Fáze kompilátoru s příkladem, postupem a kroky
⚡ Chytré shrnutí
Fáze kompilátoru popisují, jak kompilátor transformuje zdrojový kód do strojového kódu prostřednictvím šesti fází: lexikální analýza, syntaktická analýza, sémantická analýza, generování mezikódu, optimalizace kódu a generování kódu, s podporou správy tabulek symbolů a ošetření chyb v celém procesu.

Jaké jsou fáze návrhu kompilátoru?
překladač pracuje v různých fázích, každá fáze transformuje zdrojový program z jedné reprezentace do druhé. Každá fáze přebírá vstupy ze své předchozí fáze a dodává svůj výstup do další fáze kompilátoru.
V kompilátoru je 6 fází. Každá z těchto fází pomáhá při převodu jazyka vysoké úrovně na strojový kód. Fáze kompilátoru jsou:
- Lexikální analýza
- Syntaktická analýza
- Sémantická analýza
- Mezilehlý generátor kódu
- Code optimalizátor
- Code generátor
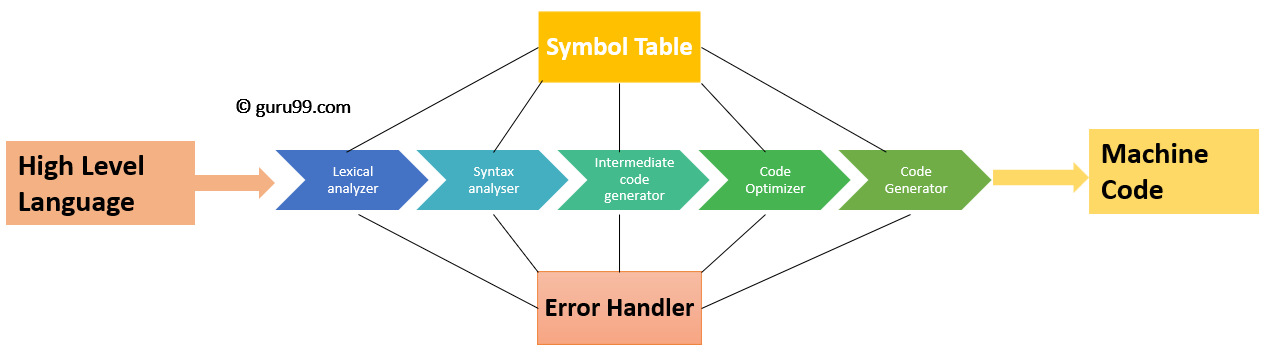
Všechny tyto fáze převádějí zdrojový kód rozdělením do tokenů, vytvářením stromů analýzy a optimalizací zdrojového kódu podle různých fází.
Fáze 1: Lexikální analýza
Lexikální analýza je první fází, kdy kompilátor skenuje zdrojový kód. Tento proces lze zleva doprava, znak po znaku, a seskupovat tyto znaky do žetonů.
Zde je proud znaků ze zdrojového programu seskupen do smysluplných sekvencí pomocí identifikace tokenů. Provede zápis odpovídajících tipů do tabulky symbolů a předá tento token do další fáze.
Primární funkce této fáze jsou:
- Identifikujte lexikální jednotky ve zdrojovém kódu
- Klasifikujte lexikální jednotky do tříd, jako jsou konstanty, vyhrazená slova, a zadejte je do různých tabulek. Bude ignorovat komentáře ve zdrojovém programu
- Identifikujte token, který není součástí jazyka
Příklad:
x = y + 10
žetony
| X | identifikátor |
| = | Operátor přiřazení |
| Y | identifikátor |
| + | Operátor sčítání |
| 10 | Číslo |
Fáze 2: Analýza syntaxe
Analýza syntaxe je o objevování struktury v kódu. Určuje, zda text odpovídá očekávanému formátu. Hlavním cílem této fáze je ujistit se, že zdrojový kód napsaný programátorem je správný nebo ne.
Syntaktická analýza je založena na pravidlech vycházejících z konkrétního programovacího jazyka pomocí konstrukce stromu analýzy pomocí tokenů. Určuje také strukturu zdrojového jazyka a gramatiku nebo syntaxi jazyka.
Zde je seznam úkolů provedených v této fázi:
- Získejte tokeny z lexikálního analyzátoru
- Zkontroluje, zda je výraz syntakticky správný nebo ne
- Nahlásit všechny syntaktické chyby
- Vytvořte hierarchickou strukturu, která je známá jako strom analýzy
Příklad
Jakýkoli identifikátor/číslo je výraz
Jestliže x je identifikátor a y+10 je výraz, pak x= y+10 je příkaz.
Zvažte strom analýzy pro následující příklad
(a+b)*c
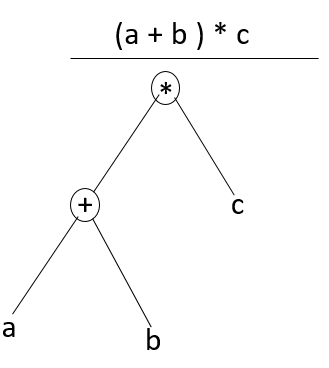
V Parse Tree
- Vnitřní uzel: záznam u operátora a dva soubory pro děti
- List: záznamy se 2/více poli; jeden pro token a další informace o tokenu
- Ujistěte se, že komponenty programu do sebe smysluplně zapadají
- Shromažďuje informace o typech a kontroluje kompatibilitu typů
- Kontrolní operandy jsou povoleny zdrojovým jazykem
Fáze 3: Sémantická analýza
Sémantická analýza kontroluje sémantickou konzistenci kódu. K ověření, zda je daný zdrojový kód sémanticky konzistentní, používá syntaktický strom předchozí fáze spolu s tabulkou symbolů. Kontroluje také, zda kód vyjadřuje vhodný význam.
Sémantický analyzátor zkontroluje neshody typu, nekompatibilní operandy, funkci volanou s nesprávnými argumenty, nedeklarovanou proměnnou atd.
Funkce fáze sémantické analýzy jsou:
- Pomáhá vám ukládat shromážděné informace o typu a ukládat je do tabulky symbolů nebo stromu syntaxe
- Umožňuje provádět kontrolu typu
- V případě neshody typu, kde neexistují žádná přesná pravidla pro opravu typu, která splňují požadovanou operaci, se zobrazí sémantická chyba
- Shromažďuje informace o typech a kontroluje kompatibilitu typů
- Zkontroluje, zda zdrojový jazyk povoluje operandy nebo ne
Příklad
float x = 20.2; float y = x*30;
Ve výše uvedeném kódu sémantický analyzátor přetypuje celé číslo 30 na plovoucí 30.0 před násobením
Fáze 4: Střední Code Generace
Jakmile je fáze sémantické analýzy ukončena, kompilátor generuje mezikód pro cílový počítač. Ten představuje program pro nějaké abs...tracstroj.
Mezilehlý kód je mezi jazykem vysoké úrovně a jazykem na úrovni stroje. Tento mezikód musí být generován takovým způsobem, aby bylo snadné jej přeložit do cílového strojového kódu.
Funkce na středně pokročilém Code generace:
- Měl by být generován ze sémantické reprezentace zdrojového programu
- Obsahuje hodnoty vypočítané během procesu překladu
- Pomáhá vám přeložit přechodný kód do cílového jazyka
- Umožňuje zachovat pořadí priority zdrojového jazyka
- Obsahuje správný počet operandů instrukce
Příklad
Například,
total = count + rate * 5
Mezilehlý kód s pomocí metody kódu adresy je:
t1 := int_to_float(5)
t2 := rate * t1
t3 := count + t2
total := t3
Fáze 5: Code Optimalizace
Další fází je optimalizace kódu neboli Intermediate code. Tato fáze odstraní zbytečný řádek kódu a uspořádá posloupnost příkazů tak, aby se urychlilo provádění programu bez plýtvání zdroji. Hlavním cílem této fáze je zlepšit přechodný kód, aby se vygeneroval kód, který běží rychleji a zabírá méně místa.
Primární funkce této fáze jsou:
- Pomůže vám vytvořit kompromis mezi rychlostí provádění a kompilace
- Zlepšuje dobu běhu cílového programu
- Generuje zjednodušený kód stále ve střední reprezentaci
- Odstranění nedostupného kódu a zbavení se nepoužívaných proměnných
- Odstranění příkazů, které nejsou změněny, ze smyčky
Příklad:
Zvažte následující kód
a = intofloat(10)
b = c * a
d = e + b
f = d
Může se stát
b =c * 10.0 f = e+b
Fáze 6: Code Generace
Code Generování je poslední a závěrečná fáze kompilátoru. Získává vstupy z fází optimalizace kódu a jako výsledek vytváří kód stránky nebo objektový kód. Cílem této fáze je alokovat úložiště a generovat přemístitelný strojový kód.
Také přiděluje paměťová místa pro proměnnou. Instrukce v mezikódu jsou převedeny na strojové instrukce. Tato fáze překrývá optimalizační nebo přechodný kód do cílového jazyka.
Cílovým jazykem je strojový kód. Proto jsou během této fáze také vybrána a přidělena všechna paměťová místa a registry. Kód generovaný touto fází se provádí tak, aby přijal vstupy a generoval očekávané výstupy.
Příklad
a = b + 60.0
Mohl by být přeložen do registrů.
MOVF a, R1 MULF #60.0, R2 ADDF R1, R2
Správa tabulky symbolů
Tabulka symbolů obsahuje záznam pro každý identifikátor s poli pro atributy identifikátoru. Tato komponenta usnadňuje kompilátoru vyhledání záznamu identifikátoru a jeho rychlé načtení. Tabulka symbolů vám také pomůže se správou rozsahu. Tabulka symbolů a obsluha chyb spolupracují se všemi fázemi a tabulka symbolů se odpovídajícím způsobem aktualizuje.
Rutina zpracování chyb
V procesu návrhu kompilátoru může dojít k chybě ve všech níže uvedených fázích:
- Lexikální analyzátor: Špatně napsané tokeny
- Analyzátor syntaxe: Chybějící závorka
- Generátor mezilehlého kódu: Neshodné operandy pro operátora
- Code Optimalizátor: Když příkaz není dosažitelný
- Code Generator: Když je paměť plná nebo nejsou přiděleny správné registry
- Tabulky symbolů: Chyba více deklarovaných identifikátorů
Nejčastějšími chybami jsou neplatná sekvence znaků při skenování, neplatné sekvence tokenů v typu, chyba rozsahu a analýza v sémantické analýze.
K chybě může dojít v kterékoli z výše uvedených fází. Po nalezení chyb se fáze musí s chybami vypořádat, aby mohla pokračovat v procesu kompilace. Tyto chyby je třeba nahlásit obsluze chyb, která chybu zpracovává, aby mohl provést proces kompilace. Obecně jsou chyby hlášeny ve formě zprávy.