatujte, že pokud odstraníte znaménko + z w+, výstup se změní a bude dávat pouze první znak prvního písmene, tj. [g]
Příklad výrazu \s ve funkci re.split
- „s“: Tento výraz se používá pro vytvoření mezery v řetězci
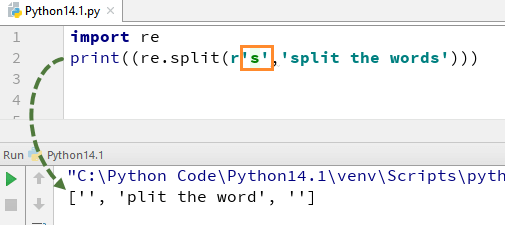
Abychom pochopili, jak je tento RegEx v Python funguje, začneme jednoduchým Python RegEx Příklad funkce rozdělení. V příkladu jsme rozdělili každé slovo pomocí funkce „re.split“ a zároveň jsme použili výraz \s, který umožňuje analyzovat každé slovo v řetězci samostatně.

Když spustíte tento kód, poskytne vám výstup ['we', 'are', 'splitting', 'the', 'words'].
Nyní se podívejme, co se stane, když odstraníte „\“ z s. Ve výstupu není žádná abeceda 's', je to proto, že jsme z řetězce odstranili '\' a vyhodnotí to „s“ jako běžný znak a rozdělí tak slova všude tam, kde v řetězci najde „s“.
Podobně existují řady dalších Python regulární výraz, který můžete použít různými způsoby Python jako \d,\D,$,\.,\b atd.
Zde je úplný kód
import re xx = "guru99,education ">is fun" r1 = re.findall(r"^\w+", xx) print((re.split(r'\s','we are splitting the words'))) print((re.split(r's','split the words')))
Dále uvidíme typy metod, které se používají s regulárním výrazem Python.
Použití metod regulárních výrazů
Balíček „re“ poskytuje několik metod, jak skutečně provádět dotazy na vstupní řetězec. Uvidíme metody re in Python:
- odveta()
- výzkum()
- re.findall()
Hodnocení: Na základě regulárních výrazů Python nabízí dvě různé primitivní operace. Metoda match kontroluje shodu pouze na začátku řetězce, zatímco vyhledávání kontroluje shodu kdekoli v řetězci.
odveta()
odveta() funkce re in Python prohledá vzor regulárního výrazu a vrátí první výskyt. The Python Metoda RegEx Match kontroluje shodu pouze na začátku řetězce. Pokud je tedy nalezena shoda v prvním řádku, vrátí objekt shody. Ale pokud je nalezena shoda v nějakém jiném řádku, Python Funkce RegEx Match vrátí hodnotu null.
Zvažte například následující kód Python funkce re.match(). Výrazy „w+“ a „\W“ budou odpovídat slovům začínajícím písmenem „g“ a poté cokoli, co nezačíná písmenem „g“, není identifikováno. Abychom zkontrolovali shodu pro každý prvek v seznamu nebo řetězci, spustíme v tomto forloop Python re.match() Příklad.

re.search(): Hledání vzoru v textu
výzkum() funkce prohledá vzor regulárního výrazu a vrátí první výskyt. Na rozdíl od Python re.match(), zkontroluje všechny řádky vstupního řetězce. The Python Funkce re.search() vrací odpovídající objekt, když je vzor nalezen, a „null“, pokud vzor nebyl nalezen
Jak používat search()?
Chcete-li použít funkci search(), musíte provést import Python nejprve modul re a poté spusťte kód. The Python Funkce re.search() přebírá „vzor“ a „text“ ke skenování z našeho hlavního řetězce
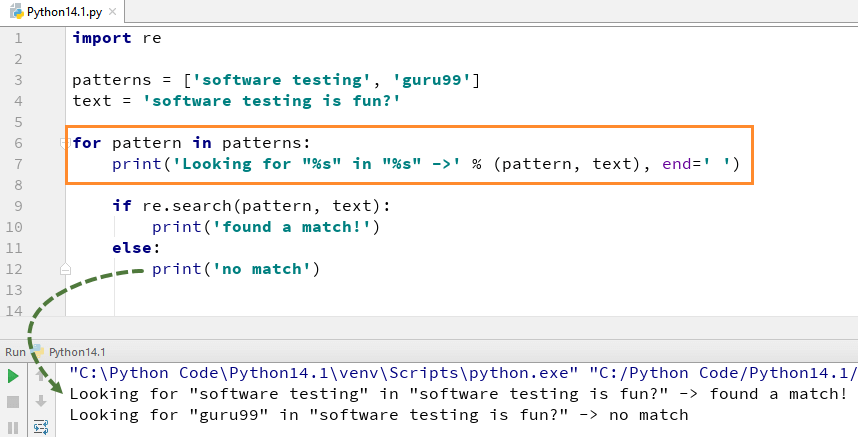
Například zde hledáme dva doslovné řetězce „Testování softwaru“ „guru99“, v textovém řetězci „Software Testování je zábava“. Pro „testování softwaru“ jsme našli shodu, a proto vrací výstup Python re.search() Příklad jako „nalezena shoda“, zatímco pro slovo „guru99“ jsme v řetězci nenašli, a proto vrací výstup jako „Žádná shoda“.
re.findall()
findall() Modul se používá k vyhledávání „všech“ výskytů, které odpovídají danému vzoru. Naproti tomu modul search() vrátí pouze první výskyt, který odpovídá zadanému vzoru. Funkce findall() projde všechny řádky souboru a vrátí všechny nepřekrývající se řádky.ping shody vzorů v jednom kroku.
Jak používat re.findall() in Python?
Zde máme seznam e-mailových adres a chceme, aby byly všechny e-mailové adresy načteny ze seznamu, použijeme metodu re.findall() v Python. Najde všechny e-mailové adresy ze seznamu.
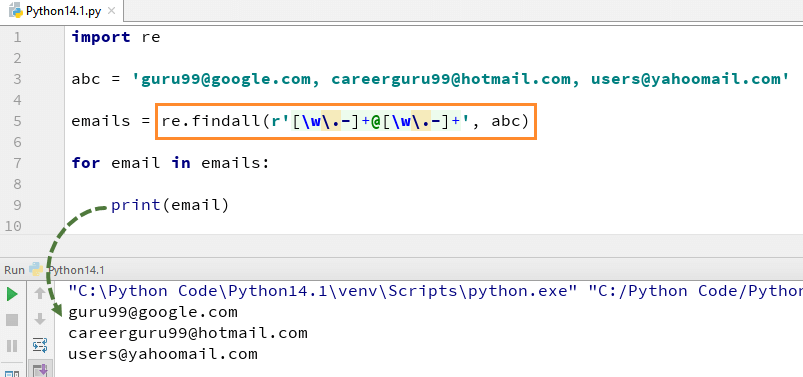
Zde je úplný kód pro příklad re.findall()
import re list = ["guru99 get", "guru99 give", "guru Selenium"] for element in list: z = re.match("(g\w+)\W(g\w+)", element) if z: print((z.groups())) patterns = ['software testing', 'guru99'] text = 'software testing is fun?' for pattern in patterns: print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ') if re.search(pattern, text): print('found a match!') else: print('no match') abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com' emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc) for email in emails: print(email)
Python Vlajky
Mnoho Python Metody regulárního výrazu a funkce regulárního výrazu přebírají volitelný argument nazvaný příznaky. Tyto příznaky mohou změnit význam daného Python Vzor regulárního výrazu. Abychom jim porozuměli, uvidíme jeden nebo dva příklady těchto příznaků.
Používají se různé vlajky Python zahrnuje
| Syntaxe pro Regex Flags | Co dělá tato vlajka |
|---|---|
| [re.M] | Začátek/konec zvažte každý řádek |
| [re.I] | Ignoruje případ |
| [re.S] | Udělat [ . ] |
| [re.U] | Make { \w,\W,\b,\B} se řídí pravidly Unicode |
| [re.L] | Nastavte {\w,\W,\b,\B} podle národního prostředí |
| [re.X] | Povolit komentář v regulárním výrazu |
Příklad příznaků re.M nebo Multiline Flags
Ve víceřádcích se znak vzoru [^] shoduje s prvním znakem řetězce a začátkem každého řádku (následuje bezprostředně po každém novém řádku). Zatímco výraz malé „w“ se používá k označení mezery pomocí znaků. Když spustíte kód, první proměnná „k1“ vytiskne pouze znak „g“ pro slovo guru99, zatímco když přidáte víceřádkový příznak, načte první znaky všech prvků v řetězci.
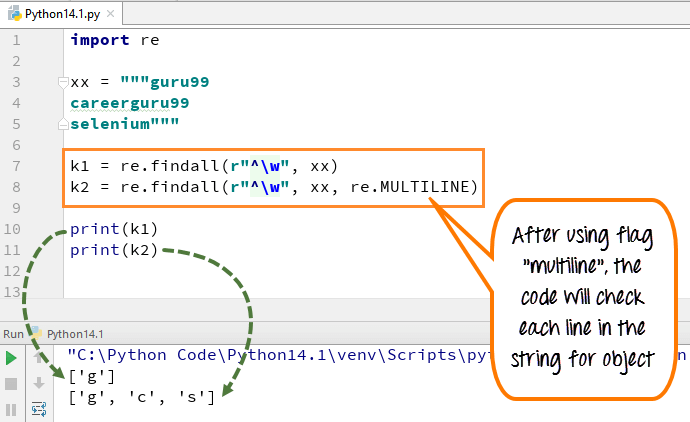
Zde je kód
import re xx = """guru99 careerguru99 selenium""" k1 = re.findall(r"^\w", xx) k2 = re.findall(r"^\w", xx, re.MULTILINE) print(k1) print(k2)
- Deklarovali jsme proměnnou xx pro řetězec ” guru99…. kariéra99….selen“
- Spusťte kód bez použití příznaků multiline, dává výstup pouze 'g' z řádků
- Spusťte kód s příznakem „multiline“, když vytisknete 'k2', dává výstup jako 'g', 'c' a 's'
- Rozdíl tedy můžeme vidět po a před přidáním více řádků ve výše uvedeném příkladu.
Stejně tak můžete použít i jiné Python příznaky jako re.U (Unicode), re.L (Sledovat národní prostředí), re.X (Povolit komentář) atd.
Python 2 Příklad
Výše uvedené kódy jsou Python 3 příklady, pokud se chcete zapojit Python 2 prosím zvažte následující kód.
# Example of w+ and ^ Expression import re xx = "guru99,education ">is fun" r1 = re.findall(r"^\w+",xx) print r1 # Example of \s expression in re.split function import re xx = "guru99,education ">is fun" r1 = re.findall(r"^\w+", xx) print (re.split(r'\s','we are splitting the words')) print (re.split(r's','split the words')) # Using re.findall for text import re list = ["guru99 get", "guru99 give", "guru Selenium"] for element in list: z = re.match("(g\w+)\W(g\w+)", element) if z: print(z.groups()) patterns = ['software testing', 'guru99'] text = 'software testing is fun?' for pattern in patterns: print 'Looking for "%s" in "%s" ->' % (pattern, text), if re.search(pattern, text): print 'found a match!' else: print 'no match' abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com' emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc) for email in emails: print email # Example of re.M or Multiline Flags import re xx = """guru99 careerguru99 selenium""" k1 = re.findall(r"^\w", xx) k2 = re.findall(r"^\w", xx, re.MULTILINE) print k1 print k2
Otestujte si svůj Python vědomosti
1. Která metoda se používá k nalezení všech výskytů vzoru v řetězci?
- výzkum()
- odveta()
- re.findall()
- re.split()
2. Co představuje třída znaků \d v regulárních výrazech?
- Libovolná číslice (0-9)
- Libovolný nečíslicový znak
- Jakýkoli znak mezery
- Jakékoli písmeno nebo číslo
3. Kterou funkci byste použili k rozdělení řetězce na základě mezer?
- re.split(r'\s', řetězec)
- re.findall(r'\w+', řetězec)
- re.match(r'\s+', řetězec)
- re.split(r'\w+', řetězec)
4. Jaký je hlavní rozdíl mezi re.match() a re.search()?
- re.match() hledá vzor na začátku řetězce, zatímco re.search() hledá vzor kdekoli v řetězci.
- re.match() vrátí všechny shody, zatímco re.search() vrátí první shodu.
- re.search() je rychlejší než re.match().
- Obě funkce se chovají stejně.